
动机
- 人类的视觉认知能力优于人工神经网络,如果向他们展示某一对象的单一视觉实例,通常可以归纳出对象的不同属性,并进行不同属性的组合得到新的对象;
- 为了帮助机器对视觉对象属性的认知,现有的解纠缠表征学习通常将视觉样本映射到一个潜在空间,分离属于不同属性的信息,但这些方法通常只针对单个样本,而不是一组样本进行对比或推理;
贡献
- 提出了一个新的学习框架:组监督学习(
Group-Supervised Learning, GSL),它将数据集转换为多边图(multigraph),并从语义相关的一组样本中学习和合成具有可控属性的样本; - 设计了一个
GSL的实例:Group-supervised Zero-shot Synthesis Network(GZS-Net),依靠重建损失和一组图像进行训练,结果优于现有的可控图像生成方法; - 提供了一个新的数据集:
Fonts,它包含万张具有不同属性的图像。
组监督学习
数据集形式
形式上,GSL允许的数据集包含张样本,其中每个样本包含个属性,每个属性值为一个可计数集合的成员,有,例如:代表前景颜色,代表背景颜色。
通过multigraph辅助任务
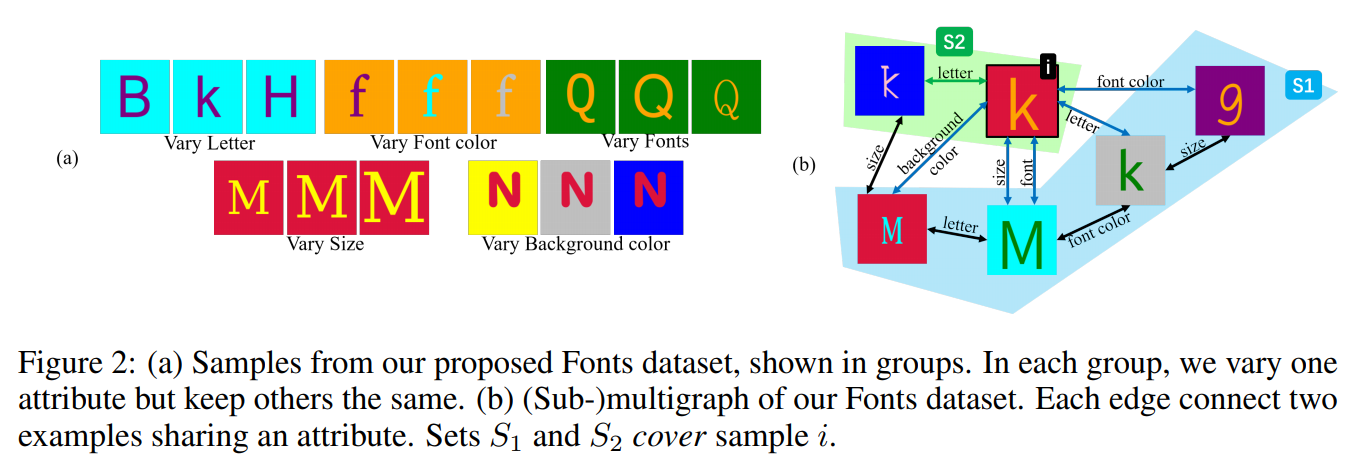
对于给定包含张样本的数据集,定义一个multigraph,节点集为,两个节点()之间通过边连接:
即表示节点和节点具有相同的属性的个数。
定义:给定节点集合和节点,如果节点的每个属性值都至少在的一个成员中,则称集合覆盖节点,即:
当获得时,存在两种互斥的情况:如下图,要么,要么,图中分别为绿色和蓝色。绿色通常适用于小集合,例如对于所有的,均有;假设图中节点的图像特征没有给出,则可以在集合中搜寻,假设如果成立,则包含了足够的信息来合成的特征,即使。(即:即使集合中没有包含节点,但包含了合成所需要的各种属性的信息)
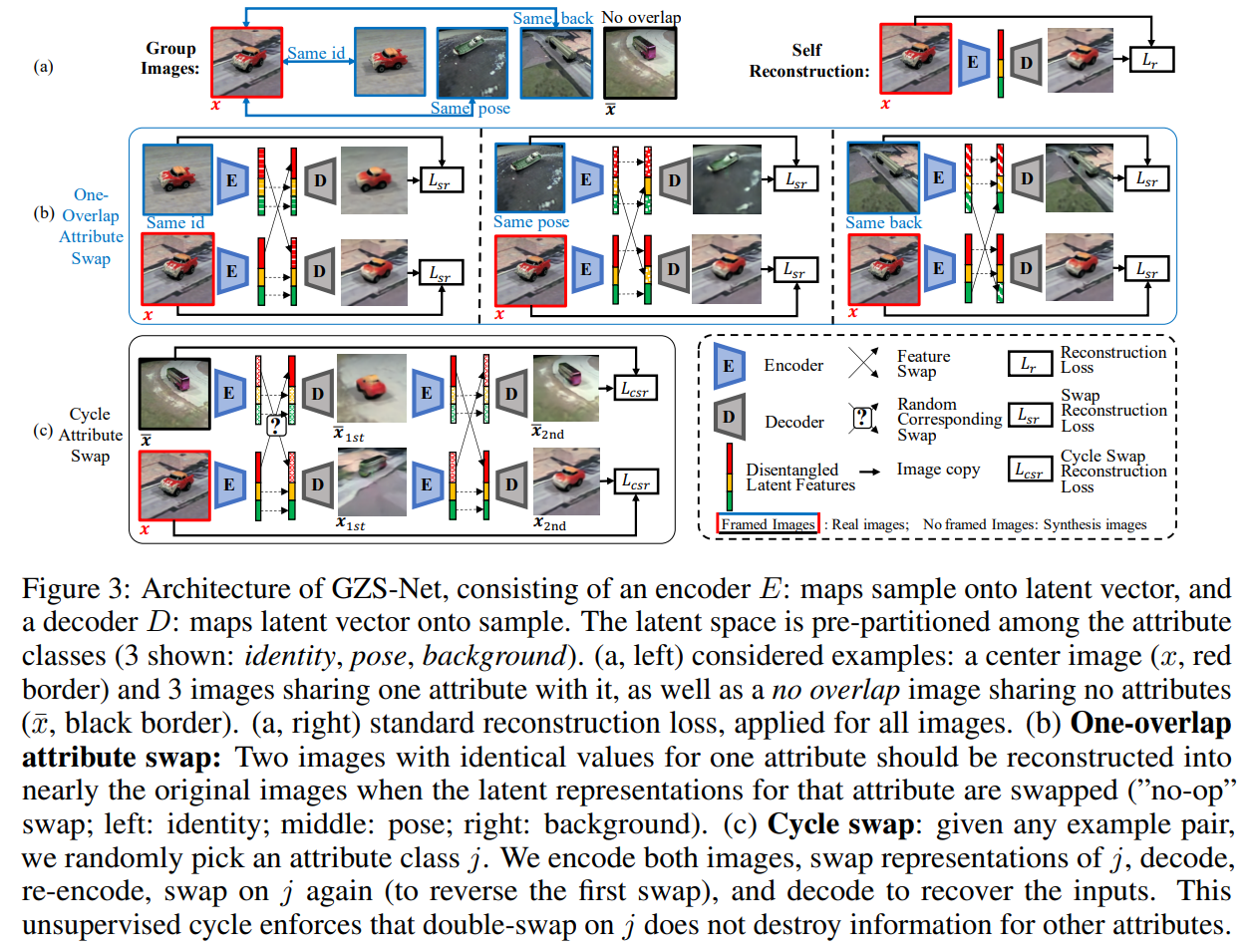
GZS-NET
目标:生成具有整体语义的新图像
网络结构:包含一个编码器和一个解码器,编码器将图像映射为隐特征,解码器将隐特征映射回图像。隐特征按照预先划分的属性进行分块:如下图的身份、姿态、背景。
输入:包含一组图像和其对应的关系图,即一对图像之间具有相同属性的标签
训练:包含三个阶段,每个阶段均采用重构损失
self-reconstruction:即对于每张图像按照自编码器的训练方式使用重建损失训练,这个步骤可以看作是一个正则项,以保证输入图像所有的信息经编码器映射到了隐特征中,避免了信息丢失。overlap attribute swap:对于在multigraph中有边相连的两个图像(即有属性相同的图像对),经过编码器得到属性特征,每次交换一个具有相同属性的特征,希望其交换后生成的图像跟原图应该相同。这个过程可以看作是利用multi-graph图像之间的关系,使得网络学习挖掘图像之间属性的相似性,并通过交换实现可控。(note:需要swap所有属性对应的特征,即图中红,黄,绿三部分都需要交换,以此避免网络将所有信息存储到不被交换的区域)cycle attribute swap:对于任意的一对图像,通过编码器提取属性特征,随机选择一个属性进行交换,并进行解码-编码得到属性特征,此时反向交换,希望生成的图像与原图像一致。这个过程可以看作是间接约束属性解纠缠,对某个属性交换时不会破坏其它属性的信息。最后总的损失函数为:
部分实验结果
数据集:
Fonts数据集:字母、字体、背景颜色、字母颜色、字母大小ilab-20M数据集:车辆id、姿态、背景RaFD数据集:身份、姿态、表情
评价方式:
Exhaustive Search(ES):VAE方法没有明确确定隐编码与属性之间的对应关系,文章将所有张训练样本经过编码器得到个维的隐特征,将所有隐特征按照的方式划分为训练集和测试集,并将维隐特征随机均匀划分为5个属性的分区,即认为每个维度代表一个属性分区,再对每个分区训练一个MLP将属性特征映射到已知的属性值,并在测试集上进行测试。最后选取具有最高平均性能的划分方式,在swap交换对应的分区特征。Direct Supervised(DS):对于自动编码器,使用属性标签有监督地训练隐特征到已知属性的映射。即对于维的隐特征,平均划分为个分区,对应于一种属性,使用已知的属性值进行交叉熵损失,联合重构损失一起训练。
定性结果



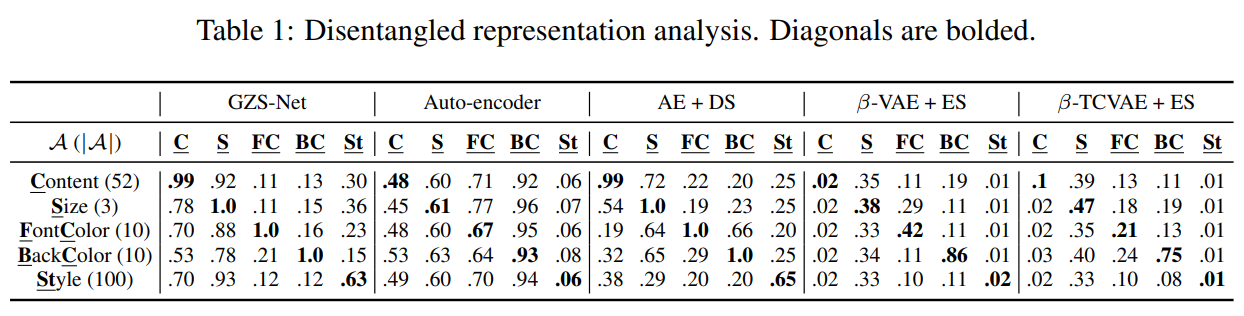
定量结果
使用每个属性在隐特征中对应维度的信息预测所有属性的标签,完美解纠缠的模型应接近单位矩阵。具体而言,将数据集中的测试集按照的比例划分为训练集和测试集,对每个属性,根据真实的属性值训练一个分类器,然后对测试集测试每个属性的准确性。
使用MSE和PSNR评估生成质量

将GSL用于数据增强,即通过GSL将原本不平衡的数据集增强为,并提升下游分类任务的准确率。
