动机
- 随着算力和模型的增长,需要大量的数据,但通常无法获得大量的有标签数据,而
NLP则通过自监督预训练获得成功; masked autoencoder是一种更一般的denoising autoencoder,该方法优先在CV中提出,但CV中的相关发展却落后于NLP,作者试图发问:是什么导致了masked autoencoder在vision和language的不同;
贡献
- 尝试从几个方面回答
masked autoencoder在vision和language的不同,并提出了一种新的视觉表征学习方法MAE,该方法在输入图像中mask随机patches,并在像素空间中重建被mask的patches; MAE设计了非对称的编码器-解码器架构,并发现高比例的mask具有更好的效果,可以加快训练速度并提高准确性;- 通过
MAE预训练,可以在ImageNet-1K数据上训练ViT-Large/-Huge,比先前所有使用相同数据的方法更好,并且可以在目标检测、实例分隔、语义分割上进行应用。
MAE
masked autoencoder在vision和language的不同:
- 架构上的不同。
CV通常使用CNN,将mask tokens或positional embeddings集成到CNN上比较困难,随着ViT的引入,结构上逐渐一致; vision和language的信息密度不同。语言具有高度的语义和信息密度,而图像具有大量冗余,在对场景缺乏高层次理解情况下,可以从相邻patch中重建缺失的patch,所以需要更大的mask比例;- 解码器将潜在表征映射回输入,其在文本和图像之间有不同的作用。在视觉中,解码器重构像素,其语义级别较低;在语言中,解码器预测缺失单词,其语义信息更丰富。
MAE基本思路:根据原始信号的部分观测结果重建原始信号,采用非对称的编码器-解码器设计。其中,编码器将观测到的信号映射到潜在表征,仅对无mask tokens的信号进行操作;解码器则从潜在表征和mask tokens重构原始信号。
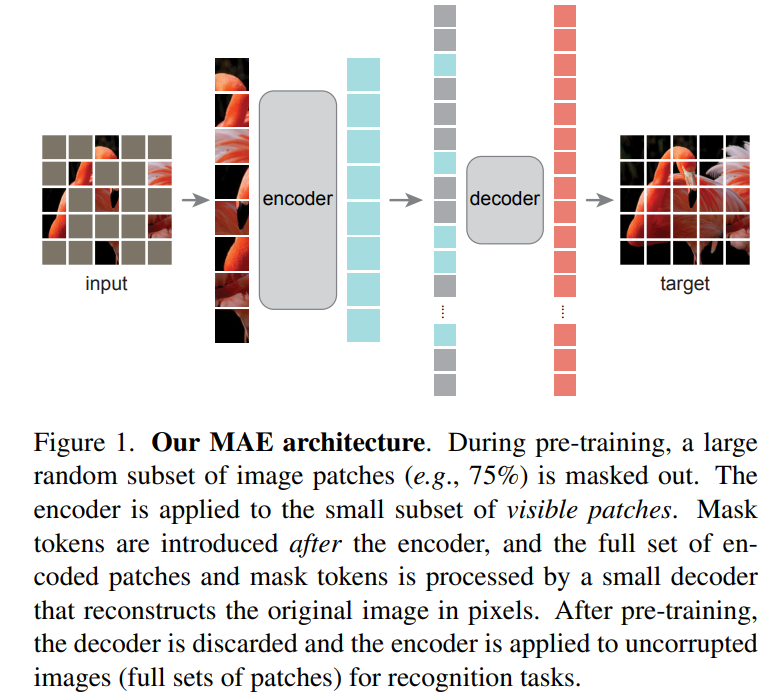
Masking
参照ViT,将图像划分为非重叠的patches,并使用均匀分布对patches进行采样,将其mask。采用高masking ratio的随机采样在很大程度上消除了冗余,使得该任务更加困难,均匀分布则防止可能的中心偏移(即图像中心更容易被mask),且高masking ratio使得编码器更高效。
MAE encoder
采用ViT,仅适用于无mask tokens的patches。类似ViT,通过线性映射将positional embeddings加入embeds patches,再通过一系列Transformers处理结果;但MAE encoder只在整个集合的一小部分上运行,被mask的patches被丢弃,且不使用mask tokens,使得能训练更大的编码器。
MAE decoder
由一系列Transformers构成,其输入包含两部分:被编码的可见的patches向量和mask tokens。每个mask tokens是一个共享可学习得向量,表示要预测的被mask的patches。并且需要对所有输入,加入positional embeddings。
MAE decoder仅在预训练期间用于图像重建任务,本文使用比编码器更窄更浅的架构(计算量不到encoder的),由此减少了预训练时间。
Reconstruction target
通过预测被mask的patches的像素来重建输入。解码器最后一层为一个线性映射,其输出通道数等于一个patch中像素值的数量,通过reshape重构图像,并计算重建图像和原始图像之间的均方误差,仅计算mask patches的损失。另一种变体是重建每个mask patches的归一化像素值,即计算每个patches中所有像素的平均值和标准偏差,并使用它们对patch进行归一化,显示该方法能提高表征质量。
Implementation
首先,对每个patch通过添加positional embeddings的线性映射生成一个token,对token list使用randomly shuffle,并基于masking ratio对后面部分的token list删除,然后通过encoder进行编码;再将mask tokens加入到encoded patches,并进行unshuffle使其与目标进行对齐,再对这个full list通过decoder进行重建。(这里encoded patches需要再加positional embeddings吗?)
部分实验结果
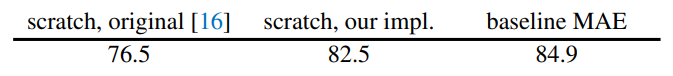
在ImageNet-1K上进行训练,发现原始的ViT-Large由于参数量很大,在小数据集上容易过拟合,而加上强的正则化能提高准确率,使用MAE预训练方法微调能获得最好的结果。
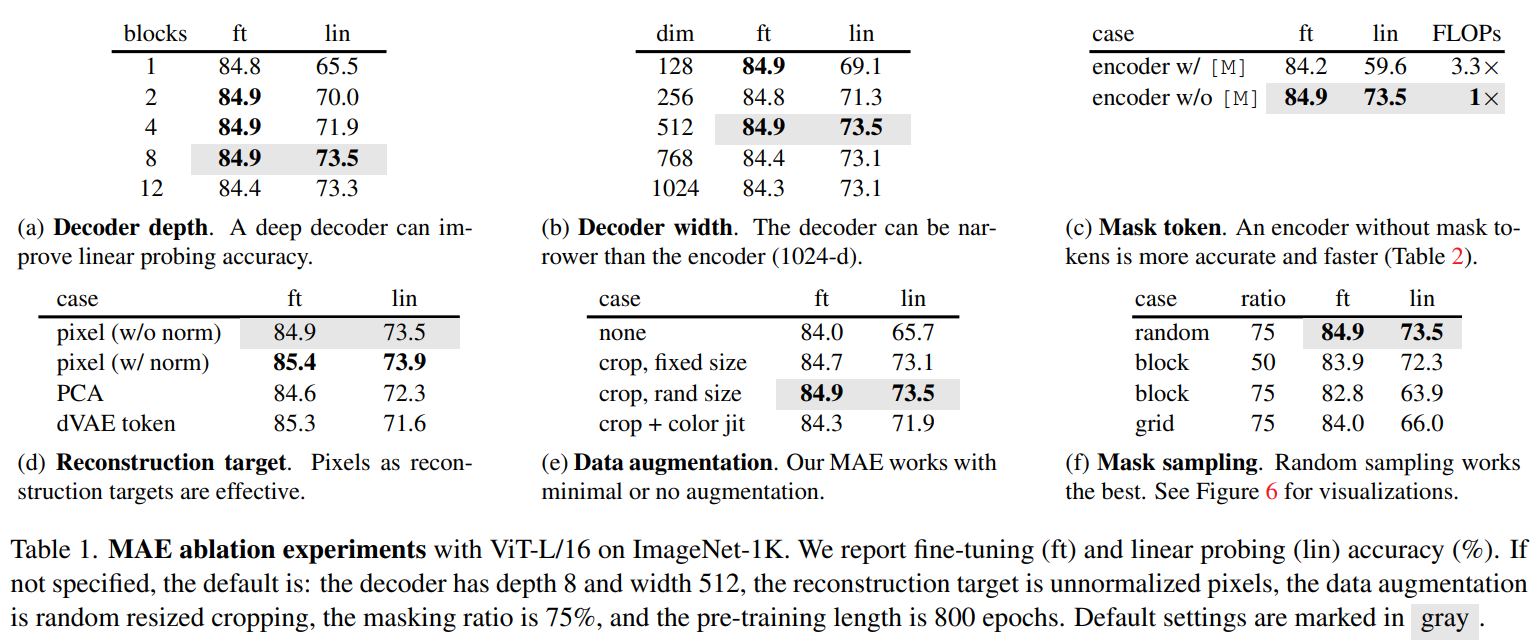
Ablation Studies:
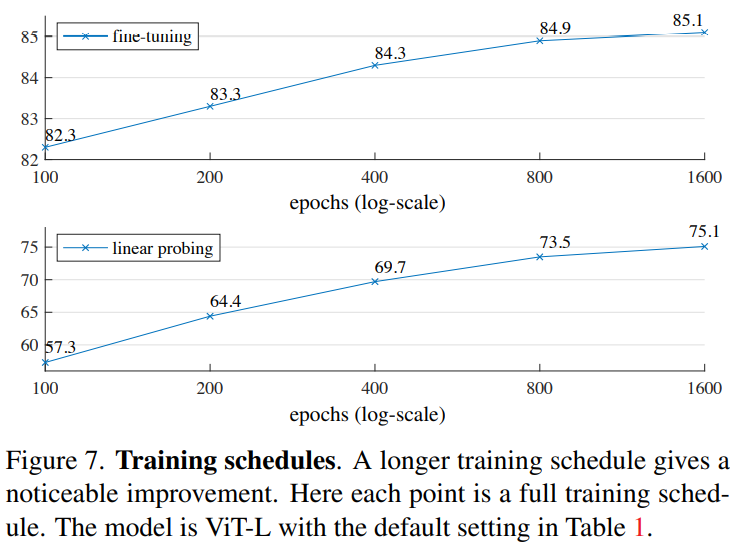
与先前方法的比较:
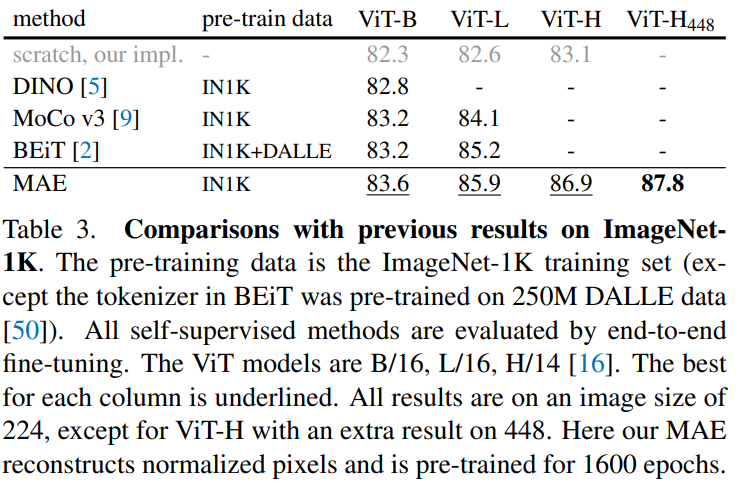
部分微调:
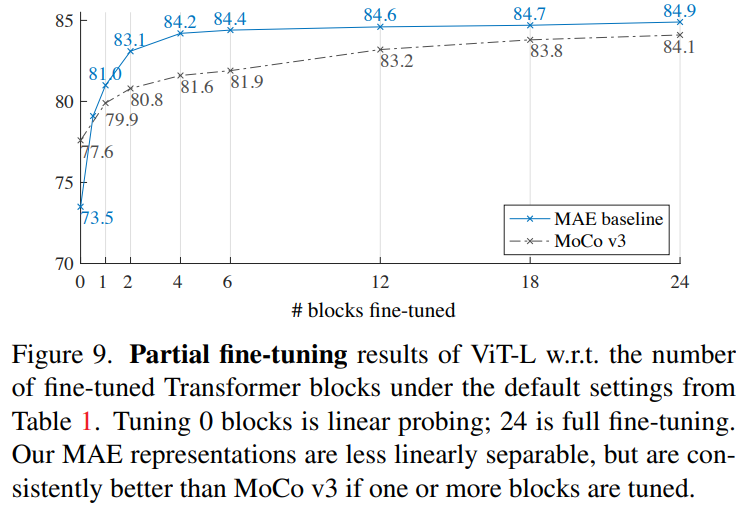
微调部分blocks,可以实现接近完全微调的精度。
迁移学习结果: