动机
- 在序列建模与转换任务中,主流的模型是基于复杂的RNN的递归模型,其通常沿输入和输出序列的符号位置进行因子计算(即生成一系列隐藏状态,t位置的由前向状态和当前输入生成),这种内部的固有顺序阻碍了训练样本的并行化(在序列较长时,由于内存限制会限制样本间的批处理)。
- 注意力机制允许对依赖关系建模,而不考虑它们在输入或输出序列中的距离,但目前注意力机制通常与递归网络相结合使用。
贡献
- 提出了一种新的简单的网络架构
Transformer,完全避免循环和卷积网络,只基于Attention机制来建模输入和输出之间的全局依赖关系。 - 在两个翻译任务上,模型质量更好、且具有更高的并行性,且训练所需要的时间更少。
模型结构
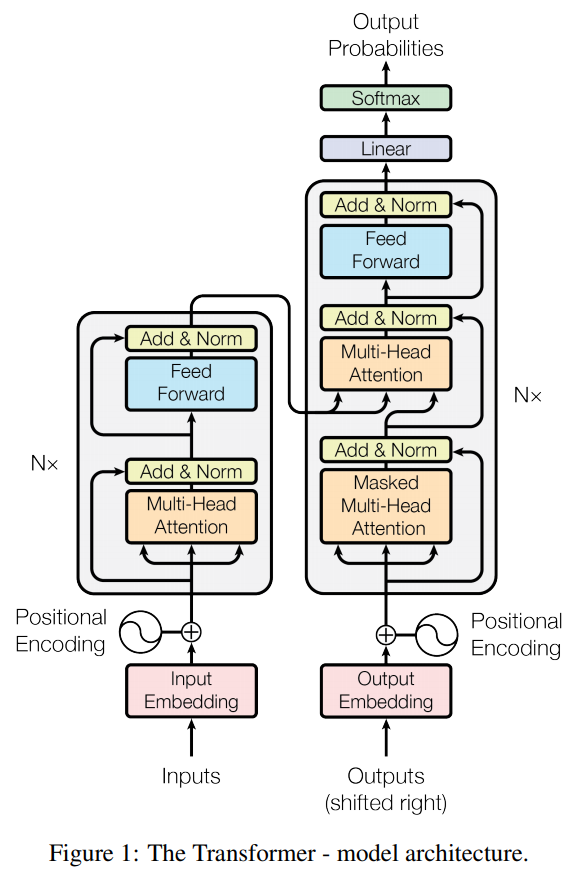
如上图所示,使用encoder-decoder架构,其中encoder将符号表示的输入序列映射成一个连续表示序列;给定,decoder以一次生成一个字符的方式生成输出序列。模型的每一步都是自回归,即在生成下一个字符时,将先前生成的符号作为输入。
Encoder:由个相同的网络层堆叠而成,每个网络层包含两个子层。第一层是multi-head self-attention mechanism,第二层是positionwise fc feed-forward network,并在每层后使用residual connection和layer normalization。因此,每个子层的输出为:
其中,是每个子层自身的输出值,文中设置所有子层及embedding层的输出维度为。
Decoder:由个相同的网络层堆叠而成,每个网络层包含三个子层。中间子层对编码器堆栈的输出执行multi-head attention,并且在每个子层后同样使用residual connection和layer normalization。其中第一个子层增加mask操作,以防止在当前位置信息中添加进后续位置的信息,这个mask与偏移一个位置的输出embedding相结合,确保位置的预测只依赖小于的已知输出。
Attention Mechanism
attention mechanism可以描述为将一个query和一组key-value对映射到一个输出,其中query、key、value和输出均为向量,输出为value的加权和,其中每个value的权重由query和key计算。
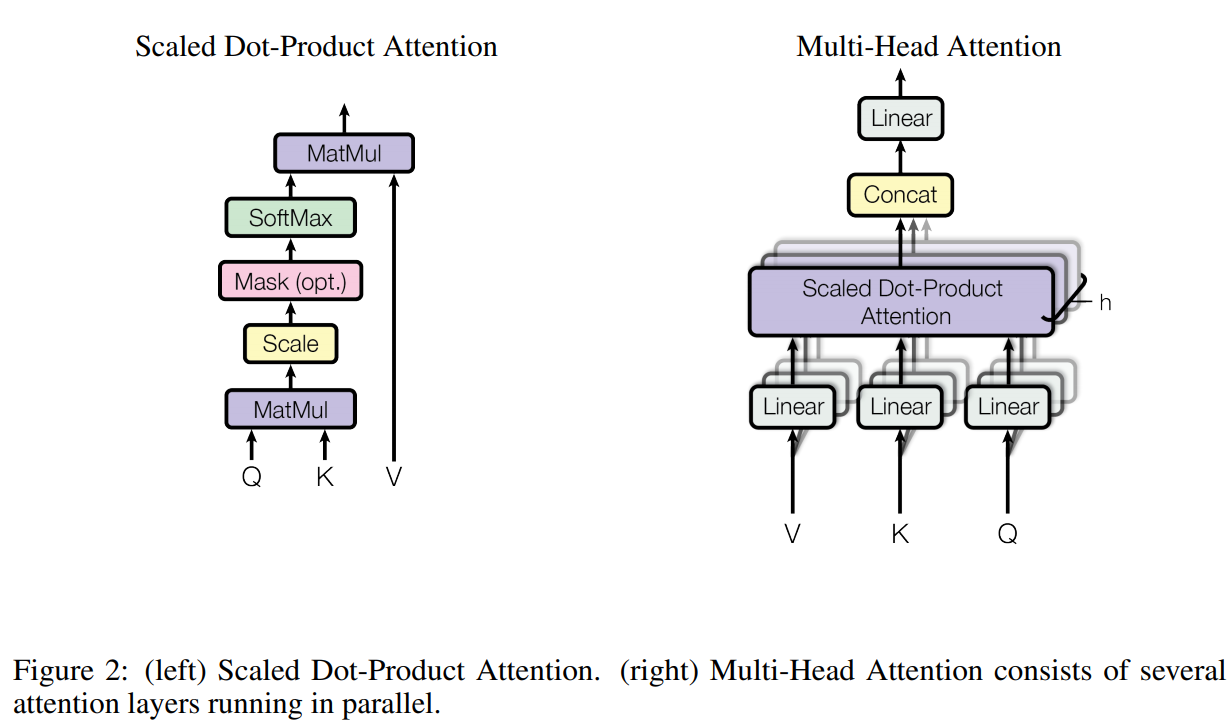
Scaled Dot-Product Attention由图可知,其输出矩阵为:
其中,,使用缩放是为了使得梯度更稳定。
Multi-head Attention相比于使用维度的
query、key、value执行单次attention,multi-head attention是通过个不同的线性变换对query、key、value并行映射,得到个维的输出值,再拼接起来进行映射得到最终值。作者认为Multi-head能把不同位置子序列的表示都整合到一个信息中,而如果只有一个attention head,其平均值会削弱信息。其公式如下:其中,,本文设置,,总的计算成本与具有全部维度的单个
head attention相似。
文中所用的attention有三部分:
encoder中的self-attention:所有的query = key = value均来自前一个网络层的输出,即每个位置都能关注到上一层的所有位置,其目的是学习句子内部的词依赖关系,捕获句子的内部结构。decoder中的masked self-attention:允许每个位置都关注当前位置及之前的所有位置,即采用mask消除右侧单词对当前单词的影响,目的是为了保持decoder的自回归特性,防止信息向左流动,在softmax步骤前将后面位置设置为(即通过一个矩阵来表示mask,其中上三角为0。)decoder中的encoder-decoder attention:其中,query来自前面的decoder层,key和value来自encoder的输出,使得每个位置都能关注到输入序列中的所有位置。
Position-wise Feed-Forward Networks
该网络层在所有位置上共享参数,其由两个全连接层构成,中间为ReLU激活函数,也可以理解为两个核为的卷积层。其输出为:
其中,输入和输出的维度为,隐藏层维度为。
Embedding and Softmax
Embedding:使用学习到的嵌入词向量将输入字符和输出字符转换为维度的向量。(由于输入序列长短不一,故使用padding mask进行补齐,对于短序列,在后面补-inf,对于长序列,则直接截断左侧。)
Softmax:将decoder的输出转换为预测的下一个词符的概率。
文中在两个embedding层和pre-softmax线性变化之间进行权重共享(三个权重的尺寸均为,其中emebdding层将输入token转换为维的词向量。在解码时经过softmax得到词的概率。)
Positional Encoding
作者使用位置编码,将编码后的数据与embedding数据相加。目的是加入相对位置信息,使得模型可利用序列的顺序信息。作者比较了两种方法:1)预训练位置embedding;2)使用不同频率的正弦和余弦函数。最后发现两者性能相似,但正弦函数可以允许模型拓展到未知的更长的序列。其公式如下:
其中,是位置(token在sequence中的位置),是维度(),即位置编码的每个维度对应一个正弦曲线。目的:1)每个位置有唯一的编码;2)由于三角函数的性质,这表明位置的向量可以表示为位置的向量的线性变换,这提供了表达相对位置信息的可能性。
self-attention的优点

上图是self-attention跟rnn和cnn的比较,即将一个可变长度的序列映射到一个等长序列,其中。
- 每层的总计算复杂度
- 可并行化的计算量:以所需的最小序列操作数衡量,如
self-attention可以计算点积,而rnn必须按顺序计算 - 网络中的长距离依赖的路径长度:指一个长度为的序列要经过的最大路径长度,如
cnn需要增加卷积层来扩大感受野,rnn需要按顺序进行计算,而self-attention可以一步矩阵计算(而当序列长度远大于序列维度时,可仅计算以输出位置为中心,半径为的邻域内,以减少计算量,此时最大路径长度为)。
且作者发现,self-attention可以产生更多可解释的模型,attention结果的分布表明每个attention head不仅可以学习到执行不同的任务,还表现出和句子句法与语义结构相关的行为。
训练过程
数据集:WMT 2014 English-German dataset和WMT 2014 English-French dataset
优化器:
学习率衰减:在warmup_steps前线性增加学习速率,随后按照与steps的平方根成比例地减小,作者设定。
正则化:
Residual Dropout:在add & LN之前,对每个子层的输出执行dropout操作;此外在encoder和decoder堆栈中,对embedding和positional encoding之和进行dropout。对于base模型,设定。Label Smoothing:在训练时采用的标签平滑,这会给模型带来不确定性,但会提高accuracy和BLEU分数。
部分实验结果
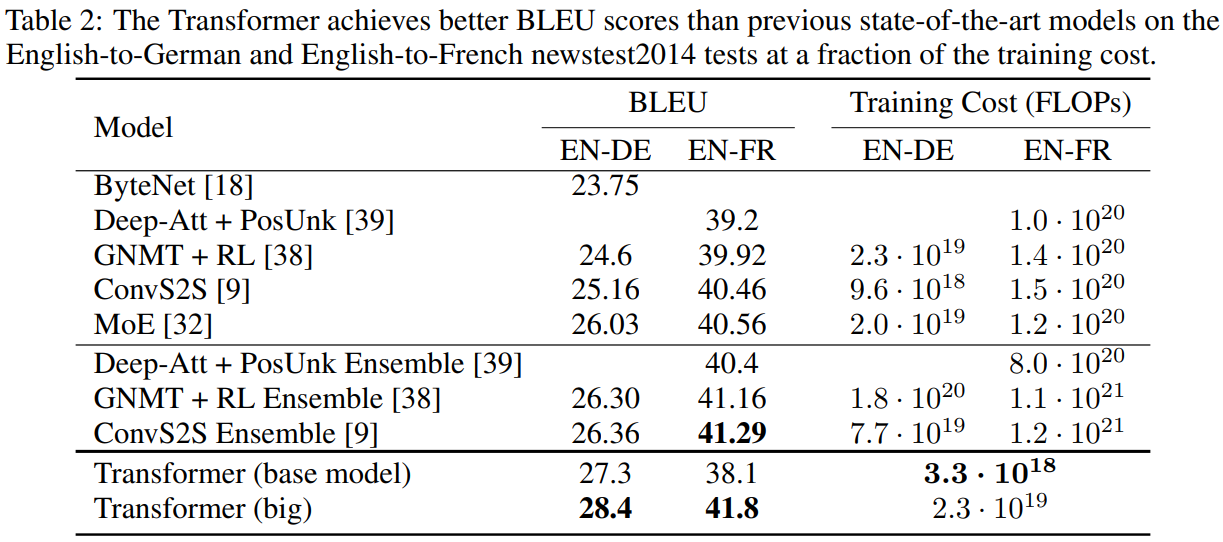
机器翻译任务:
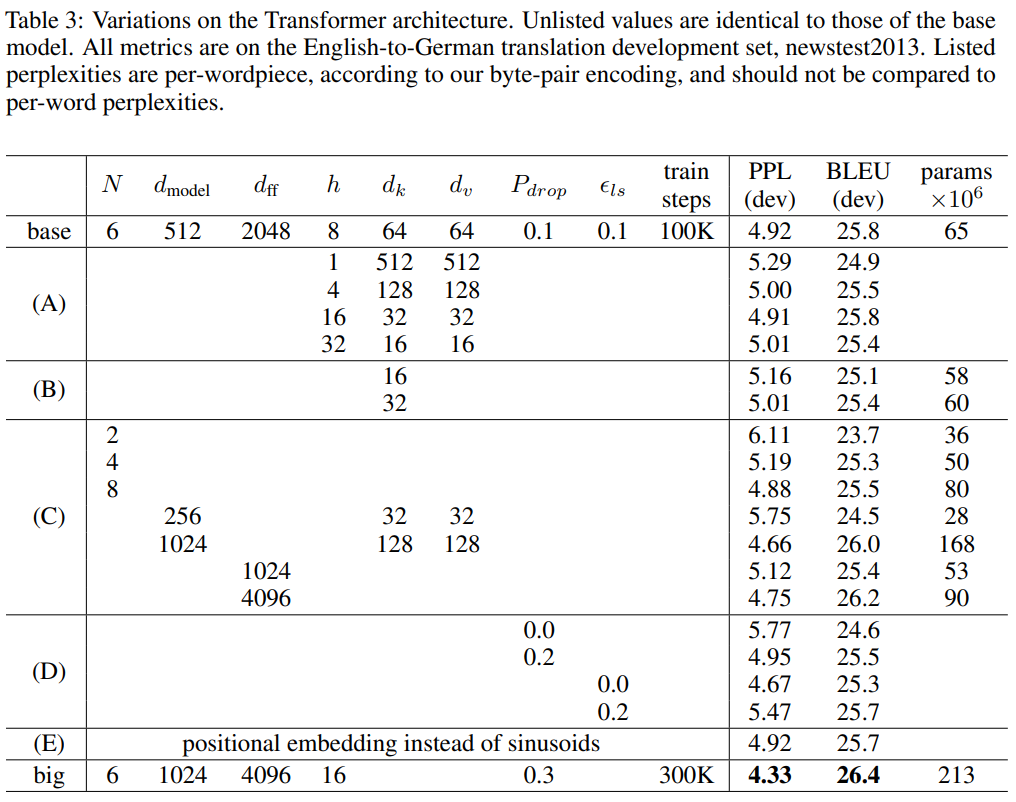
模型不同组件的作用:
英文选区分析: