动机
- 现有的预训练语言模型仅使用单向的语言模型来学习通用的语言表征,限制了预训练模型表征的效果;
贡献
- 提出了一种新的语言表示模型
BERT(Bidirectional Encoder Representations from Transformers),其使用masked language model去训练深度双向表征,论证了双向预训练对语言表征的重要性; - 仅通过一个额外的输出层,即可对预训练的
BERT进行微调,且刷新了个任务的当前最优结果。
BERT
BERT有两个阶段:预训练和微调。在预训练时,模型基于未标记的数据进行训练;在微调时,首先使用预训练参数进行初始化,然后使用下游任务中的标记数据对所有参数进行微调。
模型结构
BERT的模型结构基于multi-layer bidirectional Transformer encoder。定义Transformer block的数量为,隐层大小为,而self-attention head的数量为。与GPT比较,BERT使用bidirectional self-attention,而GPT使用constrained self-attention(每个token仅关注其左边的上下文)。
在文献中,双向Transformer被称为Transformer encoder,而只关注左侧语境的版本因为可以用于文本生成而被重新定义为Transformer decoder。BERT、GPT和ELMo之间的比较如图所示:
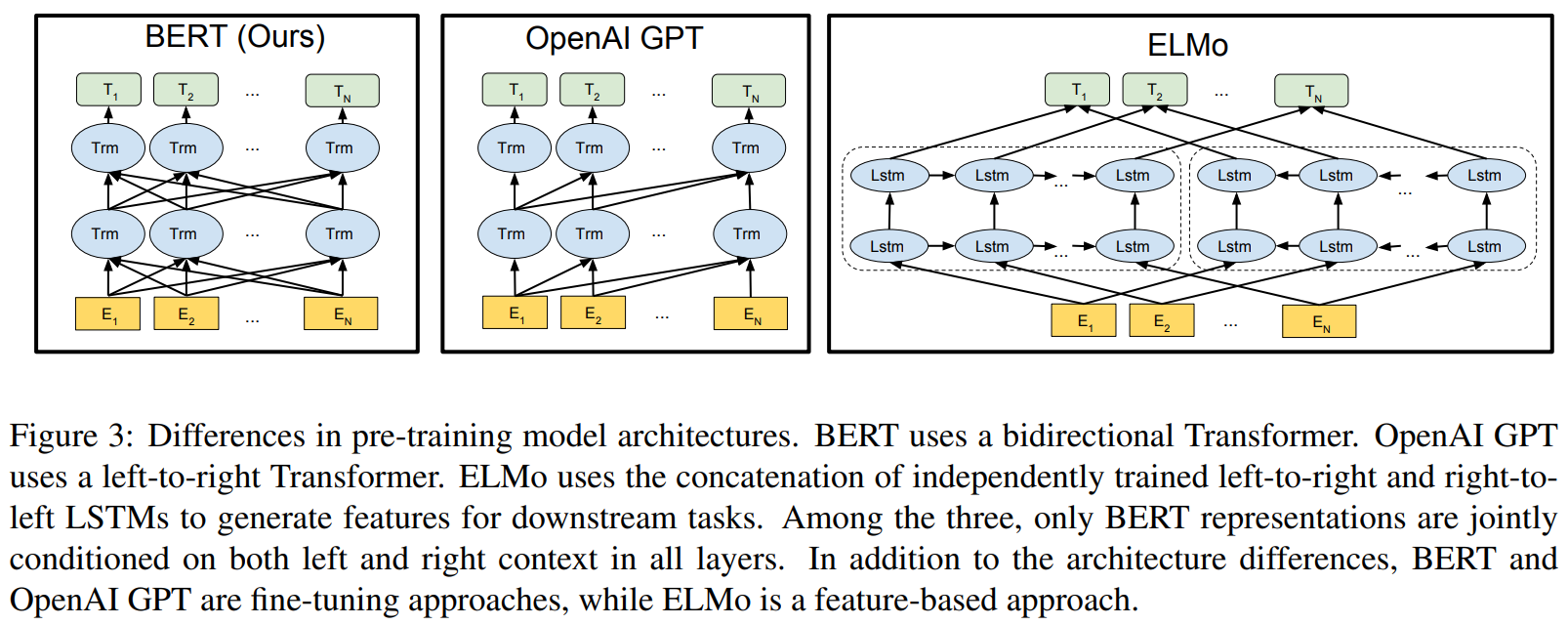
如上图,BERT使用双向Transformer,GPT使用从左到右的Transformer,ELMo使用独立训练的从左到右的LSTM和从右到左的LSTM,其中,只有BERT在所有层同时受到左右语境的限制。
输入表示
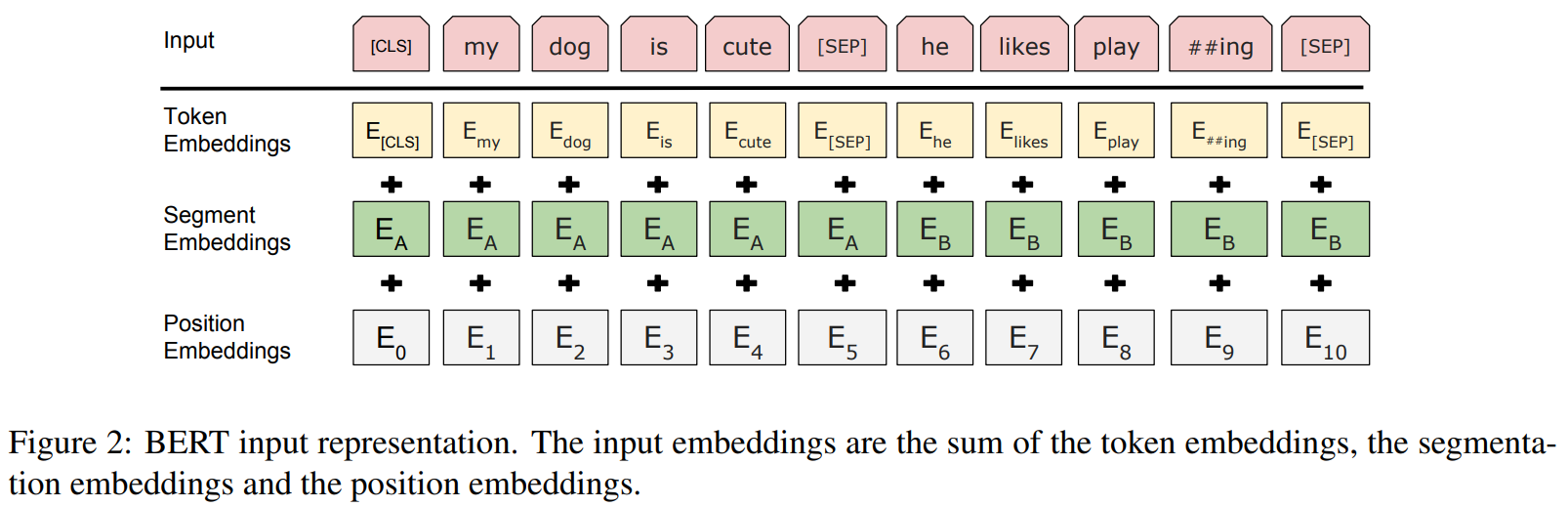
为了使BERT适应下游任务的输入,BERT的输入形式可以表征单个句子或一对句子。在本文中,作者定义sentence为连续的任意跨度的文本,sequence表示输入BERT的token序列,可以是单个sentence或一对sentence。输入表示由三部分组成,包括token embedding,segment embedding,position embedding。细节如下:
- 使用含个
token词表的WordPiece embedding,##表示拆分的token; - 每个
sequence的第一个token是classification token([CLS]),该token在Transformer的输出被用作分类任务中该sequence的表征,对于非分类任务,该隐藏状态被忽略; - 句子对则被拼接在一起形成一个单独的
sequence,一是使用特殊token([SEP])将其分开,二是为每个token添加一个可训练的segment embedding来区分属于句子或者句子;对于单句输入,则只使用句子的embedding; - 使用可学习的
position embedding,支持的序列长度最长为。
预训练阶段
本文不使用传统的从左到右或从右到左的语言模型预训练,而是使用两个无监督任务对BERT进行预训练。
Masked LM
类似于随机划分窗口的
CBOW,实现了双向的信息获取
直觉上,深度双向模型比从左到右的模型或从左到右模型结合从右到左模型的浅层连接更强大,但标准条件语言模型只能单向训练,因为双向条件作用将允许每个单词间接see itself,使得在多层上下文中可以轻松预测。
本文采用随机mask一定比例的输入tokens,然后预测这些masked tokens,该任务被称为Masked LM(MLM)或完形填空(Cloze)。在这种情况下,masked tokens对应的最后隐层特征被输入到与词表对应的softmax,目的是生成masked tokens对应的词汇表中的单词。在本文,对每个序列中的tokens随机mask,与denoising auto-encoder相比,BERT只是让模型预测被masked的单词,而不是重建整个输入。
虽然该方法可以获得双向预训练模型,但仍具有两个缺点:
预训练和微调时的不匹配,如
token[MASK]仅出现在预训练期间,而从不出现在微调阶段。解决方法时对随机选择的的token,不是总用[MASK]替换,而是采用如下操作:- 的情况下,使用
[MASK]替换被选择的token; - 的情况下,使用随机
token替换被选择的token,发生概率只占也不会过度损害模型的语言理解能力; - 的情况下,保持被选择的
token不变,使表示偏向于实际观察到的词。
这使得
Transformer encoder不知道哪些token已经被随机token替换或将预测哪些token,被迫保持每个输入token的上下文表征。- 的情况下,使用
每批数据中只有的
token被mask用来预测,意味着模型需要更多的时间收敛,但实验效果远超过它增加的预训练成本。
Next Sentence Prediction (NSP)
由于许多下游任务(如问答、自然语言推断)等基于理解两个sentence之间的关系,而语言建模无法直接捕捉。
本文训练一个NSP的二分类任务,即对于每个训练示例,选择句子A和句子B,概率的情况下,B是A实际的下一个句子,标记为IsNext,概率的情况下,B是语料库中的随机句子,标记为NotNext。最终预训练模型训练结果可达到的准确率。
训练过程
预训练过程
数据集:BooksCorpus,English Wikipedia(只提取文本段落),文档级别的语料库提取长的连续序列。
输入样本:对于每个输入序列,从语料库中采样两段文本,其中第一个句子为A,另一个句子为B。其中,的情况B是A实际的下一个句子,的情况B是语料库中的随机句子。而MLM时,使用WordPiece序列化句子,并以的概率对token进行mask。
训练细节:batchsize为,token长度为,使用训练次迭代,最大学习率为,在前步进行warmup,然后线性衰减。的权重衰减为,同GPT,网络层使用的dropout,及Gelu激活函数。损失函数为MLM的最大似然和NSP最大似然的平均值。
微调过程
对于不同的任务,对最后一层特征的使用方式不同,如图:
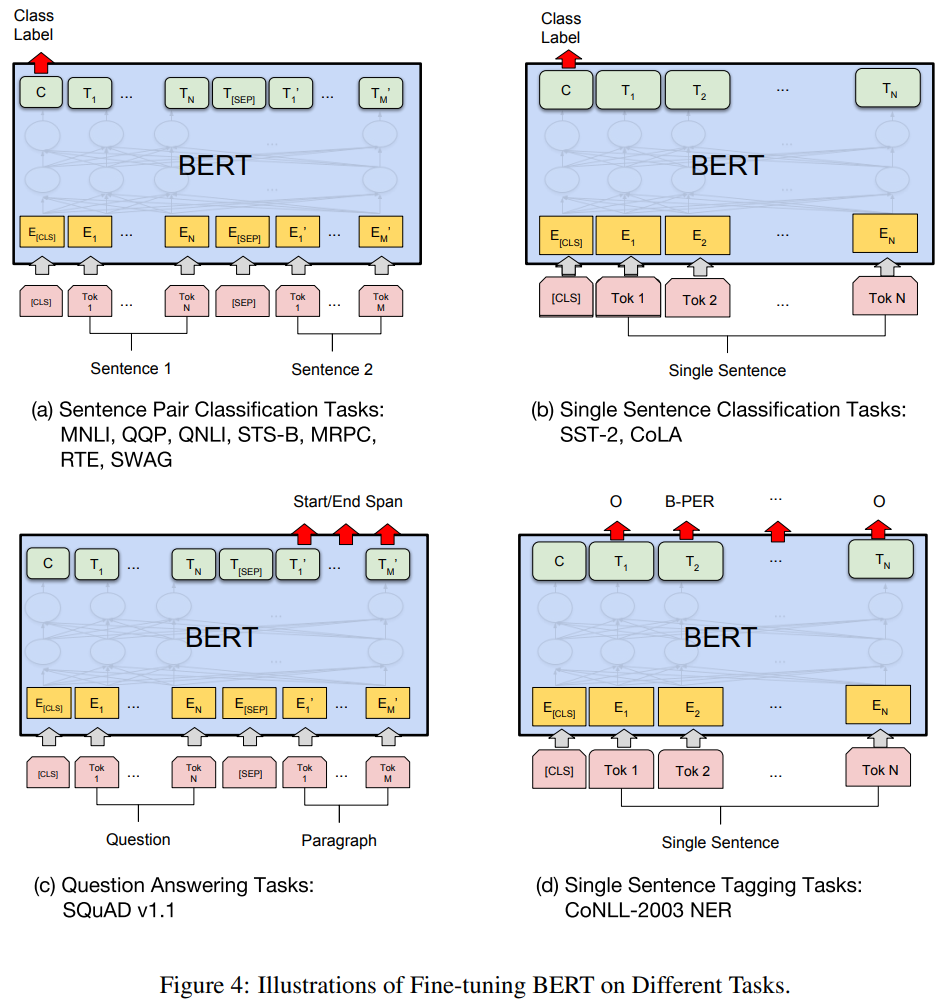
其中,和是序列级任务,和是标记级任务。图中表示输入embedding, 表示第 个token的上下文表示,[CLS]表示分类输出,[SEP]用于分隔两个序列。
BERT和GPT训练过程的比较
- 预训练数据集不同:
GPT使用BooksCorpus(800M),BERT使用BooksCorpus(800M)和Wikipedia(2500M); - 输入形式不同:
GPT仅在微调时使用句子分隔符[SEP]和分类标记[CLS],BERT在预训练时也使用[SEP],[CLS]和A/B embedding; - 预训练的训练时间不同:
GPT使用含个词的batchsize训练1M步,BERT使用含个词的batchsize训练1M步; - 微调的学习率不同:
GPT微调时学习率均为,BERT对于特定任务根据验证集选择最优学习率。
部分实验结果
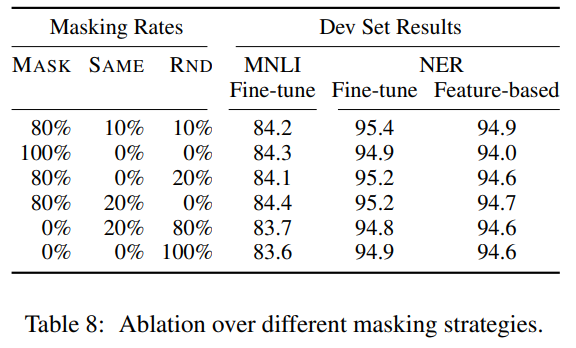
Ablation Study:
NSP和MLM对预训练模型结果影响很大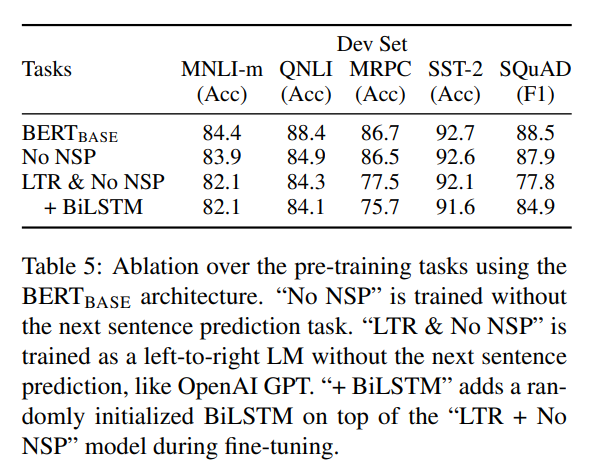
图中,
No NSP表示不使用NSP训练模型,LTR & No NSP表示像GPT使用从左到右的语言模型并不使用NSP训练模型,+ BiLSTM表示在LTR & No NSP模型微调时添加一个随机初始化的BiLSTM层。模型越大,语言模型表征能力越强,对下游任务提升越大
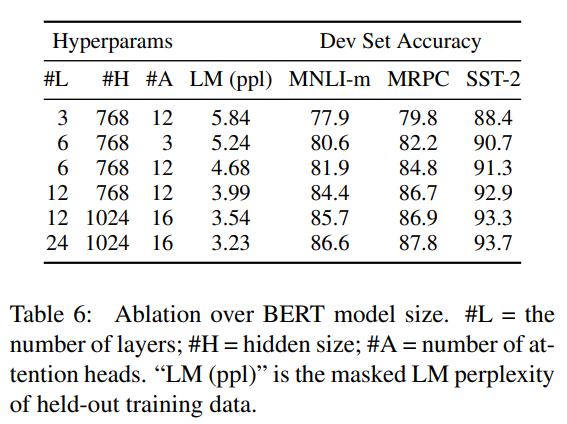
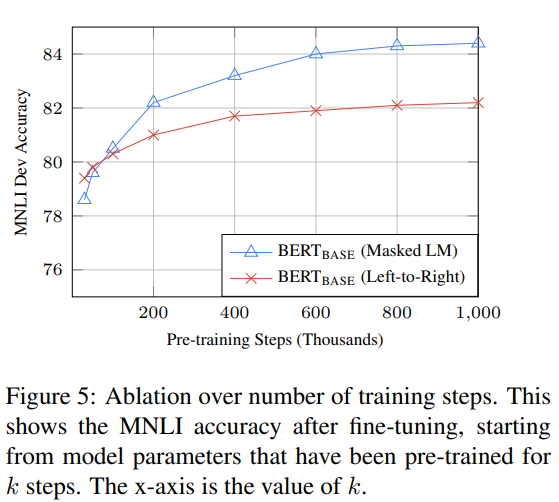
训练步数的影响
BERT需要更长时间的预训练来实现更好的微调结果;MLM相比LTR(从做到右的模型)收敛速度更慢,但准确性更高;
从BERT预训练模型提取固定特征(Feature-based),进行下游任务训练的结果: