
动机
图像-文本生成任务是双向的,但由于语言生成和图像生成的架构不同,通常将两个任务分开处理,设计特定于任务的框架;
近年来,视觉语言预训练模型大幅提高图像到文本生成任务的性能,但大规模的文本到图像生成任务预训练模型仍处于开发阶段。
贡献
- 提出一种生成预训练框架
ERNIE ViLG,适用于双向图像-文本生成任务,并采用端到端的训练方式联合学习视觉序列生成器和图像重构器; ERNIE ViLG在text-to-image synthesis和image captioning任务上有着优越的性能,表明双向生成模型可捕捉对齐视觉和语言模态的复杂语义。
ERNIE ViLG
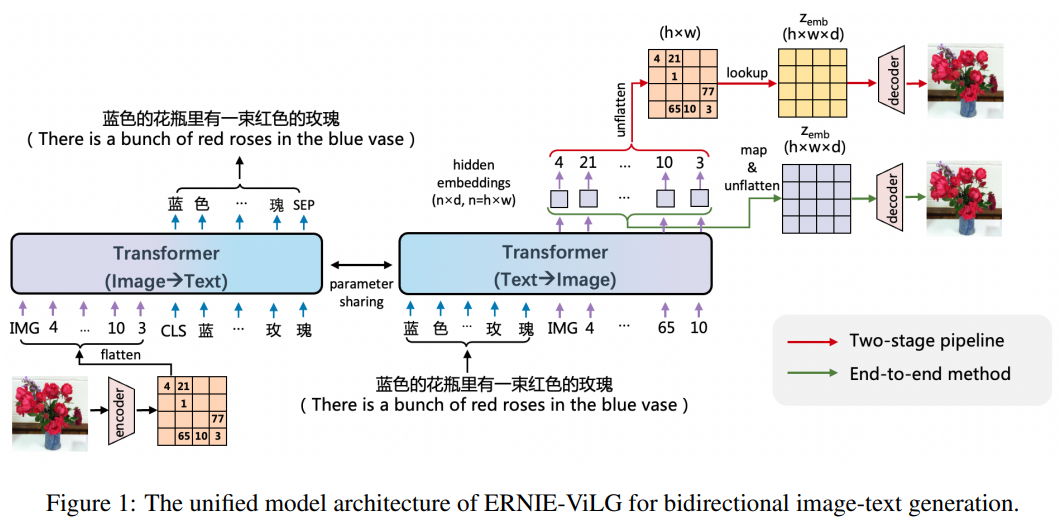
如图所示,ERNIE-ViLG联合框架进行双向图像文本生成。图像经过VQVAE编码为离散表征序列,该离散序列作为参数共享的Transformer的输入和输出,用于自回归的图像到文本/文本到图像的生成。即在文本到图像生成任务中,Transformer输入为文本,输出为相应的视觉离散序列,再被用于重建图像;在图像到文本生成任务中,Transformer输入为图像离散序列,输出为文本序列。本文则提出一种端到端的训练方法,对离散表征序列生成和图像重建联合训练,以增强文本到图像的生成能力。
图像离散表征
离散表征可以更好地适用于autoregressive建模,VQVAE使用vector quantization将图像表征为隐离散序列,比像素聚类具有更强的语义表示能力。对于输入图像,经过编码器得到图像特征,再通过codebook量化为,然后通过解码器和codebook重建。损失函数如下:
其中,表示stop-gradient,为vector quantization,最终离散序列作为双向生成模型的输入或输出,其长度为。
上式中第一项损失为reconstruction loss,仅训练encoder和decoder,不更新codebook;第二项损失为commitment loss,仅训练encoder,避免encoder的输出反复变化;第三项损失为codebook loss,仅训练codebook,希望codebook中的embedding跟对应的图像特征向量靠近。
双向生成模型
ERNIE-ViLG使用多层transformer encoder进行图像到文本和文本到图像的生成任务,且encoder和decoder参数共享,并使用UniLM和ERNIE-GEN中特定的self-attention mask控制上下文。其中,source token允许参与所有source token,而target token允许参与在其左边位置的source token和target token。作者认为模型空间共享有助于建立更好的跨模态的语义对齐。
假设图像通过VQVAE encoder离散化得到visual token为,文本经过WordPiece tokenizer序列化得到textual token为,连接后输入Transorformer中。训练期间,对于文本到图像生成任务,输入预测image tokens;对于图像到文本生成任务,则输入预测text token。最终的损失函数为:
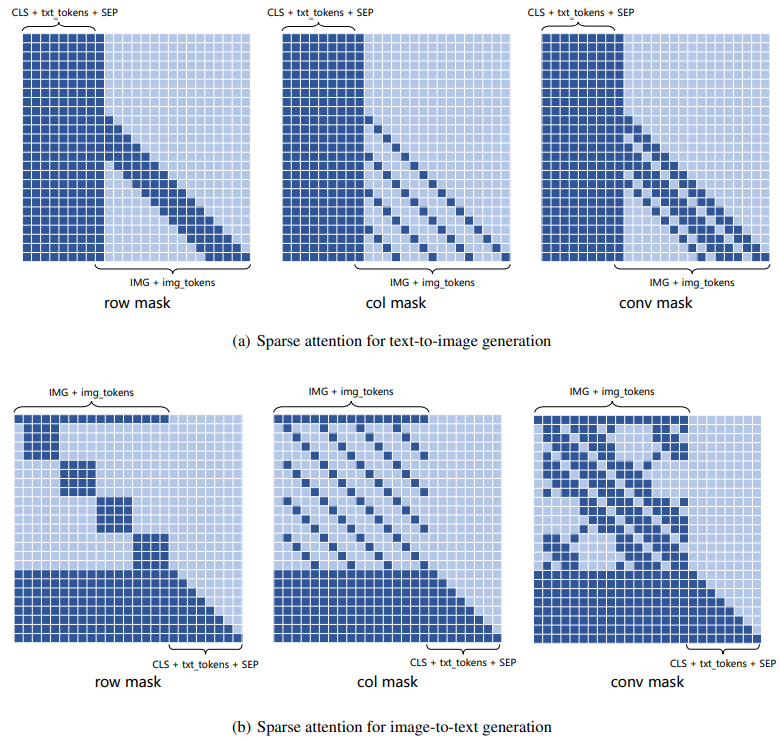
通常为了减少图像的信息损失,图像序列的长度很大,导致Transformer训练和推断时的计算成本和内存消耗较高。故使用DALL-E的稀疏注意力机制,如下图所示,即对第个transformer layer采用如下方式:使用row attention(i mod 4 != 2)、column attention(i mod 4 = 2)和convolutional attention(最后一层)。实验表明,稀疏注意力机制在训练时提速,可节省的显存,并跟原始注意力具有一样的损失收敛性,本文将其应用到双向建模。
文本到图像生成
基于图像离散表征的文本到图像生成通常分为两个阶段:离散表示序列生成和图像重建。先从cookbook中查找生成的离散序列获得三维表征,再送入重建decoder恢复图像,此时generator和reconstructor分开训练。
本文则采用端到端的训练方法,最后的transformer layer输出的image token的hidden embedding被映射得到三维表征,梯度可以从reconstructor后向传播到generator,避免了ID mapping操作。优点在于:
- 可以为
reconstructor提供更多上下文信息,相比于cookbook中与上下文无关的embedding,最后一层的hidden embedding包含更多的图像语义,且可通过注意力交互感知文本信息。 - 可以通过重建任务帮助
generator,可以提高generator和reconstructor的性能。
图像到文本生成
首先使用encoder和VQVAE的cookbook将图像离散为visual token,再输入Transformer按照自回归方式生成text tokens,本文在图像到文本生成任务训练期间将quantization modules进行预训练后固定。
部分实验结果
参数设置
使用VQGAN作为image tokenizer,设置表示图像尺寸的reduction factor,vocab size = 8192,预处理图像时使用center crop为,由此得到图像离散序列的长度为。
对于generator,使用多层transformer encoder,由个transformer layer组成,包含个隐藏单元和个attention heads,考虑基于GAN的不稳定,训练时选择两阶段text-to-image synthesis,并使用VQGAN的decoder作为image reconstructor。
Text-to-Image Synthesis
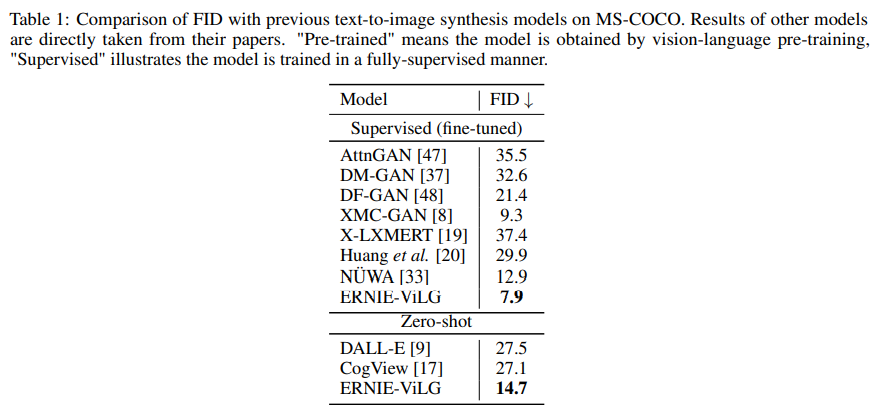
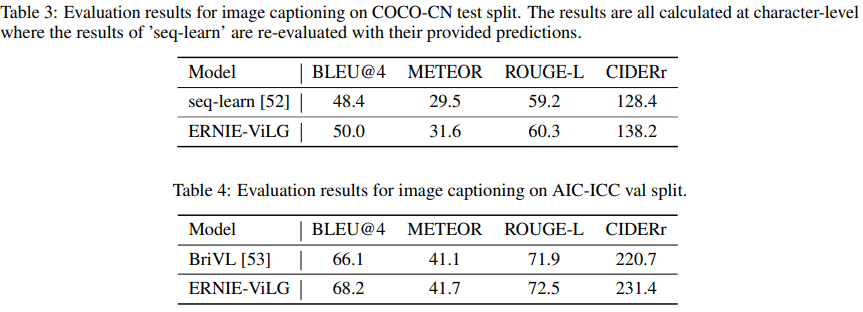
Image Captioning
Generative Visual Question Answering

不同训练方式的比较
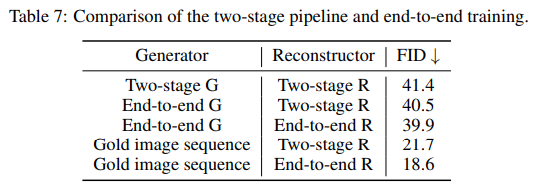
其中,Two-stage G(R)指单独训练,end-to-end G(R)指端到端训练,Gold image sequence指通过dVAE离散化得到的视觉序列。根据上表可得:端到端的训练方法相比两阶段训练更优。