动机
- 现有预训练语言模型通常基于单词和句子的共现关系来训练模型,但忽略了训练语料库中存在的其它词汇、句法和语义信息,如命名实体、语义相似度等。
贡献
- 提出
ERNIE 2.0,该框架支持自定义的训练任务和增量方式的持续的多任务学习; - 构建了三种无监督语言任务验证所提出框架的有效性。
ERNIE
与以前方法相比,ERNIE 2.0引入大量预训练任务,以帮助模型有效学习词汇、句法和语义表示。
Continual Pre-training
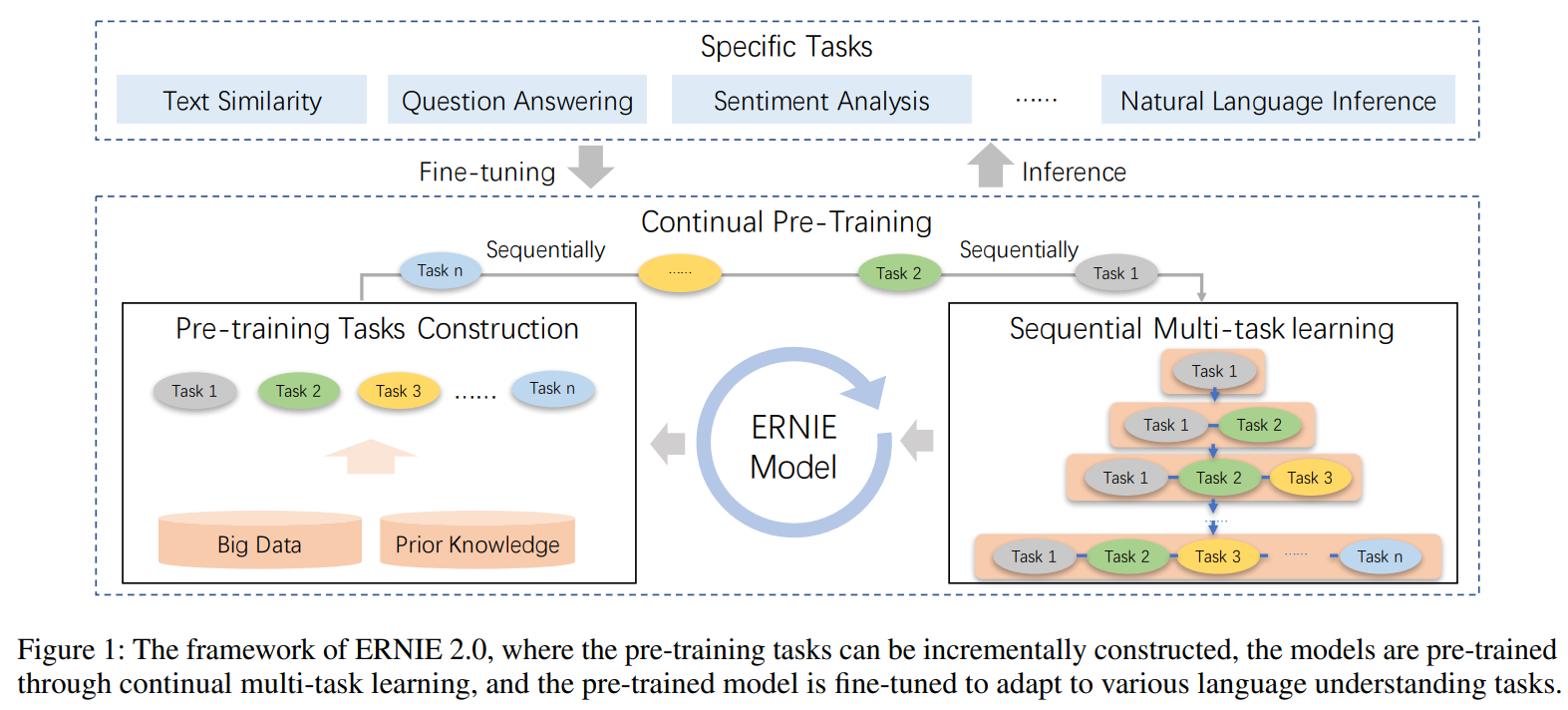
如图所示,包含两个步骤,首先利用大数据和先验知识构建无监督的预训练任务;其次通过持续多任务学习,对模型进行增量更新。
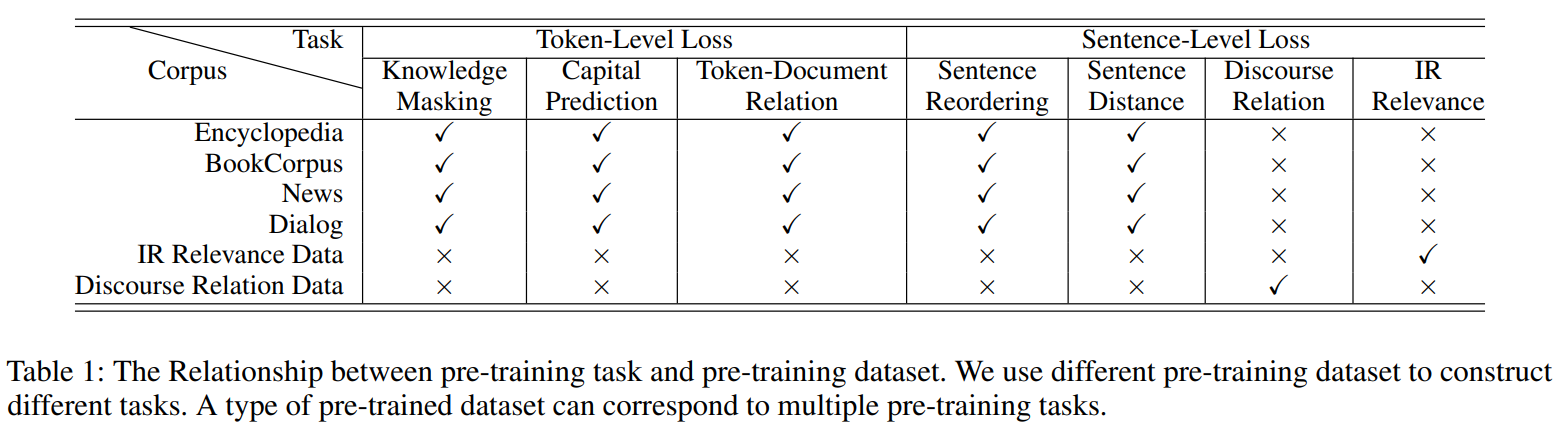
Pre-training Tasks Construction
本文分为三种不同类型的任务,包括单词感知任务、结构感知任务和语义感知任务。
Word-aware Pre-training Tasks
使模型能捕获词汇信息
Knowledge Masking TaskERNIE 1.0中使用的phrase mask和named entity mask,帮助模型学习上下文的依赖关系,使用该任务训练初始模型版本。Capitalization Prediction Task预测单词是否是大写。作者认为大写词通常具有特定的语义信息,对命名实体识别等下游任务有帮助。
Token-Document Relation Prediction Task预测
token是否出现在document中其它的段落中。作者认为出现在文档中多个部分的词语通常是常用词或者是文档的关键词,通过识别文档中频繁出现的单词,一定程度上能使得模型捕获文档关键词。
Structure-aware Pre-training Tasks
使模型能够捕获语料库的句法信息
Sentence Reordering Task对给定文档中的每个段落,以句子为单位划分为段,并随机打乱排列,让模型重新排列句子,即预测每个分段的原始位置。作者认为该任务能使模型学习文档中句子的关系。
Sentence Distance Task构建三分类模型,表示两个句子同文档相邻,表示两个句子同文档不相邻,表示来自不同文档。作者认为该任务可利用文档级信息学习句子距离。
Semantic-aware Pre-training Tasks
使模型能够学习语义信息
Discourse Relation Task预测两个句子之间的语义或修辞关系。参照
Sileo等人建立的数据为英语任务提供模型训练,并构建了一个中文数据集。IR Relevance Task利用搜索日志,构建三分类模型预测
Qurey-Title的相关性,表示强相关(用户输入查询后点击标题),表示弱相关(用户输入查询后,该标题在搜索结果中,但未点击),表示不相关(查询和标题完全随机)。作者认为该任务有助于标题自动生成和文本摘要等任务。
Continual Multi-task Learning
ERNIE 2.0旨在从许多不同的任务中学习词汇、句法和语义信息。难点:
- 如何在不忘记之前所学知识的情况下持续训练任务;
- 如何以有效的方式预训练这些任务。
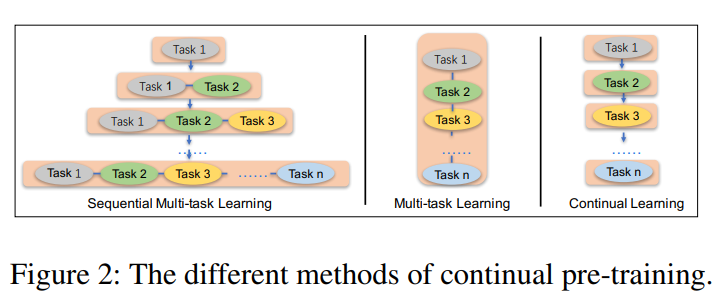
上图显示了本文的方法与多任务学习和持续学习的差异。当新任务出现时,本文方法首先使用先前学习的参数初始化模型,然后将新引入的任务和原始任务同时训练。每个任务都训练个迭代次数,在不同阶段时为每个任务分配训练时的迭代次数(🤔️看下面的表格,每个阶段,并不完全是所有任务一起训练,而是有时间间隔的加入先前任务?)。

上图为本文每个阶段时的多任务学习框架,使用Transformer Encoder编码上下文特征。框架中包含两种类型的损失,一种是句子层面的损失,一种是表征层面的损失,在预训练时,多个损失函数相结合以更新模型。
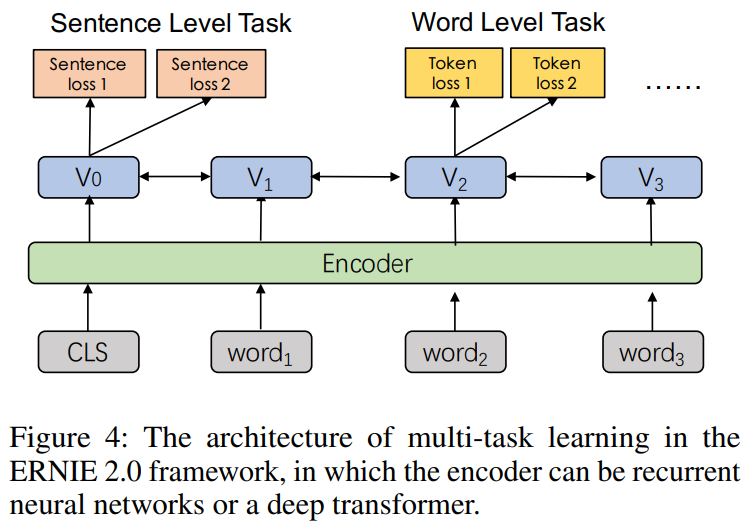
另外,如上图所示,对输入额外增加task embedding,对不同任务分配从的id。在微调阶段,可以使用任意任务的id初始化模型。
训练过程
数据集:
详细参数:
base模型包含层,有个注意力抽头,隐层大小为;large模型包含层,有个注意力抽头,隐层大小为。
使用优化器,一个batchsize包含个tokens。英文模型学习率为,中文模型学习率为。在每个预训练任务的前个迭代中进行warmup,每个预训练任务均被训练直到预训练任务的指标收敛。
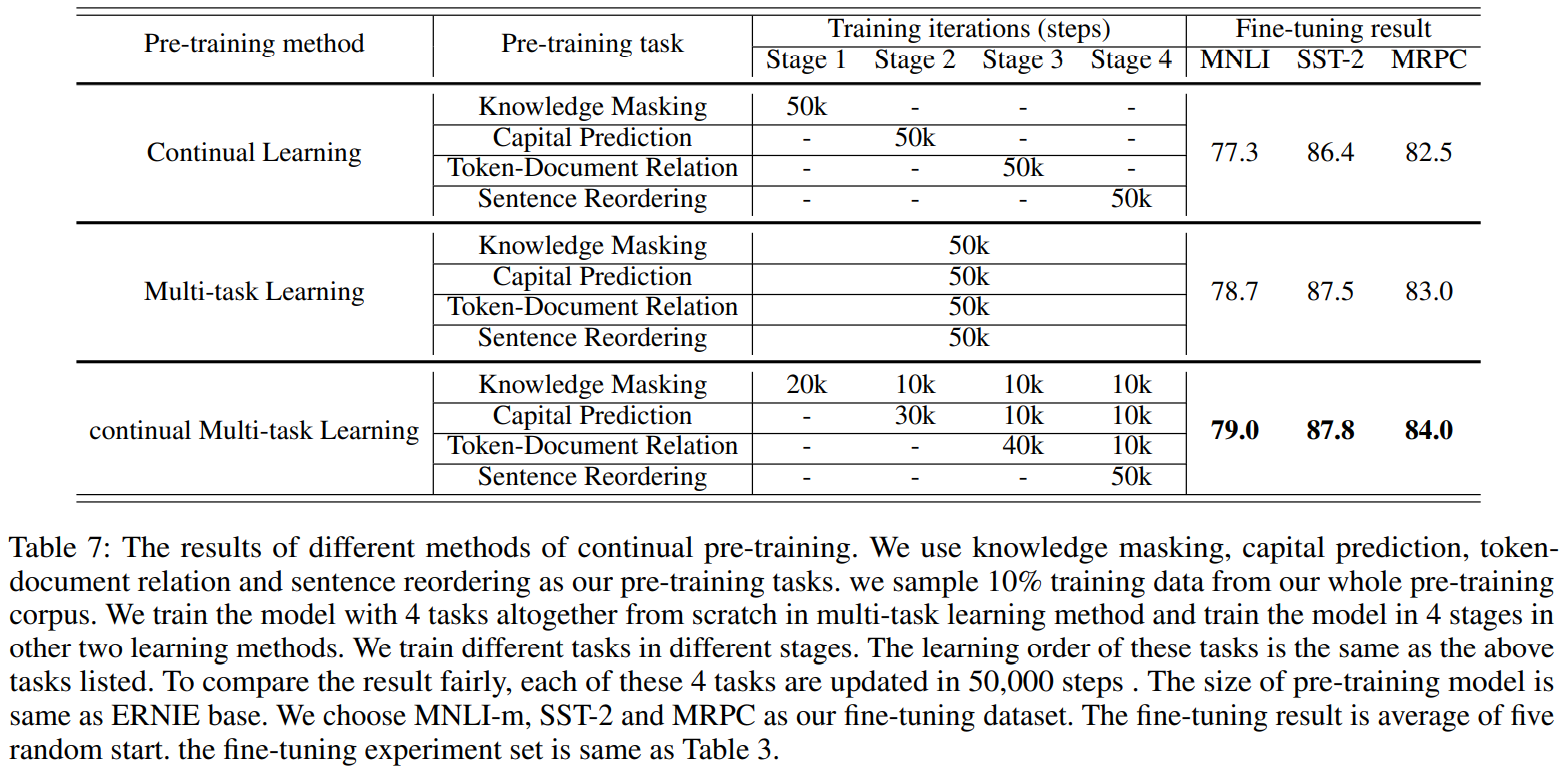
部分实验结果
持续多任务学习的有效性: