动机
- 现有的预训练语言模型通常在纯文本上训练,没有引入
linguistic knowledge和world knowledge; - 大多数模型以自回归方式进行训练,在下游语言理解任务上表现较差。
贡献
- 提出
ERNIE 3.0,该框架融合了自回归网络和自编码网络,使得训练好的模型能够适应自然语言理解和生成任务,具有zero-shot、few-shot、fine-tuning等能力; ERNIE 3.0使用纯文本和大规模知识图构成的语料库训练百亿参数模型,在一系列自然语言理解和生成任务上优于现有模型。
ERNIE
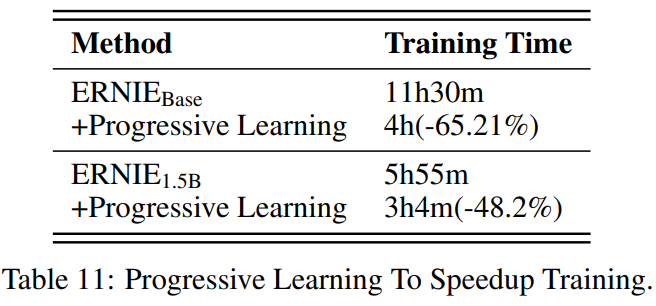
如图所示为ERNIE 3.0的预训练框架。参照多任务学习的框架,作者认为nlp的不同任务范式依赖于相同的底层抽象特征(如:词汇信息和句法信息),但顶层具体特征是特定于任务的,如自然语言理解任务具有学习语义连贯的倾向,自然语言生成任务期望获得更多的语境信息。
此外,延续ERNIE 2.0引入的连续多任务学习。对于不同类型的下游任务,针对不同的任务范式,结合预训练的共享网络和相应的特定任务网络的参数进行初始化,再执行后续处理。
Framework
Universal Representation Module
图中灰色部分,通用表示网络扮演着通用语义特征提取器的角色,其参数在各种任务范式中共享。
使用Transformer-XL作为主干网络,该通用表示模块在所有任务范例中共享参数。特别注意的是,在控制attention mask矩阵时,memory module仅对自然语言生成任务有效。
Task-specific Representation Module
图中蓝色和绿色部分,任务特定表示网络承担着提取任务特定语义特征的功能,其参数由任务特定目标学习。
使用多层Transformer-XL,用于捕获不同任务范式的语义表示。图中蓝色部分为自然语言理解任务(NLU),使用双向建模网络;绿色部分为自然语言生成任务(NLG),使用单向建模网络。
Pre-training Tasks
ERNIE 3.0通过Knowledge Masked Language Modeling训练NLU网络,提高词汇信息捕获能力;训练Sentence Reordering和Sentence Distance,增强句法信息捕获能力;最后利用Universal Knowledge-Text Prediction对模型进行优化,提高知识的记忆和推理能力。同时,ERNIE 3.0使用Document Language Modeling训练NLG网络,以适应各种生成样式。
Word-aware Pre-training Tasks
ERNIE 1.0的Knowledge Masked Language Modeling;Document Language Modeling:传统预训练模型如GPT。
Structure-aware Pre-training Tasks
ERNIE 2.0的Sentence Reordering;ERNIE 2.0的Sentence Distance。
Knowledge-aware Pre-training Tasks
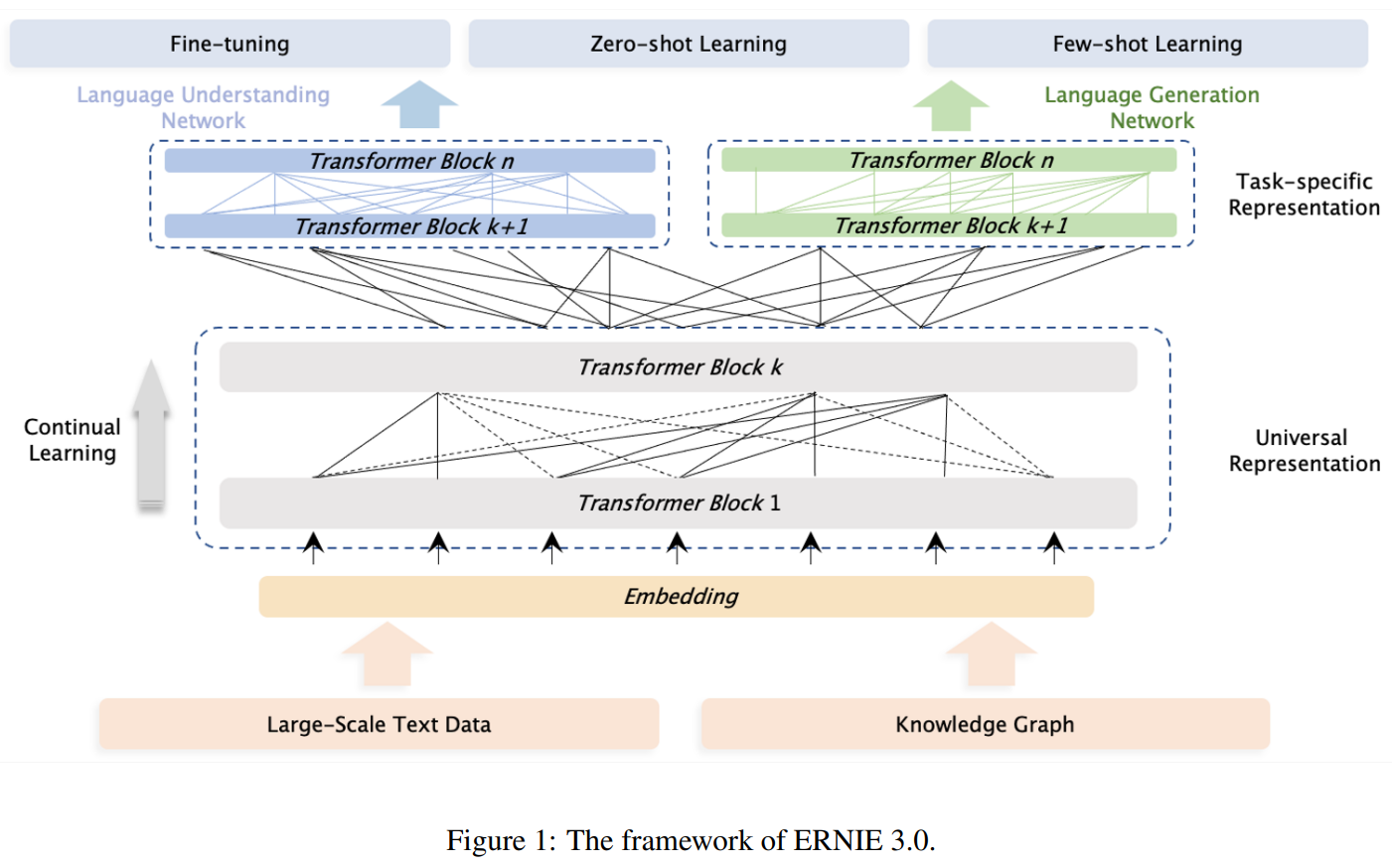
Universal Knowledge-Text Prediction给定知识图中的一对三元组和
encyclopedia中对应的句子,随机mask三元组中的关系或句子中的单词。具体而言,给定encyclopedia中的一个文档,首先通过文档标题(头实体或尾实体被提及)在知识图中找到候选三元组,然后通过文档句子(同一句中头实体和尾实体都被提及)在候选三元组中选择三元组。该任务不仅需要考虑句子中的依赖关系,也需要考虑三元组中的逻辑关系。
Pre-training Process
训练策略:对输入序列长度、批大小、学习率、dropout rate和training layer使用warm-up策略提高训练的收敛速度。
数据集:构建了个不同种类的中文文本语料库(4TB目前最大)。
详细参数:
通用表示模块包含层,有个注意力抽头,隐层大小为;任务特定表示模块包含层,有个注意力抽头,隐层大小为。
使用GeLU激活函数,最大序列长度为,语言生成的内存长度为。使用优化器,权重衰减为,batchsize为,学习率为,在前个迭代中进行warmup和线性衰减,每个预训练任务均被训练直到预训练任务的指标收敛。在前个迭代中,使用渐进式学习在预训练的初始阶段加速收敛。
部分实验结果
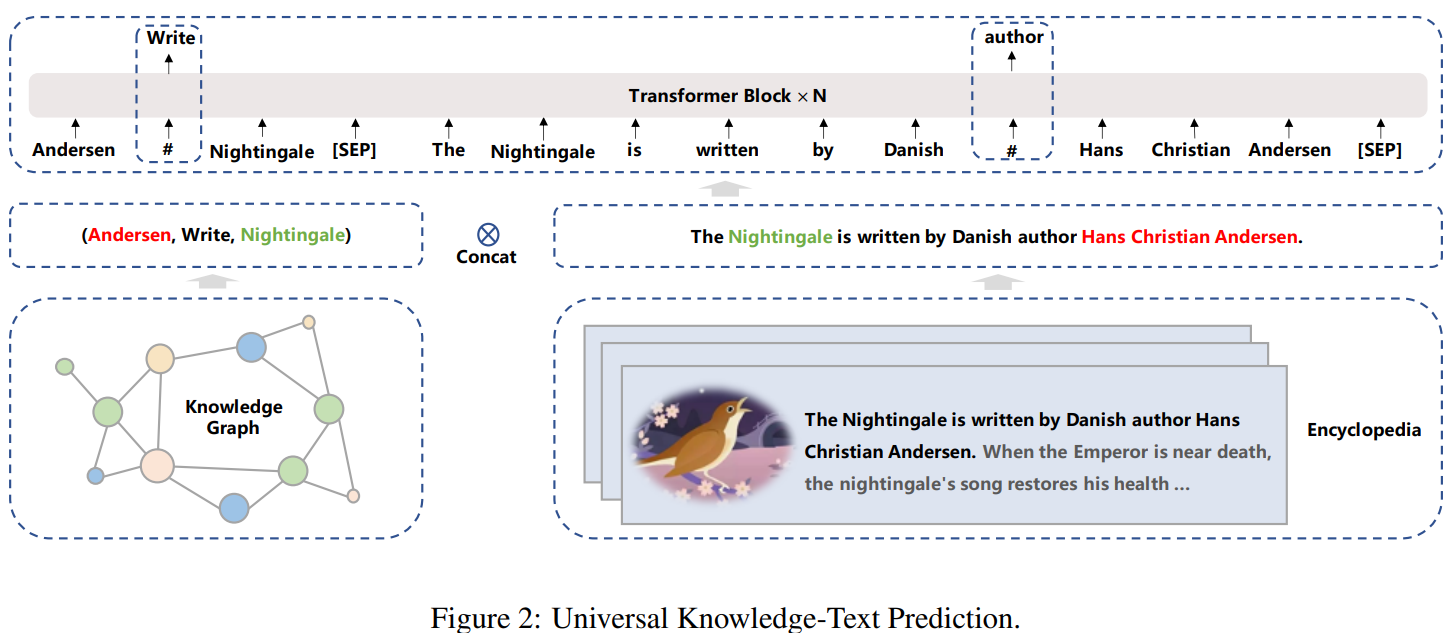
任务特定网络的有效性,说明区分不同任务的必要性:
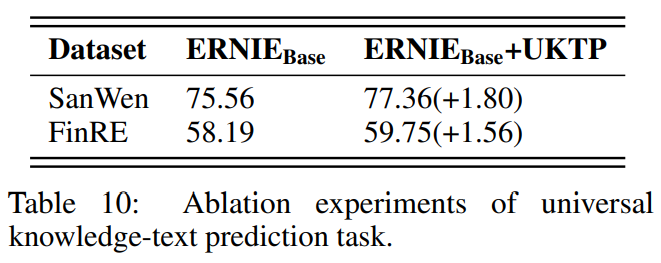
Universal Knowledge-Text Prediction任务对预训练的影响:
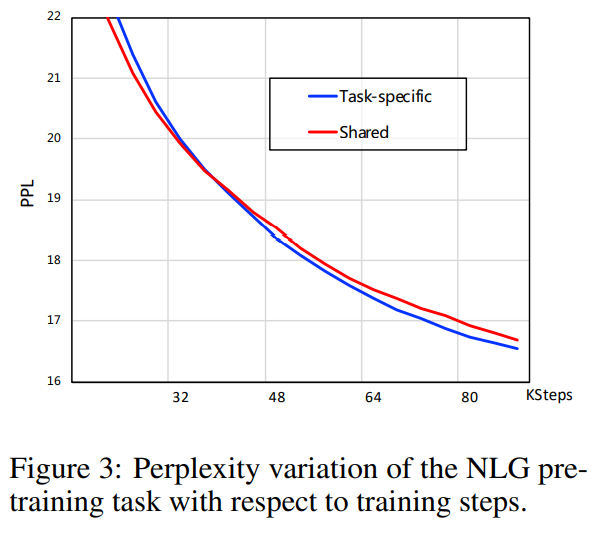
渐进式学习的收敛提升: