动机
- 在图像生成任务上,
GAN拥有目前最先进的能力,但研究表明GAN相比likelihood-based models捕捉的多样性更少,且训练难度更大,容易模式崩塌;
- 现在的扩散模型效果跟
GAN有一定差距,作者假设之间的GAP至少来自两个方面:1)GAN的模型结构探索更充分;2)GAN在多样性和保真度之间平衡较好,能够产生高质量的图像但不能覆盖整个分布;
- 本文目的则希望改进模型结构,并设计一个方案权衡多样性和保真度,提高扩散模型的能力。
贡献
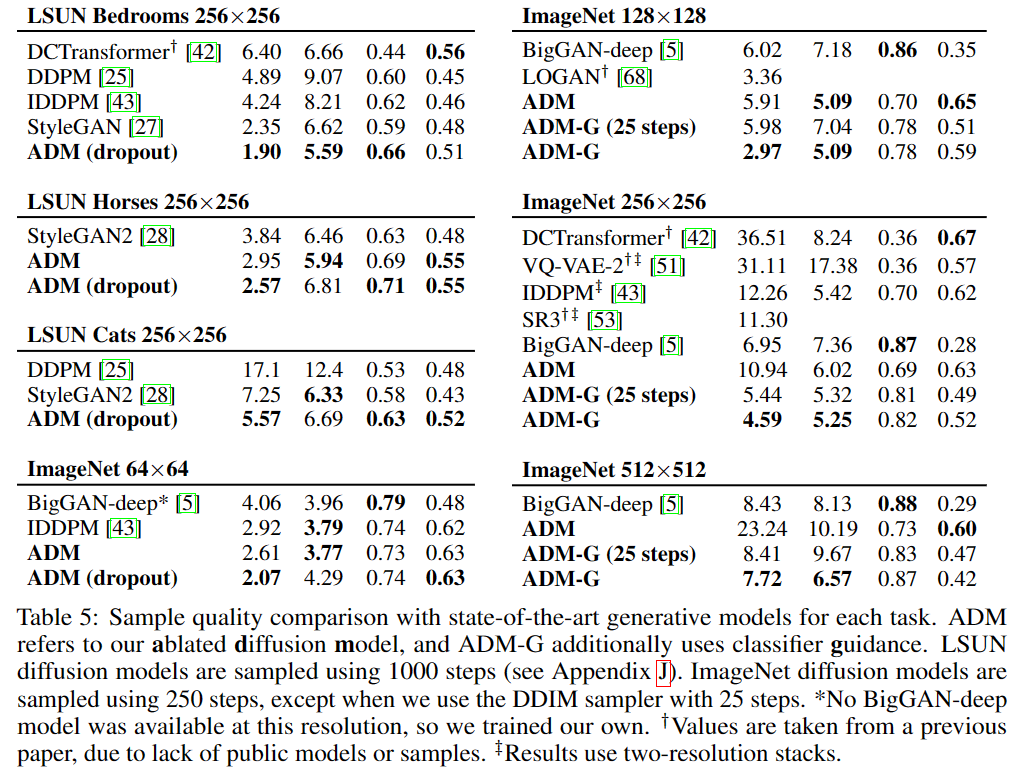
- 本文证明扩散模型可以实现目前最先进的图像生成质量:在无条件图像生成任务,通过一系列消融实验寻找到更好的网络结构;在有条件图像生成任务,利用分类器的梯度引导进一步提升样本质量。
本文的方法
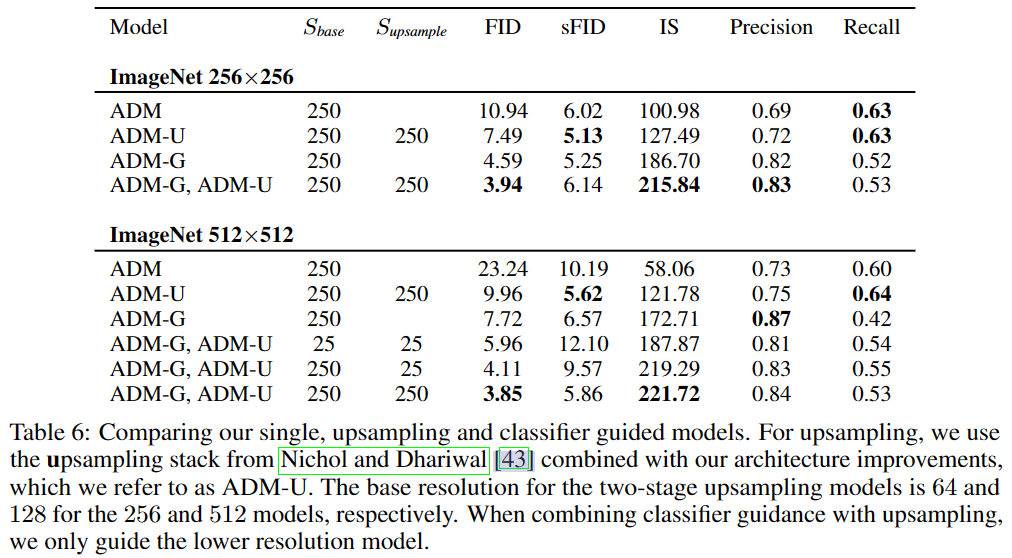
本文使用Improved DDPM和DDIM的改进方法。即Improved DDPM将固定的方差也变为一个神经网络预测、且损失计算时使用;DDIM使用非马尔可夫链加噪过程,允许通过改变方向过程中噪声的方差来产生不同的反向采样器,当设置噪声为时,则允许直接将任意模型转换为从latent映射为image。使用混合目标学习反向过程的方差、以及DDIM提供的采样方法,可以用更少的步骤进行采样,而不降低样本质量。
Architecture Improvements
在UNet的基础上进行如下改变:
- 增加网络深度,同时减少模型宽度,以保持模型尺寸恒定(但增加训练时间,后续不使用);
- 增加注意力头的数量;
- 在分辨率均使用注意力机制而不是只使用;
- 在上采样和下采样时参照
Score-Based Generative Modeling through Stochastic Differential Equations使用BigGAN的残差模块;
- 参照
StyleGAN等在残差连接时使用的缩放;
- 使用
adaptive group normalization代替addition + group normalization。
adaptive group normalization(AdaGN)表示在GN后将timestep embedding和class embedding嵌入到每个残差块中,公式为:
其中,为第一个卷积后的残差块的激活,为timestep embedding和class embedding经过线性映射得到。
最终的模型结构为:每个分辨率下有两个可变宽度的残差块,多抽头且每个头的通道数为,在分辨率为时进行注意力,上采样和下采样时使用BigGAN残差块,以及AdaGN将timestep embedding和class embedding嵌入到残差块中。
Classifier Guidance
预训练的扩散模型可以使用分类器的梯度进行调节,即使用有噪图像训练分类器,并使用梯度引导扩散采样过程朝向任意的类别。
Conditional Reverse Noising Process
本文证明在已知标签的条件采样,等价于从采样,其中为常数,可近似为带扰动的高斯分布,证明如下:
对在时进行泰勒展开,有:
其中,,则有:
因此,条件转换算子可以近似为一个类似于无条件转换算子的高斯函数,但其均值有的偏移,算法如下图所示:

Conditional Sampling for DDIM
在DDIM中,本文利用diffusion models和score matching的联系。当模型预测采样的噪声,则计算score function得到:
则新的score function可以表示为:
定义一个新的预测函数表示联合分布的score,则:
因此,可以使用DDIM相同的采样流程,仅将噪声预测函数修改为$\hat{\epsilon}\left(x_t\right)$,算法如下图所示:

Scaling Classifier Gradients

在无条件扩散模型中,发现有必要设置分类器的梯度的因子大于。如上图所示,当,分类器为样本在期望类上分配的概率较低,而增大scale时,则分类概率增加,且FID显著下降。
通过转换,,条件调节过程理论上可以看成是跟re-normalized classifier distribution有关。当时,相比分布更尖锐,即较大的值会被指数放大,即可以更关注分类器对应的模式,获得更具有保真度的图像。
在无条件的扩散模型中,也可以使用classifier guidance,如下图所示,guided unconditional model的结果接近unguided conditonal model。
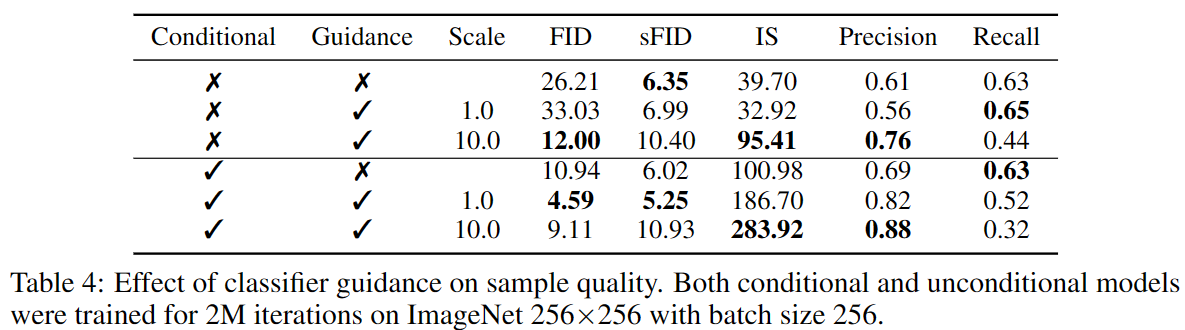
部分实验结果