
动机
- 在无监督情况下如何学习有用的表征很关键,希望实现一个模型在其隐空间保存数据重要特征的同时优化最大似然;
- 而采用离散编码更容易对先验建模,且连续的表征通常会被网络内在地离散化。
贡献
- 引入矢量量化的思想,将
VAE与离散隐空间相结合,提出VQVAE,它避免了posterior collapse和variance issues,且与连续编码模型表现相当; - 当离散隐编码与自回归
prior配对使用,模型可在speech and video generation等应用生成高质量的一致性样本,以及无监督学习。
本文的方法
VAE通由以下部分构成:encoder建模给定输入的离散隐编码的posterior distribution ,prior distribution 和decoder建模likehliood分布。通常假设prior distribution为标准正态分布、posterior distribution为对角方差的多元正态分布,隐编码为连续的随机变量。
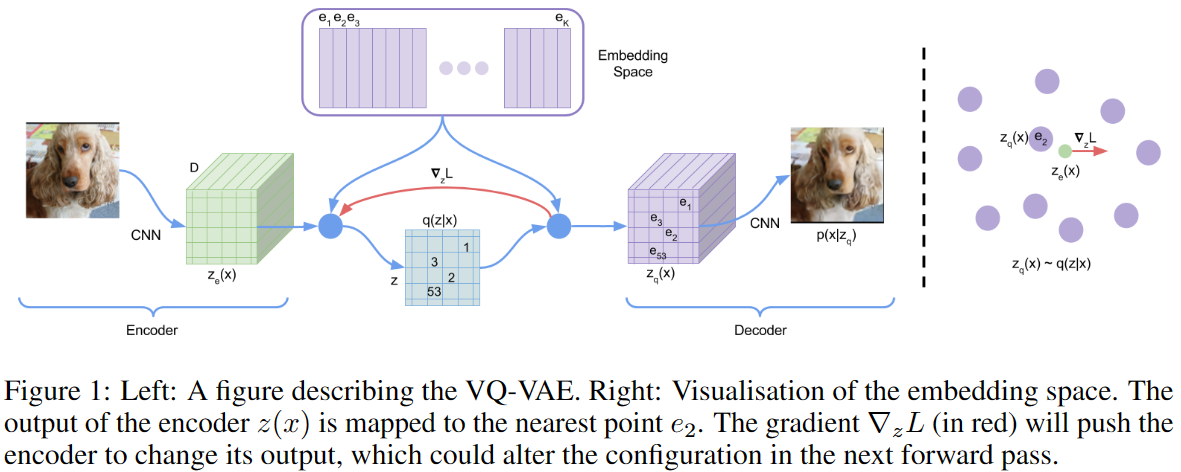
VQVAE跟VAE主要的不同在于:1)encoder的输出是离散的而不是连续的;2)prior是可学习的而不是静态的。如下图所示,对于输入,encoder输出,通过vector quantisation使用离散隐编码,即通过最近邻从隐空间中找出离散隐变量,则先验分布和后验分布是可分类的,分布中的分量为映射embedding table的index,并将其作为decoder的输入。
Discrete Latent variables
定义隐空间,其中为离散隐空间的大小,为每个隐编码的维度,即。如下图所示,对于输入,encoder输出,通过最近邻从隐空间中找出离散隐变量,VAE的后验分布为多元高斯分布,而VQVAE的posterior categorical distribution为one-hot形式:
其中,为encoder的输出,再通过最近邻从隐空间映射量化得到decoder的输入,即:
Learning
类似VAE,使用ELBO约束,通过定义先验为均匀分布,则proposal distribution 为确定的,且KL divergence为常数,即:
故相比VAE,VQVAE训练过程中未使用先验分布,仅使用重建损失,则第二阶段需要训练先验模型用以生成图像。由于argmin导致不可导,则类似staright-through estimator近似估计梯度,即直接将decoder的输入的梯度复制给encoder的输出。在前向计算时,最近邻的embedding 被传递给decoder,在反向传播时,梯度被直接传递给encoder,由于和共享空间,所以梯度包含encoder如何改变输出去降低重构损失的信息。但embedding 没有从重构损失中接收到梯度,为了让embedding参与训练,使用Vector Quantisation,即计算encoder的输出和向量量化后得到的embedding 之间的误差(也可以通过EMA对embedding进行更新)。同时,为了限制embedding空间和encoder输出的一致性,避免encoder的输出变动过大,额外增加了一项commitment loss,则总的损失函数如下:
其中,表示stop gradient,decoder只优化第一项重建损失,encoder优化损失的第一项最后一项,embedding优化中间的commitment loss,文章所有实验均设置。对于一张图像,在计算第二项和第三项损失时将计算个离散隐编码的损失的平均值。
Prior
训练VQVAE时,先验分布恒定为均匀分布,训练完成后需要在上拟合一个自回归分布,以通过抽样生成离散编码。即使用VQVAE对训练图像进行推理得到对应的离散编码,再采用PixelCNN对离散编码建模,基于softmax预测类别。生成图像时则通过训练好的PixelCNN采样离散编码,再送入VQVAE的decoder生成图像。
部分实验结果
在ImageNet上重建的结果
在ImageNet训练的VQVAE,之后从PixelCNN采样先验后生成的结果