
如何表示一个单词的含义
建立所有同义词和下义词的词库
如
WordNet,一个单词的含义由它的同义词集合和下义词集合定义。缺点:某个单词只在特定语义下跟其他词为同义词;且词汇的新含义很难被包括;定义较为主观且需要人为整理;难以量化单词之间的相似程度。
使用离散的符号表征单词
传统的
NLP将每个词表征为一个one-hot向量。优点:可以无限增添数据,构建一个足够大的词空间。
缺点:词向量的维度就是单词的数量,过于庞大;所有向量正交,无效有效计算相似度。
希望:能够理解不同单词之间的相互关系。
通过上下文去表征单词
背景:一个单词的定义往往由由它附近的单词决定。
定义一个以单词为中心的定长窗口,该词称为
center word,窗内其他词称为context,希望通过这些词去构建center word的有效表示。由此对每个单词构建一个word vector(大多数元素不为0且维度较小,也称为word embedding/representation),希望相似的上下文,其word vector也相似。
如何得到word vector
Word2Vec
思想:已知有一个足够大的语料库,希望每个单词在一个固定的词汇表中被表征为一个向量。具体做法是通过扫描文本中的每个位置(每个位置具有一个center word和一个context words),和的word vector的相似性使用给定条件下的概率来表示(反之亦可),初始时word vector为随机向量,通过不断调整word vector使得这个概率最大化(就是希望两者之间的相关性大)。
对于一个句子,其中每个单词使用两个向量表示:分别表示该单词作为center word和context word的向量。
Skip-Gram model
求
context word相对于center word的条件概率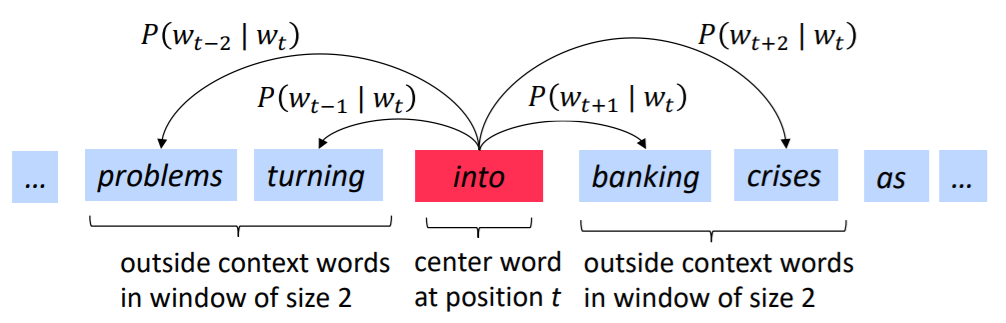
则对于每个位置,给定
center word,以一个固定长度为的窗口去预测context words。则总的似然函数为:
由此得到总的目标函数(负对数似然函数):
通过最小化目标函数,等价于最大化预测准确率。单个
context word和center word的条件概率写作softmax形式:其中,越大,等价于概率越大。通过对损失函数求导,得到:
由上式可以看出,梯度与实际的
context word与预期的context word的加权求和有关。使用
gensim可进行word vector的相似度计算、PCA可视化等
参考文献:
- CS224N笔记(一):Word Vector - 知乎 (zhihu.com)