
动机
nlp中有丰富的无标注的文本语料,而从丰富的语料中学习语言表示可以为各种场景提供显著的提升,但现有方法仅依靠词级别的信息;- 如何利用无标记数据训练模型是非常有挑战性的,一是不清楚哪种类型的优化目标在学习对迁移有用的文本表示时最有效,二是对于如何最有效地将这些学习到的表征转化为目标任务,目前还没有共识。
贡献
- 为自然语言理解任务探索了一种半监督方法,它由无监督预训练和有监督微调构成,即使用语言模型为目标在未标注的数据上训练神经网络,再基于特定任务进行有监督微调;
- 在迁移到下游任务时,采用
traversal-style方法派生的特定于任务的输入自适应方法,对预训练模型结构更改较小; - 在四种类型的语言理解任务中,均证实了预训练模型能够为下游任务提供有用的语义信息。
模型结构
训练过程分为两阶段:第一阶段在大语料库上学习语言模型;第二阶段将模型适应带有标签数据的特定任务。
无监督预训练
给定一个无监督的语料tokens,目标函数为最大似然:
其中是上下文窗口的大小,条件概率采用参数为的神经网络建模。本文使用多层Transformer decoder的变体(即将Transformer decoder的中间子层去除),模型在输入上下文tokens上使用一个masked multi-head self-attention,之后接position-wise feedforward层去产生目标tokens的输出分布:
其中,是tokens的上下文向量,是层数,和分别是token和位置的embedding矩阵。
有监督微调
假定一个有标签数据集,其中每个实例由一个输入tokens序列和标签构成。输入经过预训练模型,得到最后一层transformer层激活值,将其输入一个额外的带参数的线性输出层去预测:
优化函数为:
作者发现将语言模型作为微调时的辅助目标有助于提升有监督模型的泛化能力,并加速收敛。故采用如下的目标函数进行训练:
总之,在微调阶段额外的参数是,及分隔符标记的embedding。
特定任务的输入转换
本文将结构化输入转换成有序序列以便预训练处理,并避免不同任务对模型结构进行额外的修改。如图所示,所有的输入转换均添加一个随机初始化的开始和结束符号和。
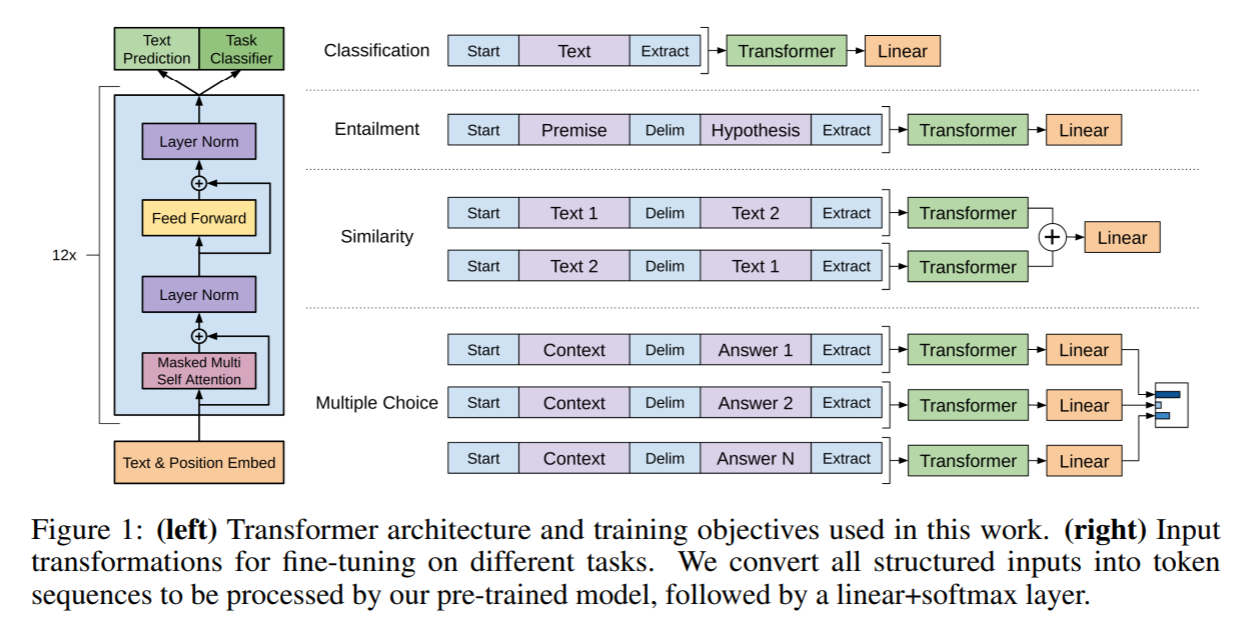
Textual entailment:将前提token序列和假设token序列串联,以分隔符$$$隔开。Similarity:由于被比较的两个句子没有固有顺序,故修改输入序列包含两种句子顺序的可能性(以分隔符分开),分别获得两个序列表征,并在线性输出层前将其按元素相加。Question Answering and Commonsense Reasoning:该任务有一个上下文文档,一个问题,和可能的答案集合。将和与每一个可能的答案串联起来,并以分隔符隔开,得到;a_k]$。将每个序列经模块独立处理后经过softmax在可能的答案上产生一个输出分布。
训练过程
预训练数据集:BooksCorpus dataset和1B Word Benchmark
下游任务数据集:

预训练时的模型细节:采用个decoder,其中masked multi-head self-attention设置为维度为,抽头数为;position-wise feedforward维度设置为。优化器为Adam,最大学习率为,在前次迭代时,从线性增长,后使用cosine衰减到。residual,embedding和attention均采用的dropout,并使用Gaussian Error Linear Unit(GELU)的激活函数。使用可学习的position embedding代替原始的正弦版本。使用训练个epoch,输入为长度为的tokens序列。
微调时的模型细节:在线性输出层采用的dropout,对于大部分任务,使用训练个epoch,学习率设置为,目标函数中。
部分实验结果
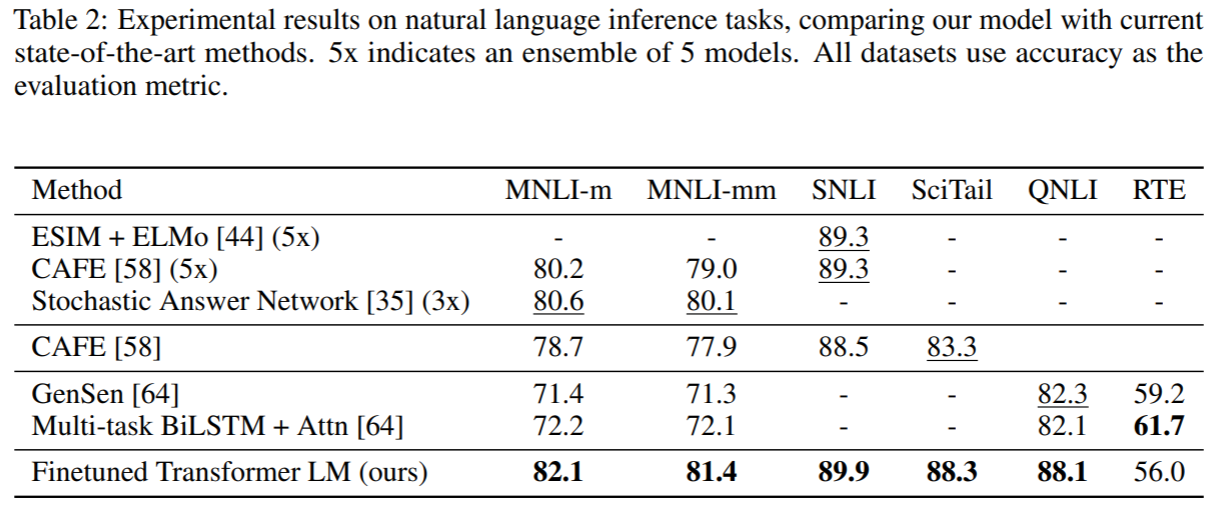
自然语言推理:
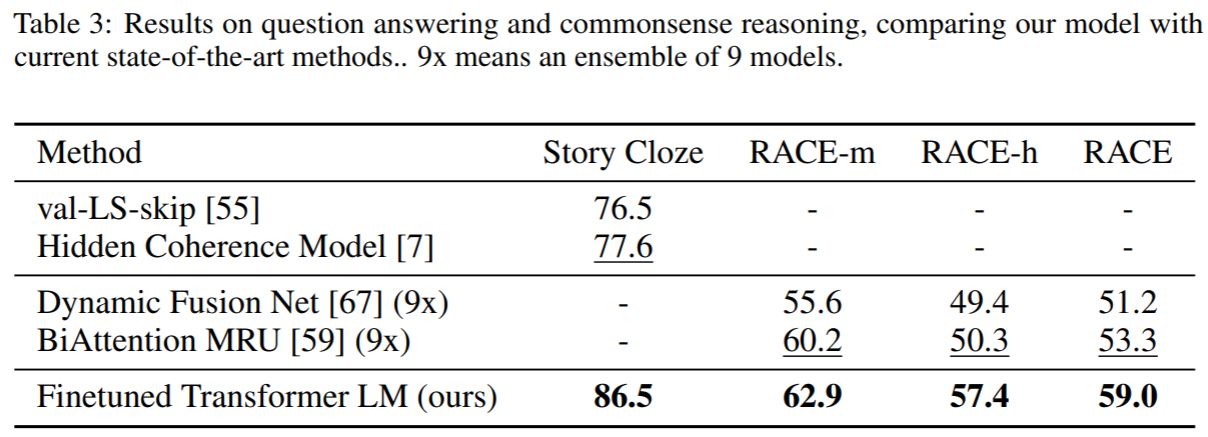
问答和常识性推理:
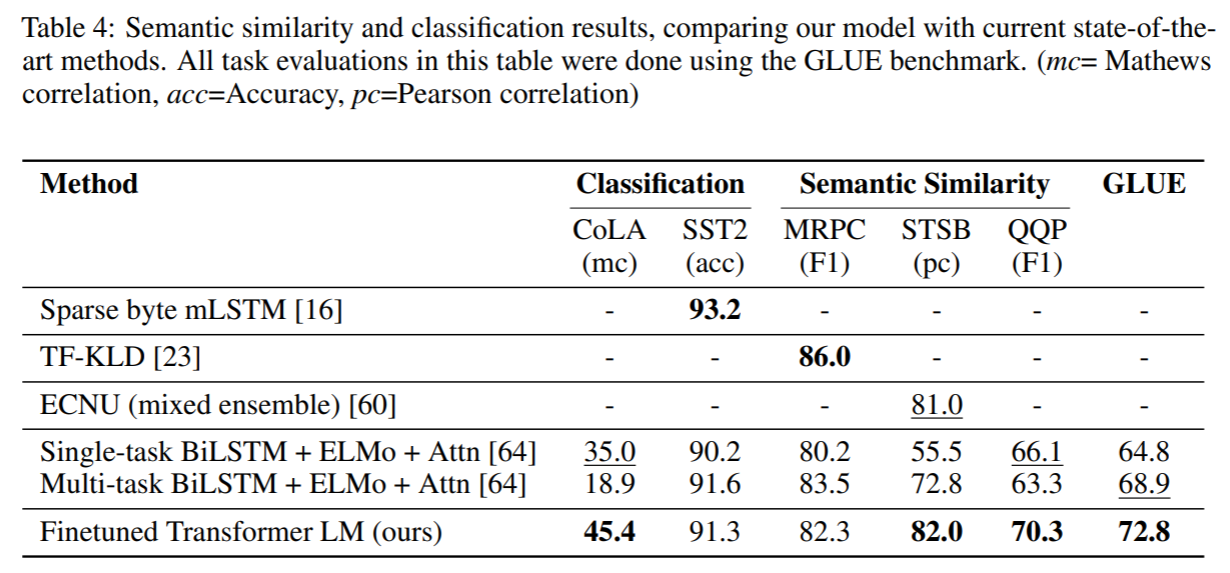
相似度和分类任务:
Zero-shot行为(即不进行有监督微调)
transformer性能更稳定,且在训练中维度增长,表明预训练能够传递语言建模能力;LSTM表现出更好的方差,表明transformer的归纳偏置(inductive bias)有助于迁移。
Ablation Study
Decoder层数越多效果越好;- 在微调阶段,辅助目标对较大的数据集有益;
Transformer的结构比LSTM结构效果好;- 预训练能大幅提升效果。