动机
- 不同类型的语言模型使用不同的预测任务和训练目标,
BERT提高了NLU任务的性能,但双向特性难以适应NLG任务。
贡献
- 提出一个新的联合预训练语言模型
UniLM,使得在NLU和NLG任务上都可以进行fine-tuned; - 该方法通过共享的
Transformer和特定的self-attention mask预测条件上下文,通过三种无监督语言目标进行优化,在GLUE等数据集上结果优于BERT。
不同类型的语言模型的区别

UniLM
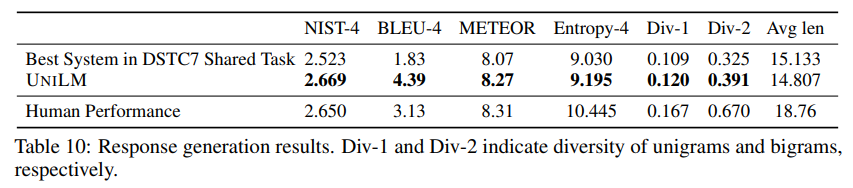
预训练目的在于对于给定的输入序列,获得每个token的上下文表征向量。如图所示,通过三种不同的无监督语言建模目标对共享的多层Transformer进行优化,包括unidirectional LM、bidirectional LM和sequence-to-sequence LM。在实现时,通过控制self-attention时的mask来控制每个token对上下文的关注程度,以进行不同的建模任务。预训练后,则使用下游任务的特定任务数据进行微调。
预训练目标
本文为不同的语言建模目标设计了四个完形填空任务,即对输入随机选择一些token并进行[MASK],然后输入Transformer并通过softmax进行分类预测。
Unidirectional LM:
包含left-to-right和right-to-left,即每个token只对其单向的context token和自身进行编码,在self-attention时使用三角形的mask来实现,将不被关注的部分设置为,被关注的部分设置为。
Bidirectional LM:
允许所有token在预测时相互可见,从两个方向上对context信息进行编码,在self-attention时的mask为全矩阵。
Sequence-to-Sequence LM:
在第一个source segment内,token双向互相可见,在第二个target segment内,token只关注自身、及左边的段内上下文,和源段的token。在self-attention时,左边部分设置为,即所有token都可以关注source segment,右上部分设置为,即source segement中的token不能关注target segment,右下部分的上三角设置为,其余为,即target segement中的token只关注自身及左边位置。
Next Sentence Prediction:
对于Bidirectional LM,使用BERT的NSP任务。
预训练设置
最终的训练目标是上述不同类型的LM目标之和,即在训练的一个batch,的数据使用Bidirectional LM,的数据使用Sequence-to-Sequence LM,left-to-right LM和right-to-left LM各。
UniLM模型采用BERT_large,使用gelu激活函数,即包含层Transformer,hidden size为,有个attention head,softmax的权重和token embedding相关联。使用BERT_large进行初始化,之后使用WikiPedia和BookCorpus进行预训练,词表大小为,输入序列最大长度为,token mask的概率为。采用Adam(0.9,0.999)进行优化,学习率为,在前步进行linear warmup,之后进行线性衰减,dropout rate为,weight decay为,batchsize为。
微调
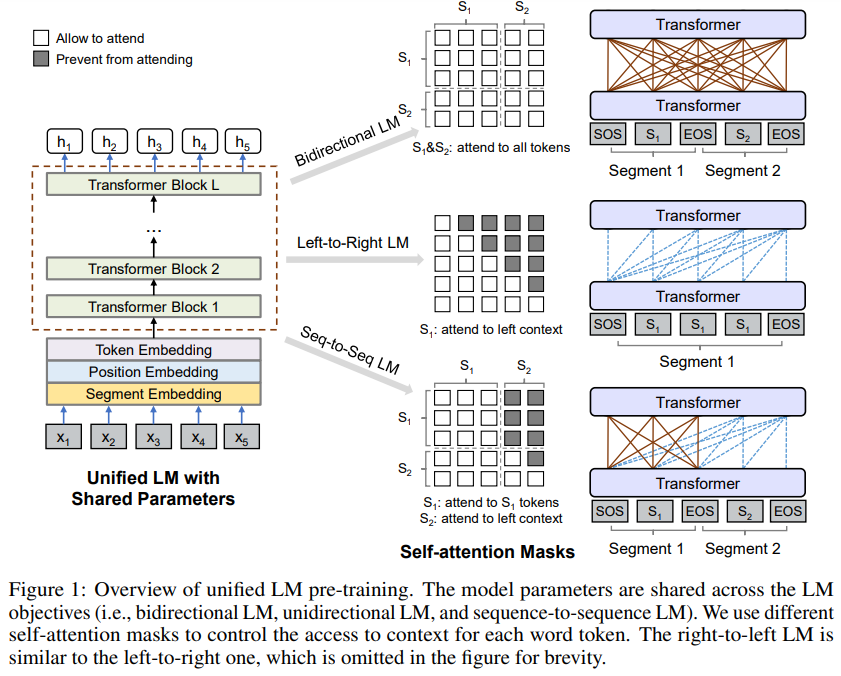
对于NLU任务,将UniLM作为bidirectional Transformer encoder,类似BERT;
对于NLG任务,以sequence-to-sequence为例,输入设置为[SOS]S1[EOS]S2[EOS],通过在目标序列中随机mask并预测恢复来进行微调,训练目标是在给定的context中最大限度提高mask token的似然,若[EOS]被mask,则是希望模型学习何时给出[EOS]以结束生成。
部分实验结果
NLU任务GLUE benchmark:
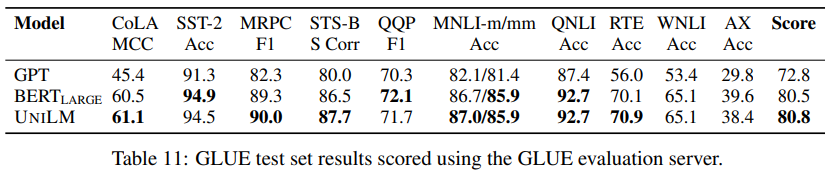
NLG任务dialog response generation:
该任务使用了label smooth和beam search(即使用topk)