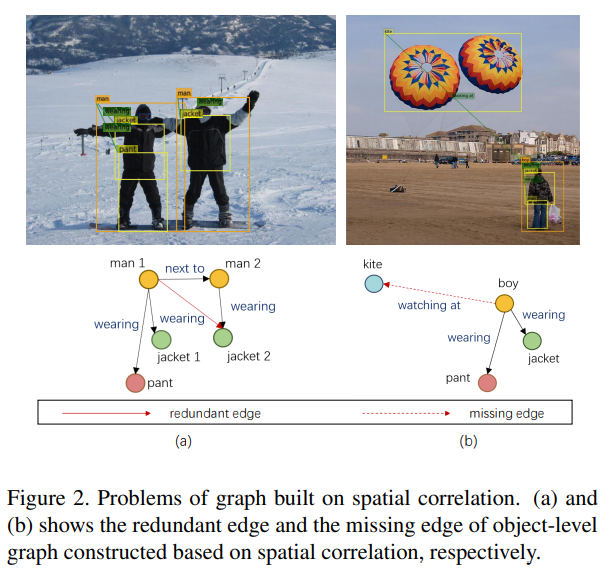
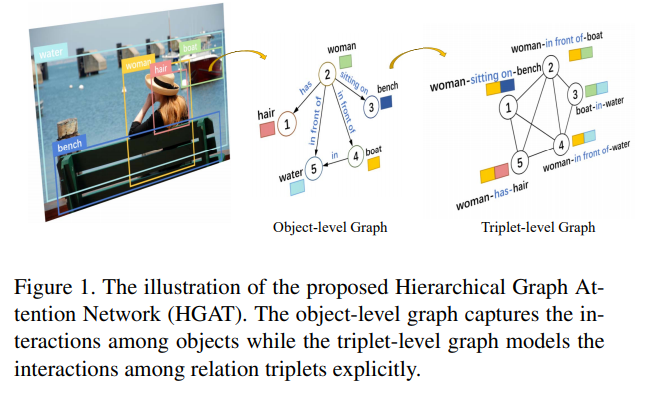
2020-12-17 update
MoCo,SimCLR,MoCo v2,SimCLR v2,SwAV,BYOL,SimSiam
自监督学习
现在的自监督方法主要分为如下两类:生成方法和对比方法。
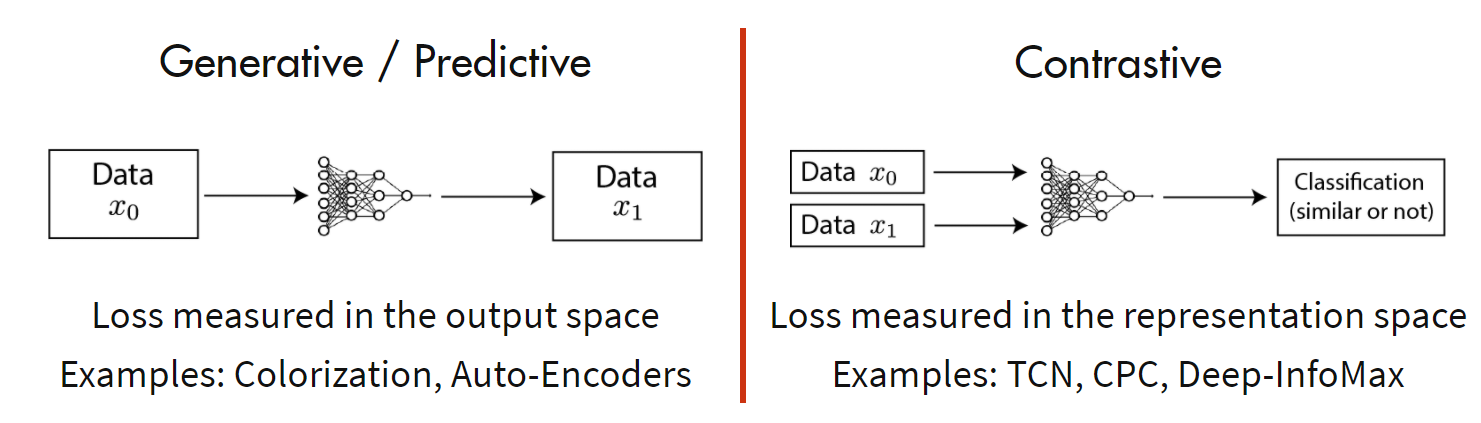
其中生成方法专注于像素空间的特征,使用像素级的损失可能导致此类方法过于关注像素级的细节,而不是抽象的语义信息,且基于像素的方法通常假设每个像素之间相互独立,难以有效建立空间关联及对象的复杂结构;而对比方法通过对比正样本和负样本来学习潜在空间地表征,利用该表征去完成下游任务。
具体来说,对于任意数据点,对比方法的目的是学习一个编码器使得:
其中,是的正样本,是的负样本,函数评估两个特征之间的相似度。
所以对于一个锚点数据,对比学习通过构建一个softmax分类器正确地对正样本和负样本进行分类,同时函数鼓励正对之间具有较大的相似性,而负对之间有较小的相似性,采用交叉熵损失,故对于一对正对,其对比学习的损失函数InfoNCE的一般形式为:
其中,是温度系数超参数,上式表明包含一个正对和个负对,最小化InfoNCE也可以解释为最大化和之间的互信息下界,即代表知道之后,的信息量减少的程度。