动机
- 文图生成中
text-only query的可控性有限,如简单地使用与位置相关的文本词通常会造成模糊的input query,且当text query很长、复杂或描述罕见场景,模型可能会忽略某些细节而只遵循视觉或语言先验; layout-to-image generation在区域控制方面有一定作用,但很难理解自由形式的文本输入,也不能理解开放文本描述和空间位置的组合。
贡献
- 提出一种预训练文图生成模型
ReCo,在region-controlled input query中引入position tokens,用户可在图像区域自由指定regional descriptions; - 基于
Stable Diffusion实例化ReCo,可基于输入query的regional instructions生成高质量的图像; - 设计了一个
evaluation benchmark来评估region-controlled的生成能力。
本文的方法
ReCo旨在探索文本条件和位置条件的协同生成,其核心思想是引入额外的input position tokens表示空间坐标,将图像的w/h均匀量化为 bins,任意坐标被最近邻的bin近似和量化。在额外的embedding 下,position token被映射到与text token相同的空间,则区域控制文本输入为<x1>, <y1>, <x2>, <y2>, <free-form text description>。然后使用微调预训练的T2I模型,以从region-controlled input query中生成图像。
Preliminaries
Stable Diffusion基于Latent Diffusion Model,由一个auto-encoder、一个用于噪声估计的U-Net和一个CLIP ViT-L/14 text encoder构成。对于auto-encoder,encoder的down-sampling factor为,其将输入图像编码为用于扩散过程的隐编码,decoder则从重建图像;对于U-Net,则以去噪时间步长和文本条件为条件,其中为text tokens 的input text query,而为CLIP text encoder将文本序列映射的embedding。
Region-Controlled T2I Generation
input sequence
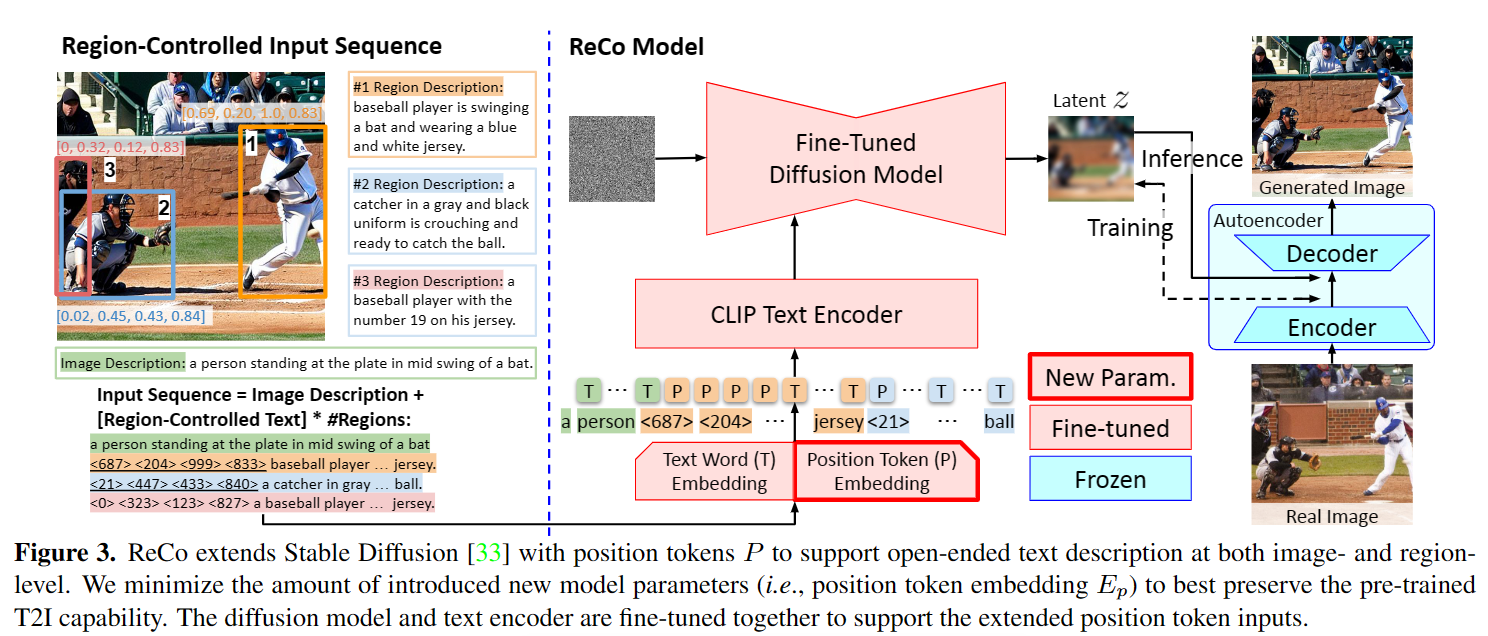
如上图所示,ReCo引入直接表示空间位置的position tokens,即将区域的位置和大小用浮点数表示为左上、右下坐标<x1>, <y1>, <x2>, <y2>,记作。在image description后添加多个region-controlled texts,即四个position tokens和相应的区域描述。ReCo在预训练的text word embedding上引入position token embedding,其中为位置标记的个数,是标记嵌入的维度。然后将整个序列联合处理,将token映射到D-dim的token embedding,输入预训练的CLIP text encoder映射为扩散模型的条件输入squence embedding。
fine-tuning
ReCo将带text tokens 的text-only query 扩展为组合text word 和position token 的input query ,使用与Stable Diffusion相同的损失函数:
其中和为fine-tuned的网络模块,除了position token embedding ,其余模型参数均由Stable Diffusion初始化。对于训练数据,在按照标注的bounding boxes裁剪的图像区域上应用caption model GIT获得区域描述;在微调时将图像短边resize到并随机crop一个正方形区域作为输入图像。
实验
从Stable Diffusion v1.4 checkpoint对ReCo进行微调,引入个position tokens,并将text encoder的最大长度增加到。batchsize为,使用固定学习率的AdamW训练模型步。
实验数据
对于input queries,从数据集中获取图像描述和边界框,并在裁剪区域上使用GIT生成区域描述,在COCO、PaintSkill、LVIS上进行测试。
- 使用
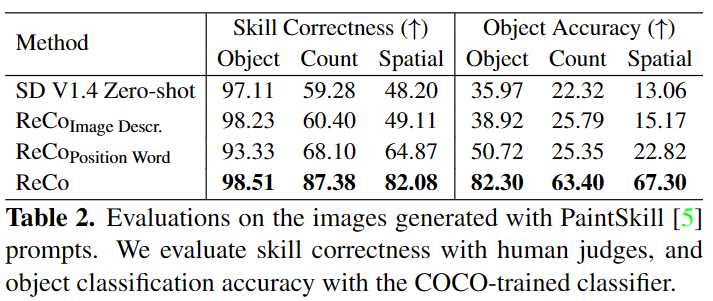
COCO 2014 training set在stable duffison上finetune,并从COCO 2014 validation set采样的子集上测试; PaintSkill用于评估模型在任意位置的边界框和生成图像是否具有正确的目标类型/数量/关系的能力;LVIS用于评估模型是否理解open-vocabulary的区域描述,其目标类别在finetune数据中不可见。
评估方法
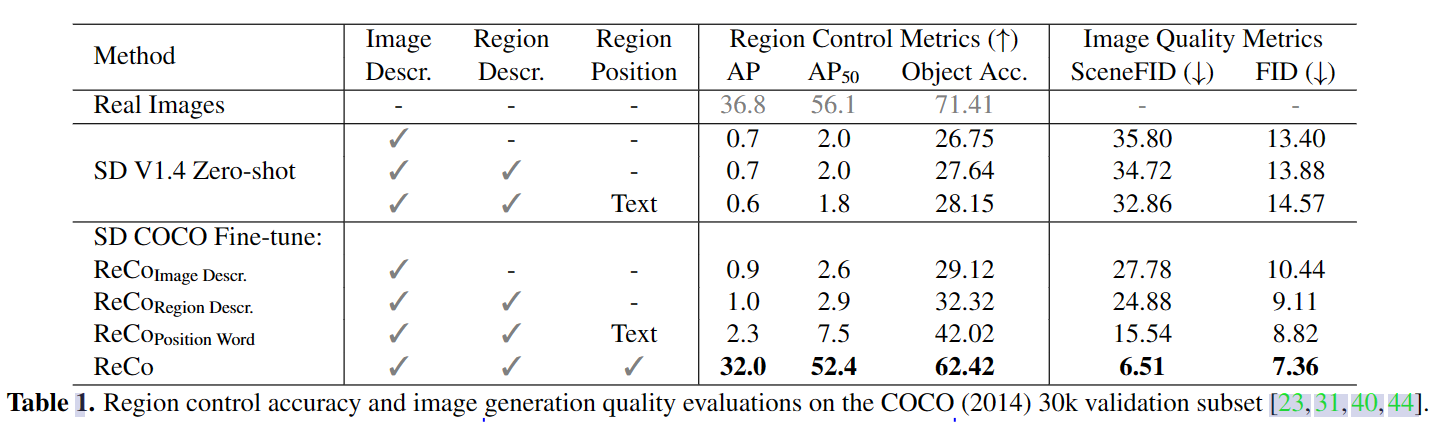
为了评估区域控制,设计了一种基于预训练的regional object classifier和object detector,即在生成的图像区域应用object classifier,在整个图像上应用object detector,更好的精度意味着生成的目标layout跟用户query中的位置有更好的对齐。
对于region control accuracy,使用Object Classification Accuracy和DETR detector Average Precision。Object accuracy在GT image crops上训练,以分类生成图像的裁剪区域;DETR detector AP则检测生成图像的目标,并与input object query比较。
对于image generation quality,使用FID评估,对于区域图像的质量,使用SceneFID,即根据input object boxes在裁剪区域计算FID。在center-cropped COCO图像上根据Clean-FID repo计算FID和SceneFID,在PaintSkill上则进行人工评估。
部分实验结果
COCO

PaintSkill

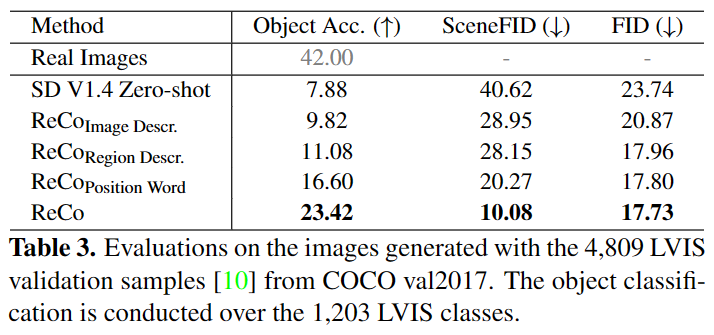
LVIS

区域描述时使用开放式文本或受限目标类别的区别