动机
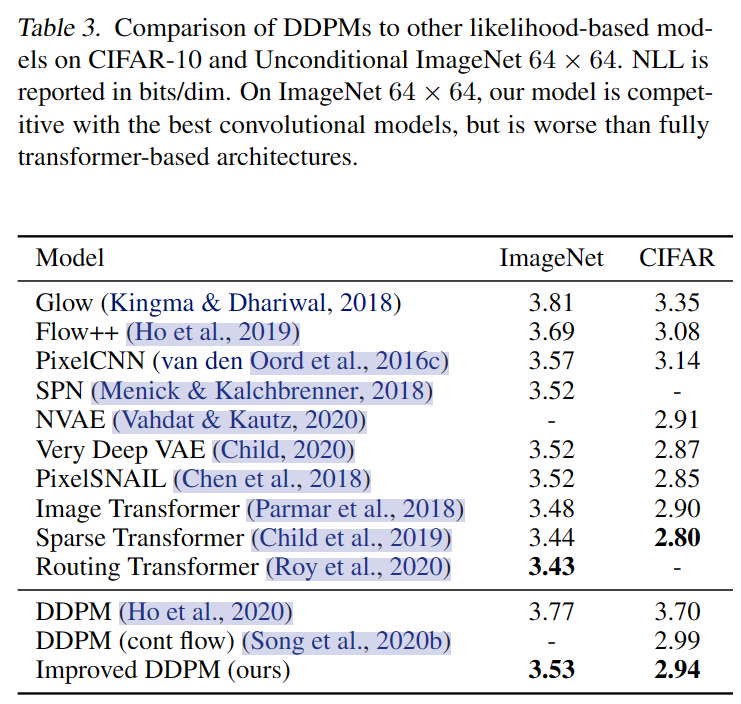
DDPM可以产生高质量的生成样本,但没有文章显示DDPM的log-likelihood能力,引发一些问题,比如DDPM是否能够捕获分布的所有模式。
贡献
- 通过参数化和混合目标函数,表明
DDPM在保证高质量图像质量的同时可以提高log-likelihood,且可加速采样过程;
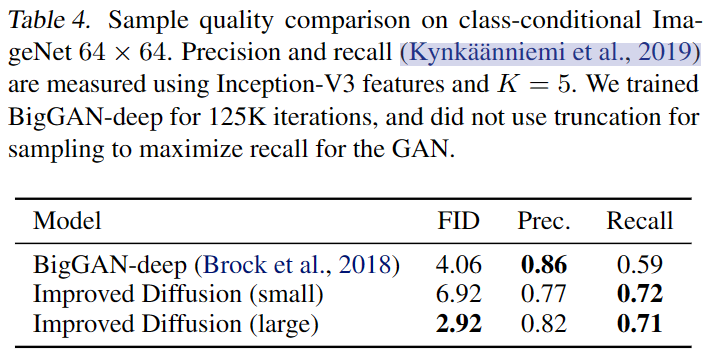
- 通过
precision和recall指标评估,发现DDPM可以匹配GAN的样本质量,并获得更好的模式覆盖;
- 发现模型容量和训练计算的增加,可以扩展模型的样本质量和
log-likelihood能力。
本文的方法
log-likelihood被广泛应用于生成模型,且认为其可以促使生成模型获取数据分布中的所有模式,并提升特征学习能力和样本质量,但DDPM在该策略上表现较差,且模式覆盖很差。本文探索算法上的改进,使得DDPM在图像数据集上能获得更好的log-likelihood,并由此受益。
Learning
DDPM固定,虽然和作为两个极值,但发现固定和的生成质量相似。
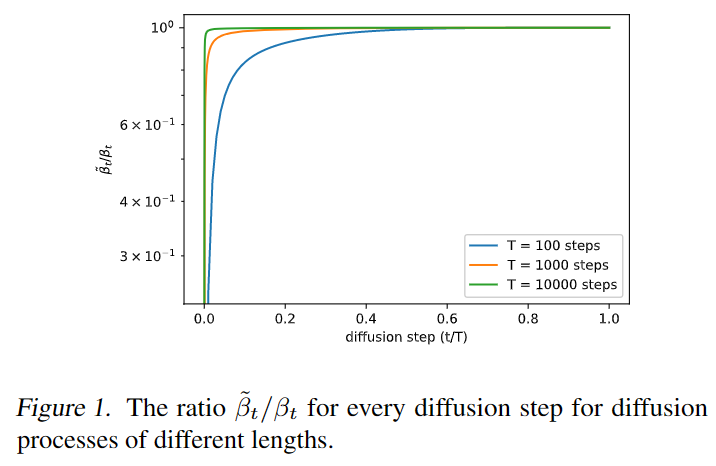
如上图所示,除了时间时,和几乎等价,而此时模型正在处理难以察觉的细节,并且随着总步数的增加,和接近的时间占比更长。这表明随着时间步的无限增加,的影响很小,比更影响分布。这表明固定对于图像质量而言是合理的,但下图显示,开始的少量时间步对变分下界的影响最大,那么我们可以通过选择更好的来提升log-likelihood。
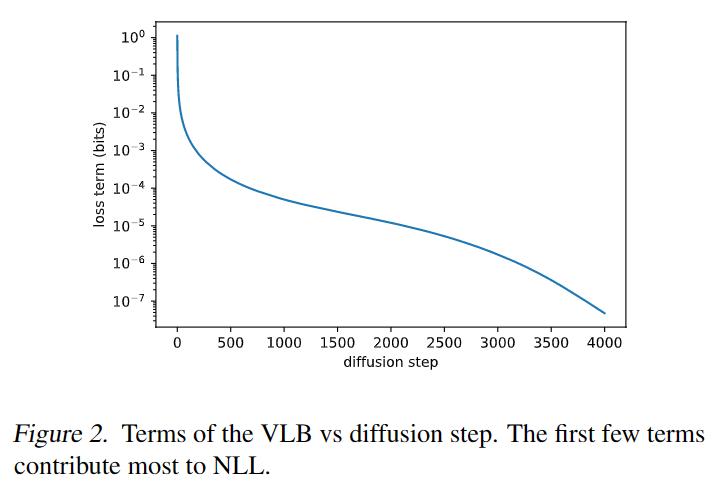
前面的图显示的合理范围非常小,即使在对数域中,神经网络也很难直接预测。本文直接在对数域中通过插值和来参数化方差,即通过模型输出向量,然后参数化得到方差:
理想情况下模型可以预测整个插值范围,但实际情况下并没有,表明边界值足够去表征。由于不依赖于,则定义新损失函数:
为了避免过度影响,设置,且在对进行stop-gradient。
Improving the Noise Schedule

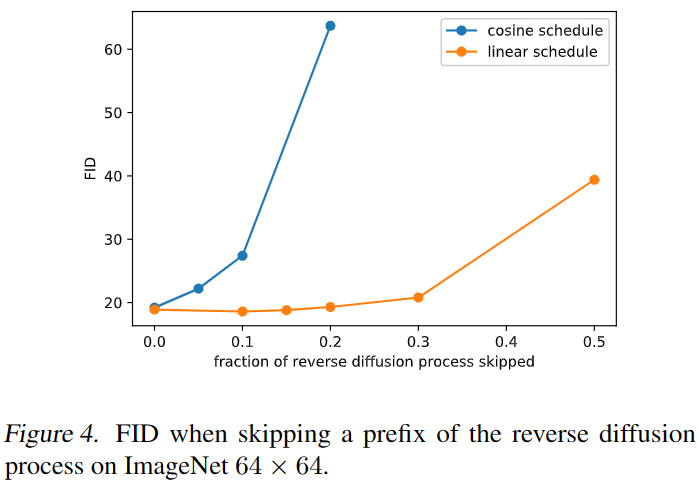
如上图所示,在前向加噪过程的后期,linear schedule的噪声很多导致对训练影响不大,而cosine schedule加噪更慢,且如下图所示,当忽略的反向过程时,用linear schedule训练的模型并没有变得更差。
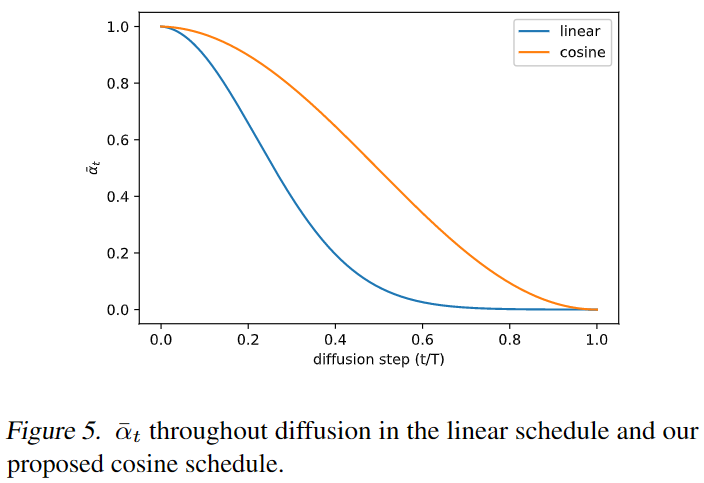
所以本文使用cosine schedule控制:
其中,是一个很小的偏移量,防止在开始阶段过小导致模型预测困难,在论文中设置。又根据定义:
本文将截断为不大于以避免扩散过程结束时(接近)出现奇点。下图也显示linear schedule下降过快,过快地破坏了数据信息。
Reducing Gradient Noise
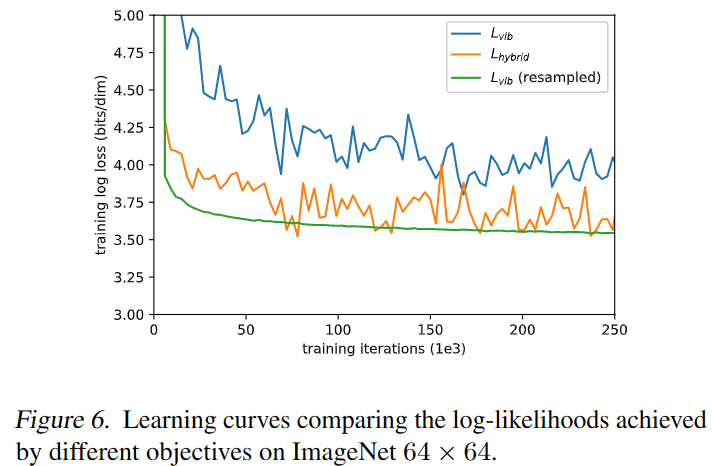
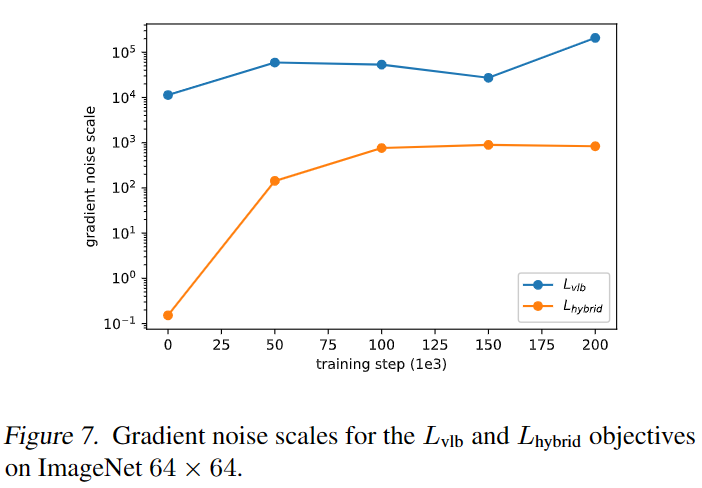
为了实现更好的log-likelihood,可以直接优化,但作者发现很难优化,如上图所示,和都噪声较大,但能实现更好的log-likelihood,作者通过下图评估目标函数的gradient noise scales,发现的梯度相比尺度更大,故需要寻找新方法减少的方差,以便直接优化。
本文优化时采用重要性采样,即:
其中,事先未知,且在训练时动态变化,故为每个损失项记录历史的前个值并在训练时动态更新,训练初始阶段则从均匀采样次。通过这个重要性采样,可以通过优化实现最佳的log-likelihood,且重要性采样的目标函数噪声比原始均匀采样的目标函数噪声小很多,但在直接优化时,发现重要性采样技术无帮助。
Improving Sampling Speed
训练时本文将提高到,通常采样时使用相同的时间步(),但为了提升采样速度,希望能够获取一个时间步子序列。对于时间序列,可通过训练时加噪策略获得,并计算对应的采样方差:
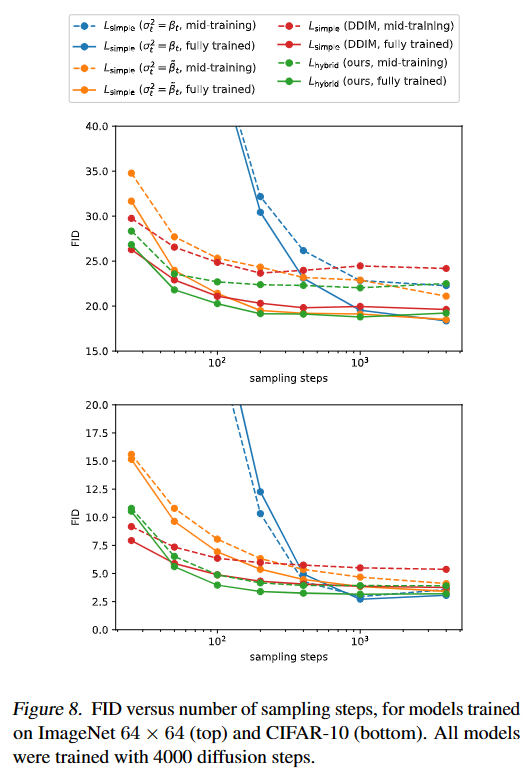
而被参数化为之间,因此可以计算。所以在之间使用个间隔均匀的实数,并四舍五入到最近的整数作为新的时间步子序列,下图显示了不同方法在不同的采样子序列下的结果,本文可使用仅个采样时间步就可以实现接近最佳效果。
部分实验结果