动机
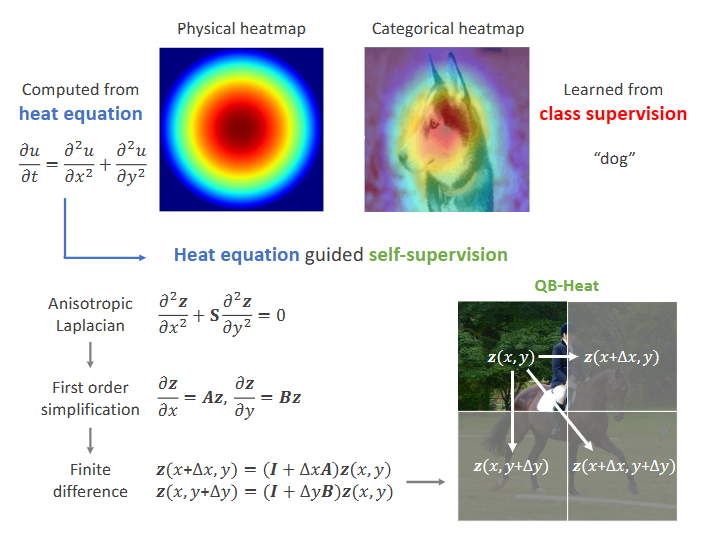
CAM表明全局平均池化后的CNN能够学习categorical heatmap,类似于物理热扩散方程,这提供了一种自监督方法,即用热方程而不是类标签来指导表征学习。
贡献
- 提出一种新的自监督学习方法
Quarter-Block prediction guided by Heat equation (QB-Heat),该方法基于热方程并扩展到高维特征空间,简化后的方法在水平和垂直方向分别建模空间不变性,支持跨图像块的预测;
QB-Heat将四分之一的图像unmasked,并线性外推其它区域,实现在CNN可简单进行masked image modeling任务,并获得良好的性能;- 为不同形状和纹理的视觉表征的不变性提供了一个假设:水平方向和垂直方向偏导之间的线性关系。
本文的方法
Heat Equation in Feature Space
受CAM启发发现categorical heatmap类似于物理热扩散方程,作者假设:1)视觉目标周围的特征图是平滑的,且受热方程控制;2)对应的特征编码器可以单独从热方程学习,而不需要标签。热方程形式如下:
即温度随时间的变化跟温度在二维空间的变化有关。从而提供了一种新的自监督学习视角,即使用热方程而不是类标签来指导表征学习。
本文扩展热方程基于几点原则:1)多特征通道的热扩散是相关的;2)水平和垂直方向的热扩散是不等效的。基于此,本文从标量扩展到隐向量,其并添加稳态条件以消除时间依赖性,扩展为各向异性拉普拉斯算子:
其中,是通道为的特征图,即。为的系数矩阵,一方面处理水平方向和垂直方向上的非等价变化,另一方面编码隐特征表征空间中沿轴和轴的二阶导数之间的不变关系。对和轴分离,转换为两个一阶线性微分方程:
其中,为可逆矩阵,且。上述简化可以保持在和任意阶导数的线性关系,即:
并且通过离散化,可以通过差分去估计水平和垂直方向的特征:
连续形式和离散形式的公式均存在崩塌解,即特征图均为常数,和为。
QB-Heat
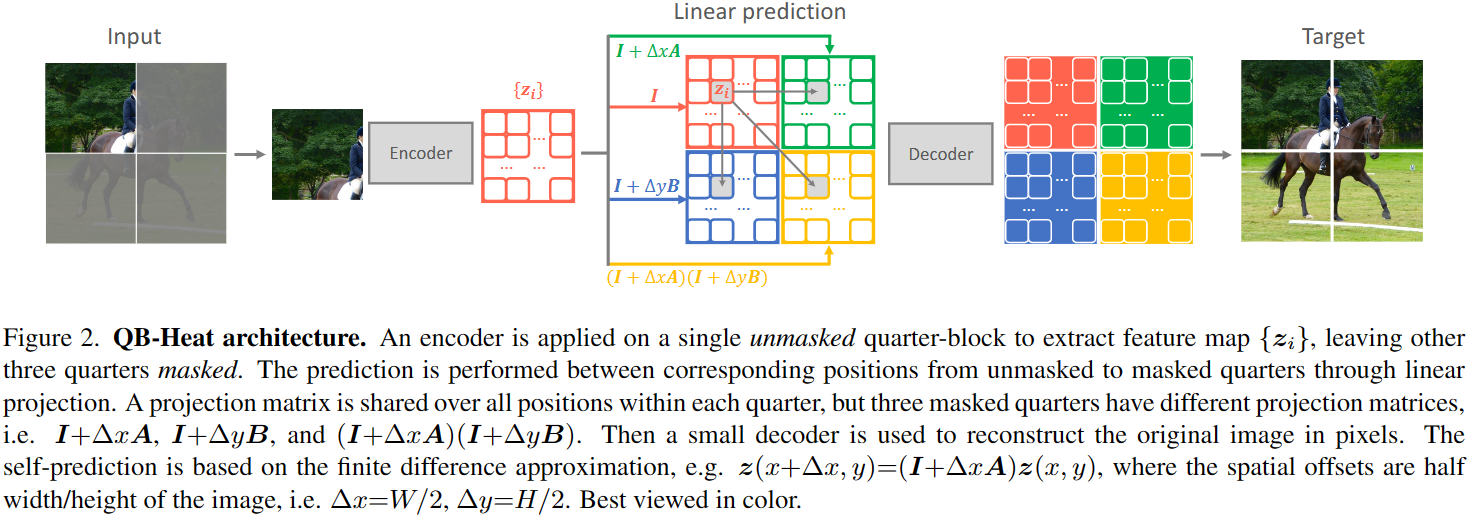
其网络结构如上图所示,具体实现时,将一个unmasked quarter-block编码得到,再通过线性预测获得,学习参数包括编码器和矩阵,每个被mask的quarter-block都有一个线性模型(由卷积构成),参数由quarter-block的所有元素共享。QB-Heat不仅能够防止模式崩塌,而且避免了CNN无法随机mask的问题,在实验中主要需要调整两部分:1)unmasked quarter-block的位置;2)显式线性模型的数量。
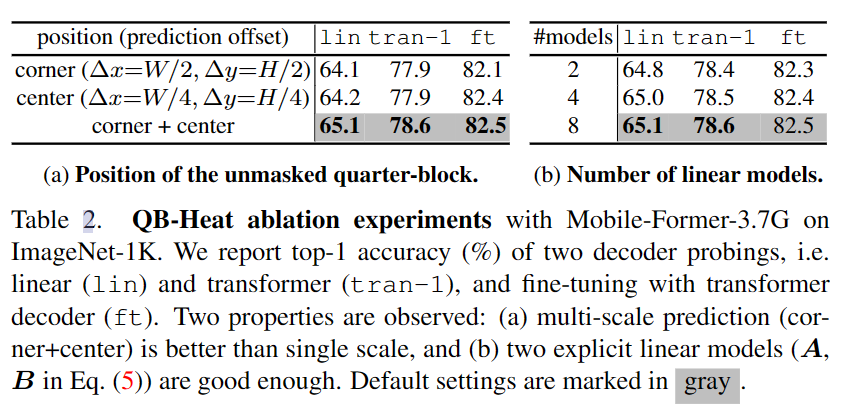
Position of unmasked quarter-block:如图所示,unmasked quarter-block的位置在中间或者四个角落,对应着不同的预测偏移量,实验发现在一个batch中混合corner和center位置的效果最好。

Number of explicit linear models:如图所示,实线箭头表示显式的线性模型预测,虚线箭头表示由显式模型推导得到,实验中数量对结果影响不大。
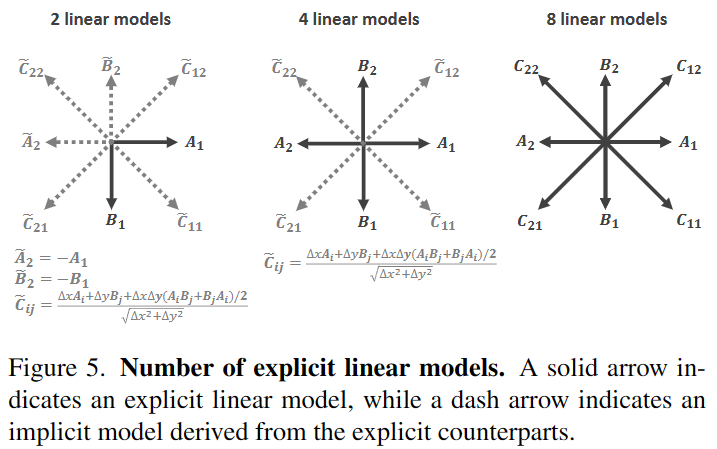
如上图所示,假设沿着和轴的两个显式模型为和,则负方向的和可以通过差分公式获得:
而对角方向的也可以通过差分公式获得:
同理,有:
则有:
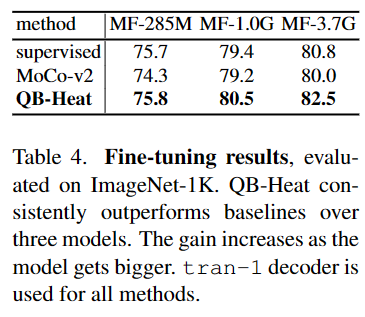
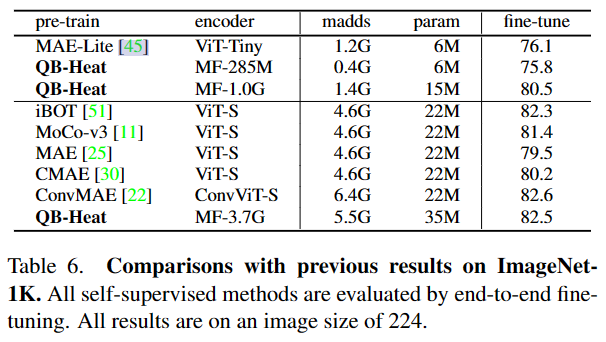
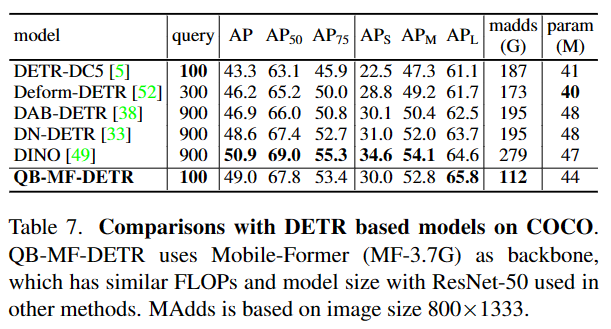
部分实验结果
相比MAE,有几点不同:1)更规则的mask;2)更简单的线性预测;3)简单地为CNN构建masked image modeling任务;4)通过可学习矩阵显式地在表示空间中建模空间不变性。所以相比MAE,QB-Heat可以使用更少的参数、更简单的复杂度,获得相似的效果。
此外,除了linear probing和finetuning,提出decoder probing,同时处理线性和非线性特征,且不需要重新finetuning并适合多个视觉任务。decoder probing使用冻结的预训练encoder在不同解码器上对不同任务上,添加decoder进行微调来间接评估,比如在分类任务上使用linear decoder或transformer decoder,在检测任务上使用两个DETR head和一个RetinaNet head。