
动机
CV中常见的自监督方法有两种:invariance-based methods和generative methods;invariance-based methods使用同一图像的多个视图优化编码器使其产生相似的表征,该类方法通过手动数据增强,可以产生high semantic level表征,但引入的bias可能会下游任务较差,且不清楚如何将bias推广到不同abstraction层次的任务,如图像分类和实例分割不需要相同的不变性;generative methods则通过重建输入中随机mask的patch来学习表征,相比invariance-based methods需要更少的先验知识,但产生的表征是low semantic level,在linear probing等任务中表现不佳,需要更复杂的适应机制(如end-to-end finetuning)才能充分利用该类方法;- 本文则探索如何在不使用数据增强等额外先验知识的情况下提高自监督学习的语义水平。
贡献
- 提出了一种新的自监督学习框架
I-JEPA(Imagebased Joint-Embedding Predictive Architecture); - 首先,
I-JEPA的核心思想是通过预测表征空间中缺失的信息,即通过context信息预测同一图像中target的表征,相比generative methods在像素空间预测生成,能消除不必要的像素细节,使得模型学习更多的语义特征; - 其次,
I-JEPA提出multi-block masking stategy,展示了使用信息丰富的(空间分布的)上下文块预测图像中多个目标块的重要性(规模足够大); - 最后,
I-JEPA具有高度的可扩展性,训练较MAE和iBOT更快,在可以在各种抽象级别的下游任务中获得较好的性能。
本文的方法
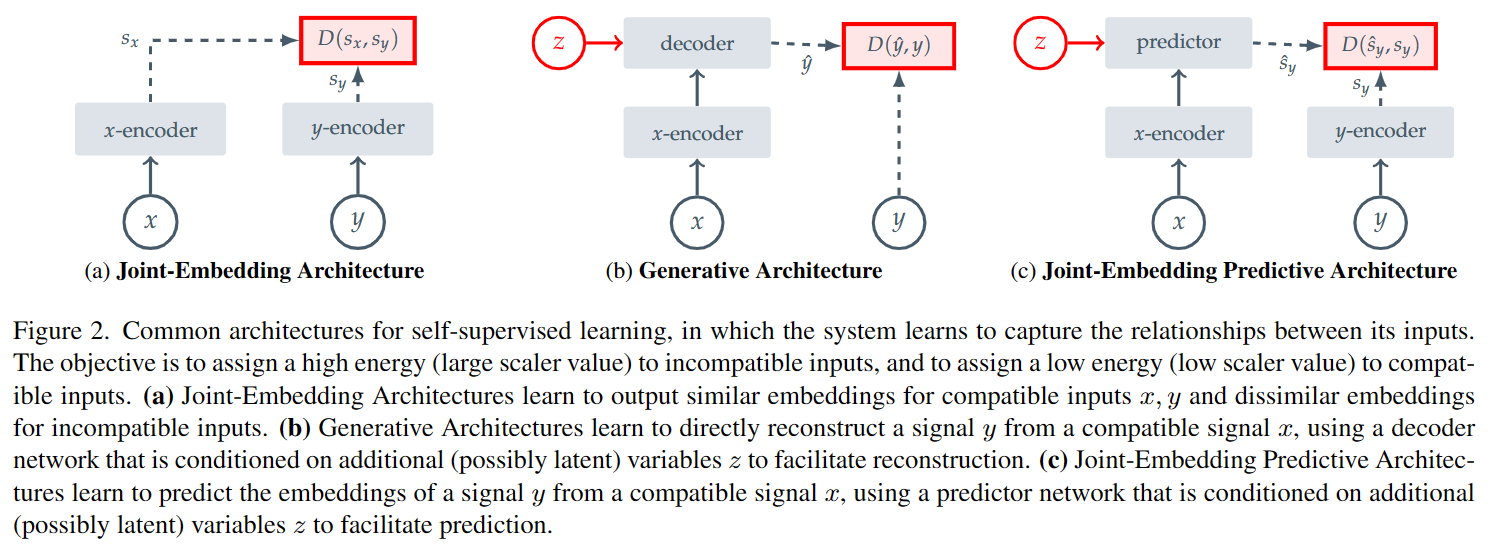
本文首先使用基于能量的模型EBM来描述自监督学习,即将高能量分配给不兼容的输入,低能量分配给兼容的输入。Joint-Embedding Architecture(JEA)为兼容的输入输出类似的表征,不兼容的输入输出不同的表征,主要挑战是避免表征崩塌(即无论输入如何,编码器都产生恒定的输出);Generative Architecture使用以额外变量为条件的decoder从输入重建。Joint-Embedding Predictive Architecture(JEPA)与Generative Architecture的主要区别是损失函数应用在特征空间;与Joint-Embedding Architecture的主要区别在不需要手动进行数据增强。
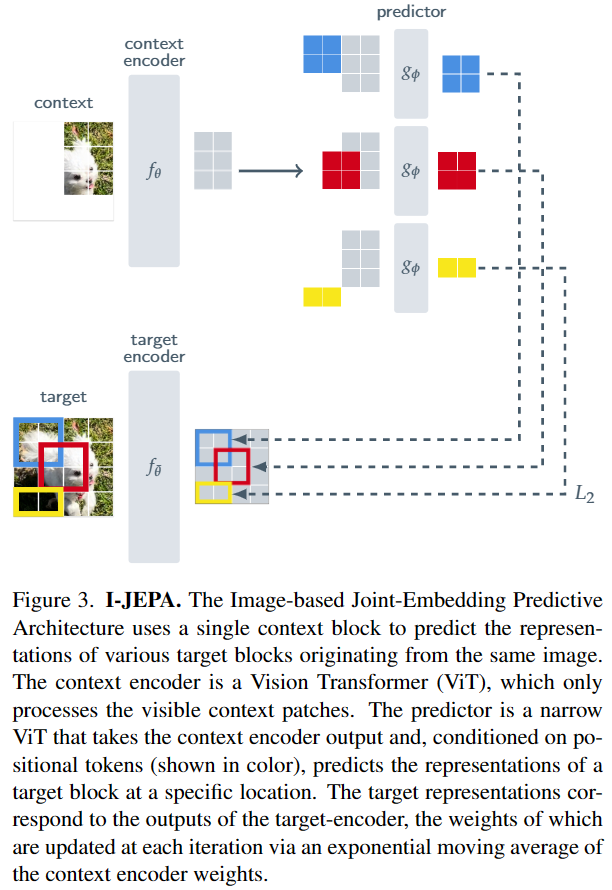
上图为I-JEPA的总体框架,其目的是给定一个context block,预测其同一图像的多个target block,本文使用ViT作为context-encoder,target-encoder和predictor的backbone。
Targets
对于输入图像,分割为个不重叠的patch,经过target-encoder 获得对应的特征,并从随机采样个可能有重叠的block,获得对应的patch特征。一般情况下,设置,纵横比范围为,尺寸范围为。注意:target blocks是通过mask输出特征获得,这可以获得high semantic level的特征。
Context
从图像中随机采样一个尺寸范围为,单位纵横比的context block,并去除与target blocks重叠的部分(避免平凡解),得到masked context block,示例图像如下所示,通过context encoder 获得对应的特征。
Prediction
给定context block特征,希望预测对应的个target blocks的特征。对于,对应mask为,预测器输入context block特征和希望预测的mask token ,输出预测。mask token被参数化为具有额外positional embedding的共享可学习向量,通过预测M次得到期望预测的特征。
Loss
损失函数如下:
其中,predictor和context encoder通过梯度优化,而target encoder通过context encoder参数的EMA更新(避免表征崩塌,即无论输入如何,编码器都产生恒定的输出)。
实验
本文主要通过实验证明:
I-JEPA在不使用视图增强的情况下,可学习很强的现成的语义表示,在ImageNet1k的linear probing、semi-supvised、semantic transfer上优于图像重建方法如MAE;
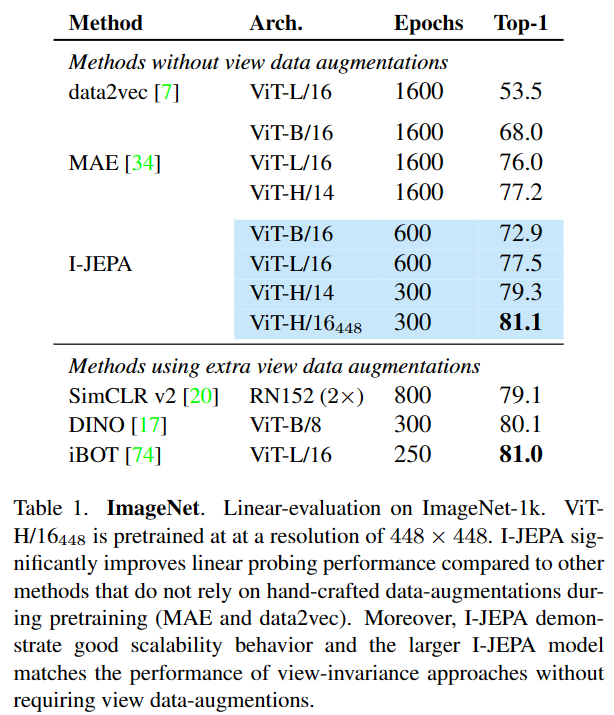
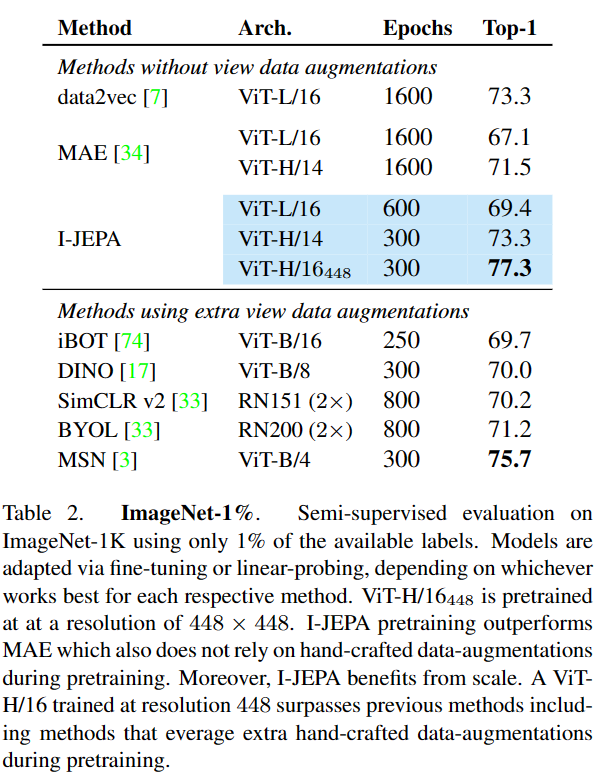

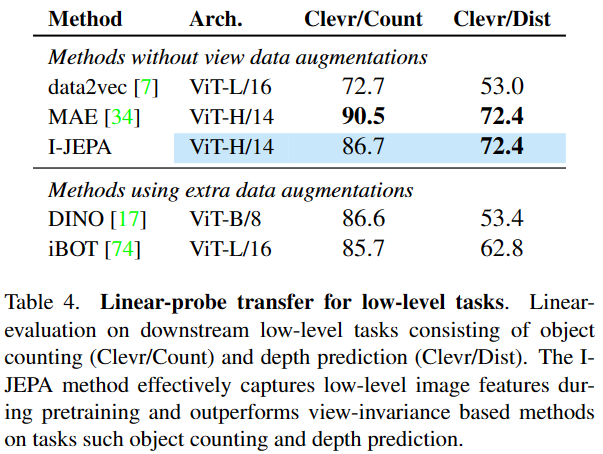
I-JEPA在语义任务上与view-invariant方法效果相当,并在low-level视觉任务上更优,如object counting、 depth prediction;
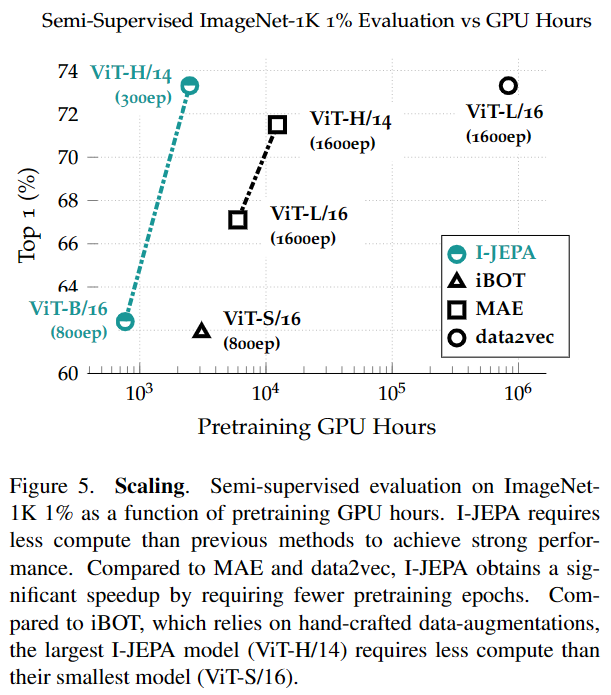
I-JEPA可扩展且高效,在表示空间中进行预测显着减少了自监督预训练所需的总时间。
下图显示预测器的可视化结果,I-JEPA可以正确捕捉位置不确定性,并产生正确姿态的high-level目标,但抛弃了精确的low-level图像细节和背景信息:
