动机
- 现有的预训练语言模型大多只是通过上下文预测缺失单词,而没有考虑句子中的先验知识。
贡献
- 提出一种新的方法
ERNIE,该方法增加knowledge masking策略,使用phrase-level和entity-level的策略,将短语和实体的先验知识和长距离的语义依赖隐式地加入训练过程中; ERNIE基于异构数据(更多样性的数据)进行训练,在中文nlp任务上的表现优于目前的方法,并通过实验验证ERNIE具有更好的知识推理能力。
ERNIE
Transformer Encoder
ERNIE使用跟GPT、BERT一致的encoder,即Transformer encoder。对于中文语料,使用WordPiece去标记中文句子,并使用在CJK Unicode范围内的字符。对于给定的token,其输入与BERT一致,即token, segment, position embedding构成。每个序列的第一个token为[CLS]。
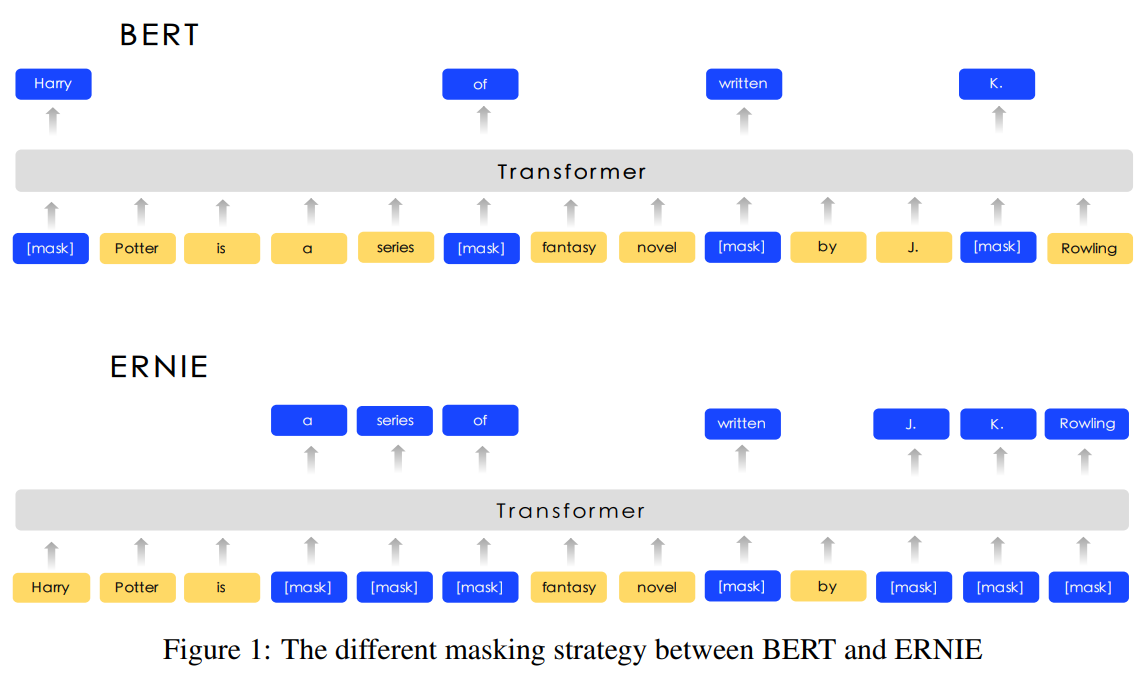
Knowledge Integration
本文意欲使用先验知识来增强预训练模型,但没有直接添加知识嵌入,如图所示,提出一种多阶段的知识掩膜策略,将短语和实体知识集成到语言表示中。

Basic-Level Masking即将句子视为基本的语言单元构成的序列。对于英语,基本的语言单元是单词,对于汉语,基本的语言单元是汉字,在训练中,随机屏蔽的基本语言单元。基于
basic-level mask,可以得到基本的单词表示,但很难建模高层的语义知识。Phrase-Level Masking短语定义为由小部分的单词或字符构成的概念单元。对于英语,使用词汇分析和
chunck工具获取句子中短语的边界,对于中文,则使用语言相关的切分工具获取单词/短语信息。在phase-level mask阶段,依旧使用基本语言单元作为输入,但不随机屏蔽基本语言单元,而是在句子中随机选取几个短语,对同一短语中的所有基本单元进行屏蔽和预测,由此将短语信息编码到word embedding中。Entity-Level Masking命名实体包含人员、地点、组织和产品等。在
phrase-level mask阶段,首先分析句子中的命名实体,然后对实体中所有的槽位进行屏蔽和预测,使用更丰富的语义信息进行学习。
训练过程
采用与BERT-base一样的模型,即层encoder,维隐单元及个注意力头。
数据集:Chinese Wikepedia(21M)、Baidu Baike(51M)、Baidu News(47M)、Baidu Tieba(54M)
此外,对汉字进行繁体到简体的转换,对英文字母进行大写到小写的转换,并在模型中使用了个unicode字符的词汇表。
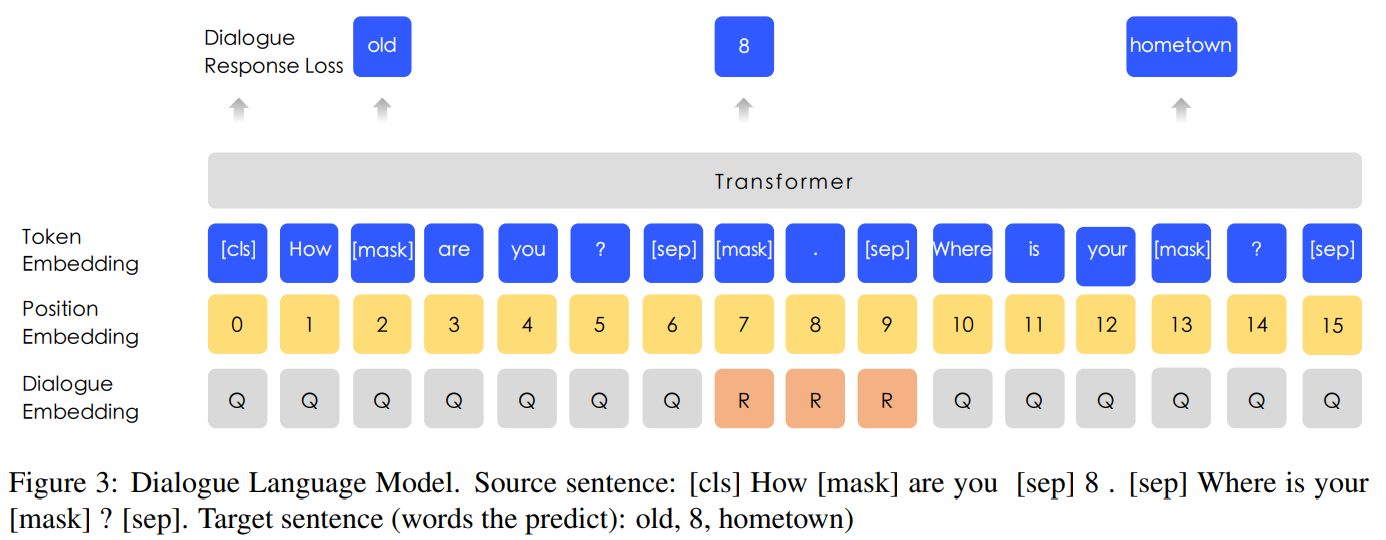
训练方面在Baidu Tieba数据集上引入DLM(Dialogue Language Model)任务,如图所示,增加表示多回合对话的embedding(有QRQ、QRR、QQR等形式,其中Q表示query,R表示response)。MLM任务随机mask一部分query和response中的单词并预测,DLM任务通过随机选择的句子替换原有的query和response来生成假样本,然后用于模型判断真假。DLM任务能够增强模型学习语义表达的能力,在训练中与MLM任务交替训练。
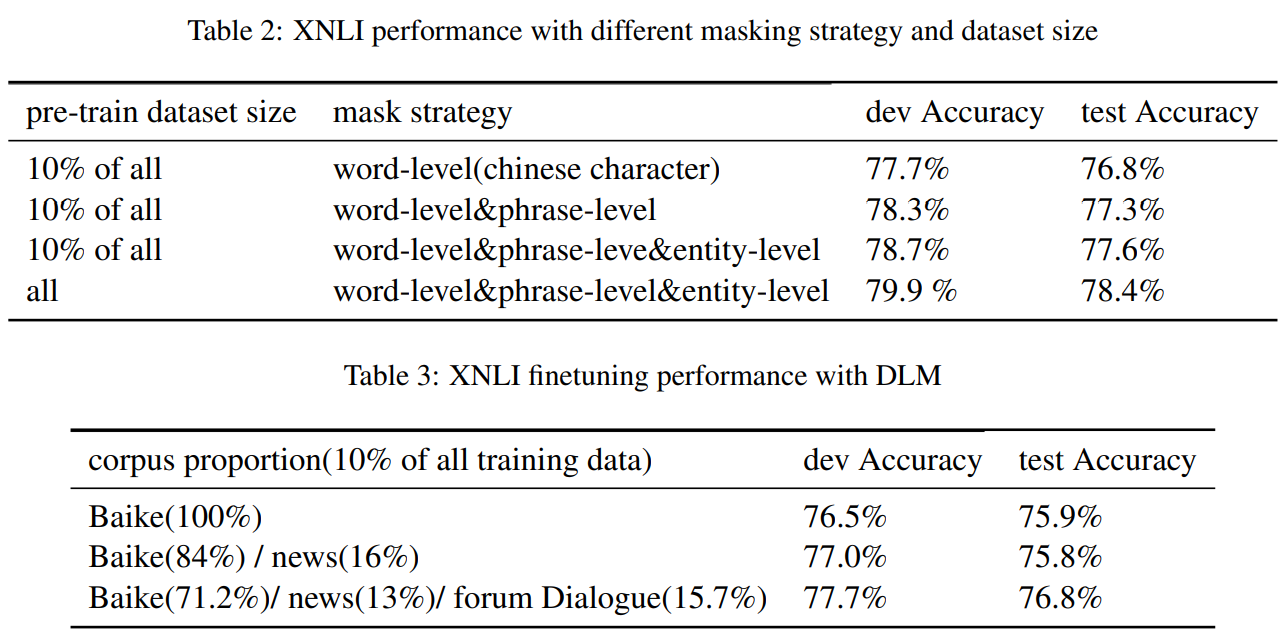
部分实验结果
Ablation Study:
Knowledge Masking Strategies在XNLI的测试集上提升;DLM能带来正向收益;
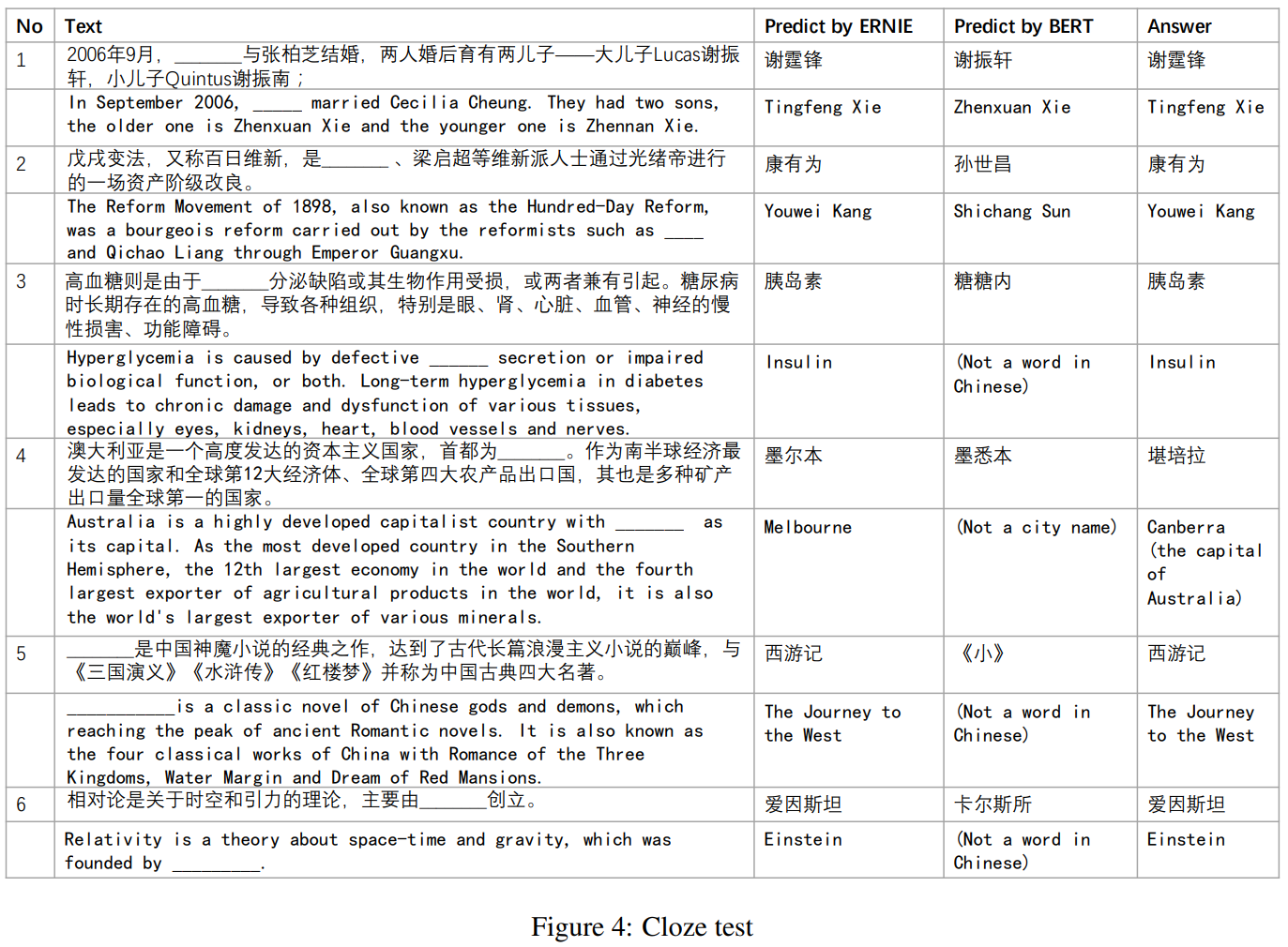
Cloze Test:
下图显示ERNIE能学习到一些远程依赖等高级语义信息。