
动机
- 最近的一系列基于图像的无监督表征学习的方法均是最大化同一图像的不同视图的相似性,视频可以在各种变化因素(如运动、遮挡、光照等)下提供视觉内容的自然增强,本工作旨在将基于图像的方法推广到时空中;
- 视觉内容通常会在视频中的一段时间持续存在,可能包含一个动作(一个人跳舞),一个物体(一个人完成跑步到走路的过渡),一个场景(一个有人在移动的房间),这种持续性覆盖不同的时间跨度,具有不同层次的视觉不变性(动作,物体,场景)。文章鼓励同一视频的不同
clip中的视觉表示是相似的,并在MoCo、SimCLR、BYOL和SwAV中都能很好地工作。
贡献
- 提出了一种在视频上的无监督时空表征学习的大规模研究,通过对四种基于图像的框架的分析,这些方法都具有共同的目标:学习空间输入图像的跨不同视图的不变特征。文章将这一思想推广到时域,核心思想是学习一个时空编码器,在同一视频中多个不同的
clips中提取的嵌入特征在时空上是持续性的; - 文章方法的目标是鼓励同一视频中的时间持续性特征,并且在1)不同的无监督框架、2)预训练数据集、3)下游数据集、4)骨架网络上都取得了比较好的结果。
temporal-persisent特征学习
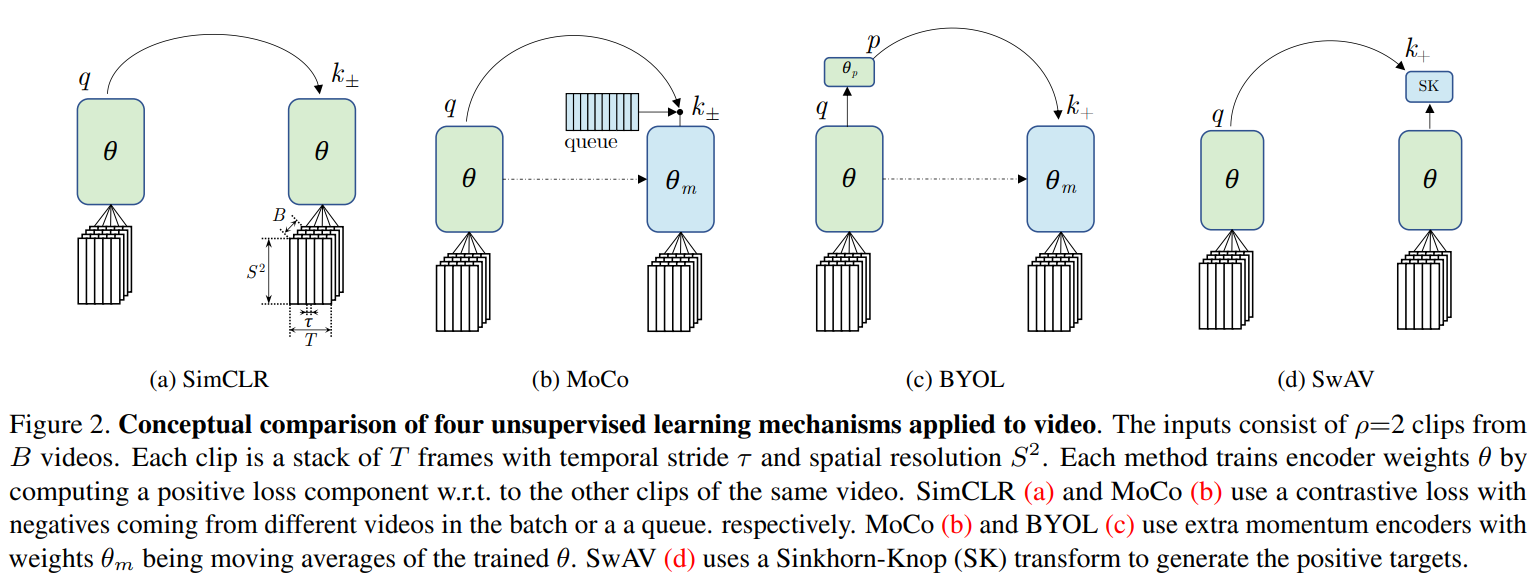
取一个未标记视频的不同增强片段,将其通过一个编码器得到相应的嵌入特征,文章中采用SlowFast网络中的Reset-50时空卷积结构,后接MLP投影头得到维度为的输出。如下图,每个clip由个连续的RGB帧堆叠构成,同一个视频采样的clips认定为正样本,而不同视频采集的clips判定为负样本。
输入的clips由个连续的RGB帧堆叠而成,在时间空间维度上的大小为,其中是每个视频划分的视频段数量,是尺寸大小。给定一批数据,包含个视频,文章的框架通过从视频中采样个clips,则记总的clips数量为。目标是最大限度地提高查询样本与一组正的键值样本之间的相似性,为与同一视频下的不同clips的编码特征。
无监督学习框架
InfoNCE的损失定义为:
其中,和分别表示query和key,为温度系数,。
SIMCLR使用同一个
batch的其它视频的clips的嵌入特征作为MoCo包含一个动量编码器,仅动量更新,不进行反向传播。
MoCo使用这个编码器计算与相同视频的不同clips的特征作为,负样本特征来自于一个queue(存储以前迭代时计算的clips的嵌入)。BYOL可认为是一个不使用负样本的
MoCo,去除了memory queue,且左侧分支增加一个MLP预测器,对于样本,目标是最小化负余弦相似度:其中,是与相同视频的
clips的嵌入。SwAV可认为是不使用负样本的
SimCLR。首先,将与通过线性映射学习原型和,再经过一个额外的Sinkhorn-Knopp(SK)步骤对目标进行转换。则损失函数为:其中,
SK操作不进行反向传播。
部分实验结果
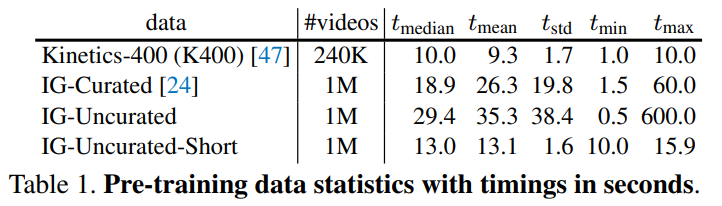
预训练的数据集:
评估方式:1)K400数据集:固定编码器,通过GAP得到线性准确率;2)UCF101数据集:微调得到准确率
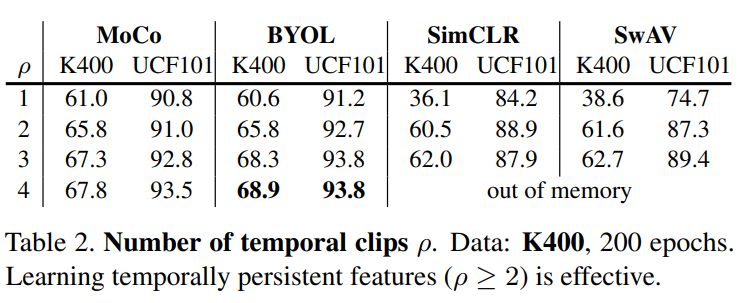
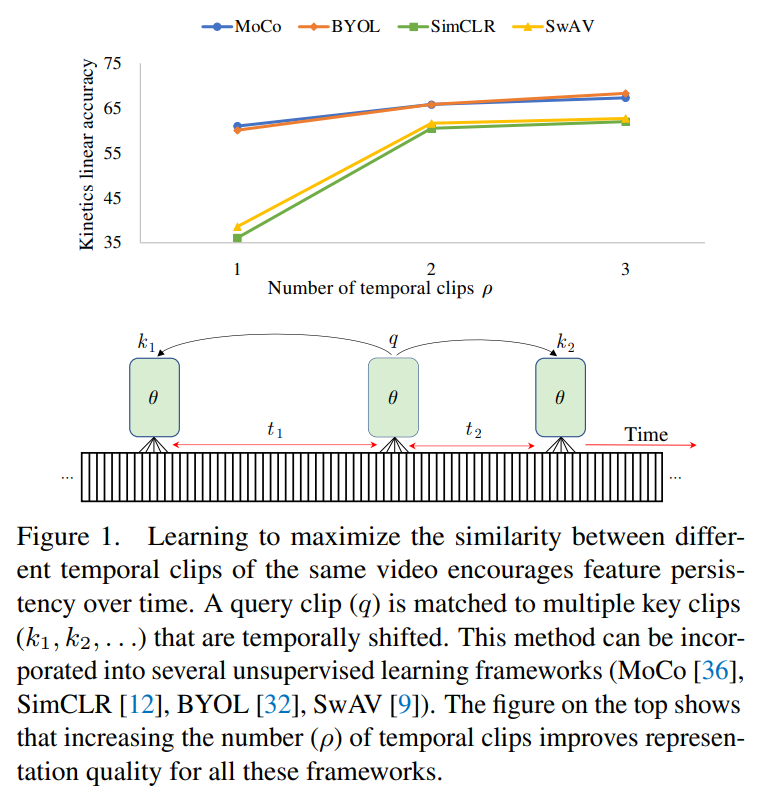
当clips数量为1时,SimCLR和SwAV精度大幅下降,更多的clips可以改善精度,且有无负样本不影响精度,但有无momentum encoder更重要。(视频需要更稳定的特征输出)
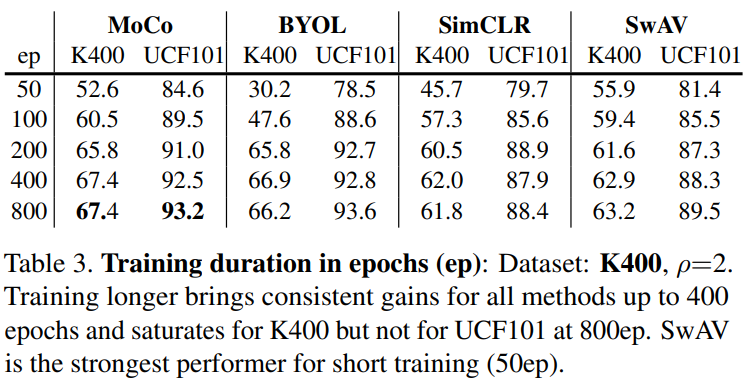
增加epoch数,可以改善精度
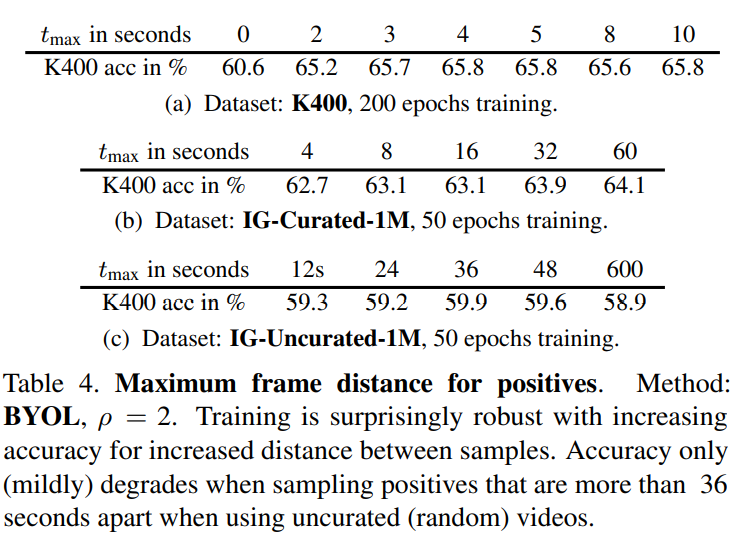
从整体来看,不同视频数据集下,同一个视频的正对时间跨度越长效果越好(时间跨度越长越容易获得更好的全局采样)
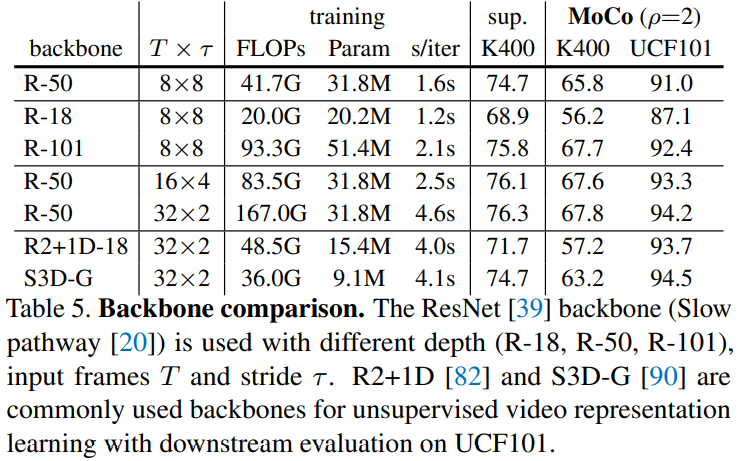
更深的网络,可以改善精度。