
动机
- 人类可以从少样本中学到新概念,并用新学到的概念回答关于视觉场景的问题。
贡献
- 提出了一种解纠缠神经网络
D3DP-Nets,将RGB-D图像解纠缠为目标的形状、风格和背景图等,并探索了其在few-shot 3D目标检测和few-shot概念分类的应用。
相关工作
Few-shot concept learning
少镜头学习方法试图在测试时从一个或几个注释示例中学习新概念,但在训练时仍然需要标记的数据集,本文提出的模型通过预测视图来预训练,不需要对对象类或属性进行注释。本文的方法与部分方法有相似之处,即计算到通过对少数标记示例特征平均得到的原型的距离来分类,不同之处是在解纠缠的形状和风格编码基础上学习的概念原型取决于概念的语义而不是纠缠的2D CNN特征,且使用3D视觉特征空间的目标形状和3D旋转感知实例原型匹配,而不是一维嵌入的内积。
Learning neural scene representation
本文方法的场景编码器、解码器、视图预测目标等与Tung等人提出的几何感知神经网络相似,但本文的模型旨在学习特征表示,检测目标的姿态、比例等变化,并使它们用于概念学习,形状和风格的解纠缠则使用了AdaIN。
本文的方法
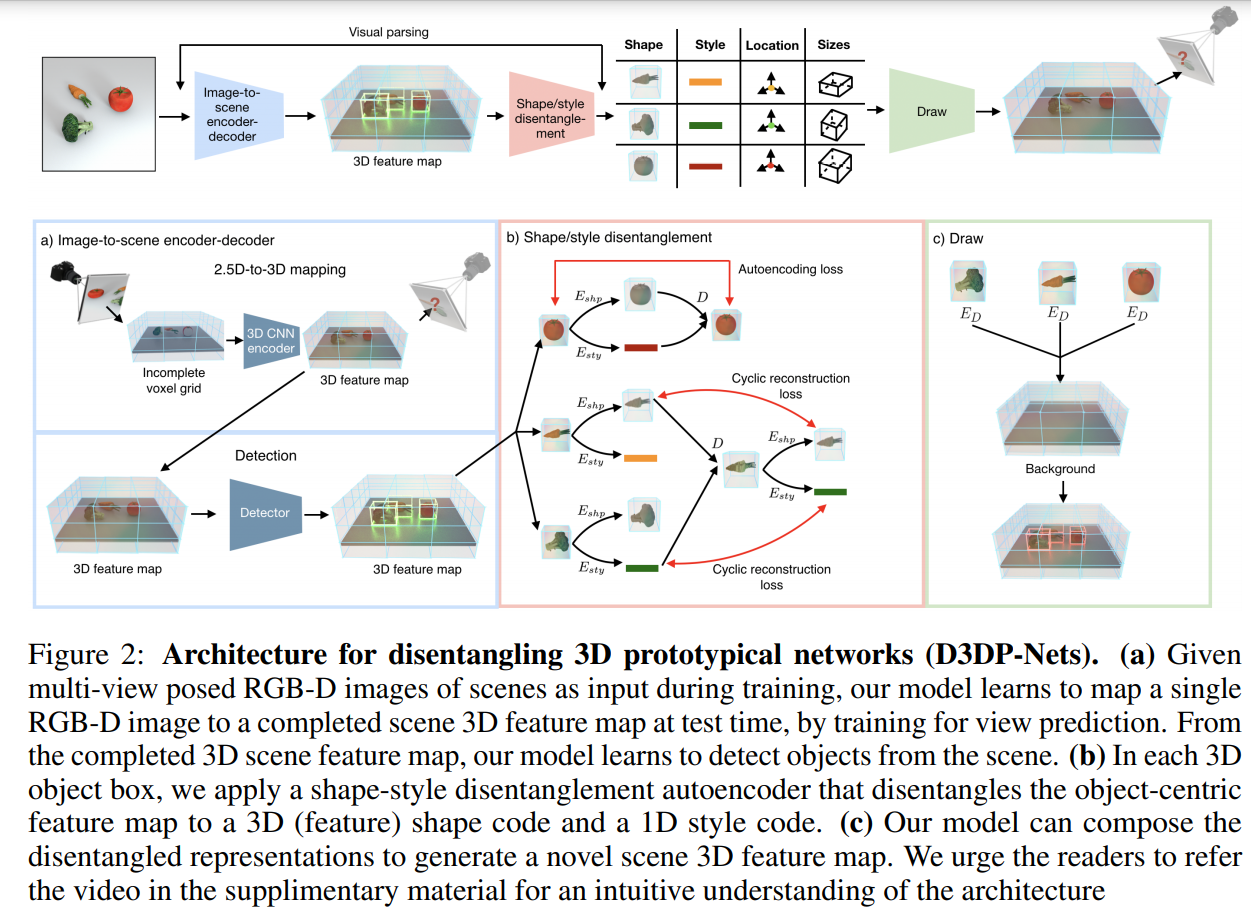
如上图,D3DP-Nets包含两个主要部分:一个图像到场景的encoder-decoder,一个目标形状/风格解纠缠encoder-decoder。
IMAGE-TO-SCENE ENCODER-DECODER
2D-to-3D的场景可微分编码器将输入的RGB-D图像映射到3D特征图,即每个网格点有一个通道的特征向量来描述在3D真实场景中对应的3D物理位置的语义和几何属性。对使用一个占用译码器输出一个二进制3D占用图,可微分的神经渲染器将3D特征图渲染为2D图像和一个特定视角的深度图。
D3DP-Nets通过视图预测实现自监督,其预测RGB图像和查询视图的占用网格点。文章假设有一个agent,可以在静态场景中移动,并从多个视角观察目标。联合训练场景编码器和解码器进行RGB视图预测和占用率预测,并将误差端到端的反向传播到网络参数:
其中,和分别为ground truth的RGB图像和占用图,为查询视图,是将3D特征图的内容旋转到视角的三线性重采样操作,这个RGB输出用回归损失训练,占用率用logistic分类损失,占用标签通过光线投射计算。由此训练一个3D目标检测器,将场景特征图作为输入,预测3D轴对齐的边界框,由无类标签的真实3D边界框提供监督信息。
OBJECT SHAPE/STYLE DISENTANGLEMENT
给定3D边界框集合,其中是场景中的一组物体,D3DP-Nets对场景特征图使用3D边界框进行裁剪得到对应的目标特征图,在训练时使用ground-truth的3D边界框,在测试时使用检测的3D边界框。每个目标特征图都被调整为16×16×16的固定分辨率,并被输入到一个以目标为中心的自动编码器,该编码器的编码模块预测一个4D的形状编码和一个1D的风格编码,解码器使用AdaIN组合这两部分编码:,其中是由经一个3D卷积得到的,而和是在通道维的均值和标准差,和是经单层感知器提取得到的。目标编码器和解码器用一个自编码损失和一个循环一致性损失进行训练,以确保在组合、解码和编码后形状和风格编码保持一致:
其中,为形状一致性损失,为风格一致性损失。
进一步,在合成的场景特征图上加入了一个视图预测损失,该损失为将每个目标特征图替换为其重新合成的版本,并调整到原目标的大小。即视图预测损失为:,则总损失为:
3D DISENTANGLED PROTOTYPE LEARNIN
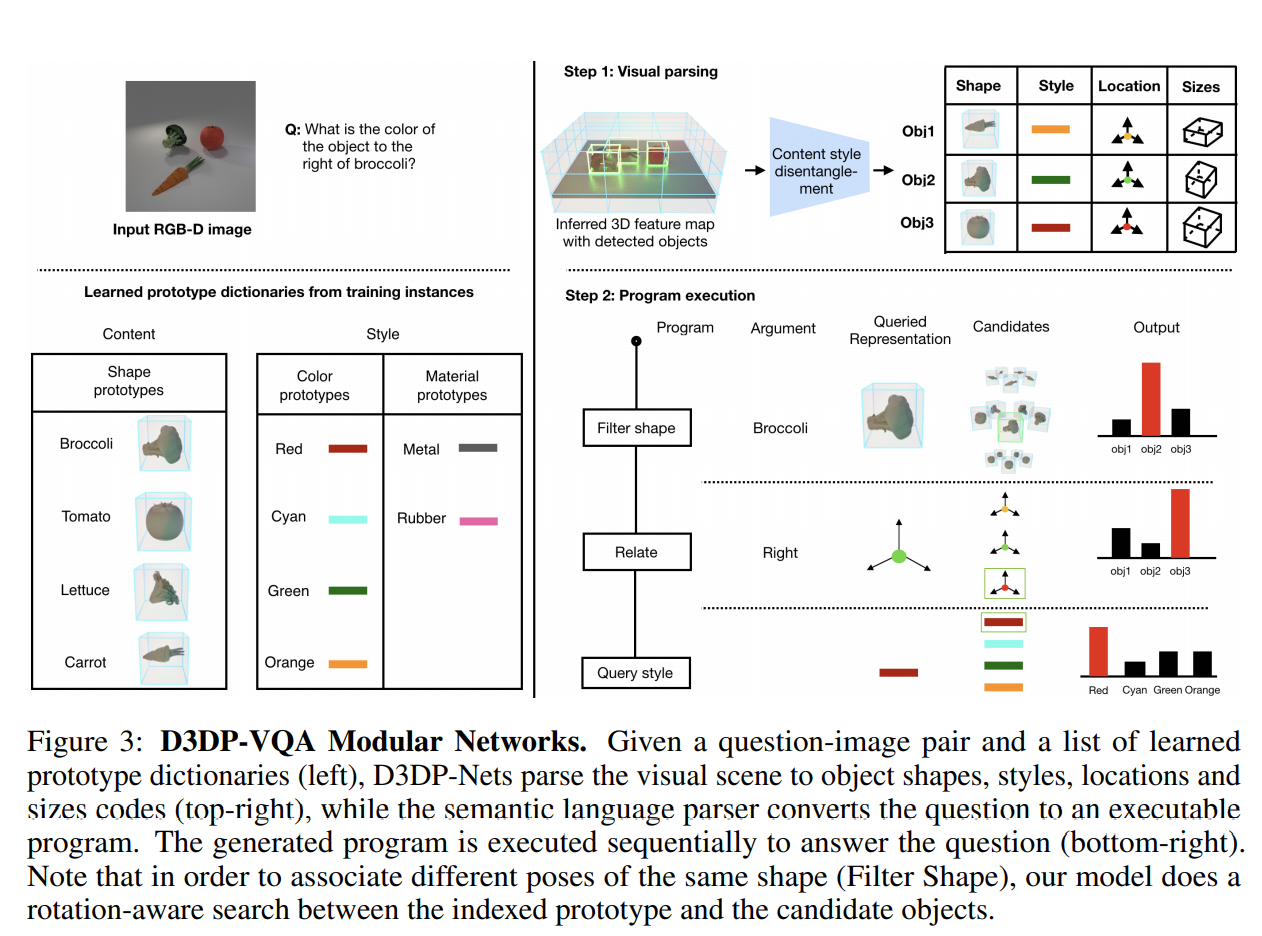
给定一组以目标属性(形状、颜色、材质、大小)标签形式的人工标注,模型计算出每个概念的原型,只使用相关的特征嵌入,如目标类别原型只在形状编码的基础上学习,材料和颜色原型在风格编码的基础上学习。对一个新的目标实例分类,则用D3DP-Nets推断出的形状和风格嵌入与原型字典中的原型计算最近邻来检测。
为了计算嵌入和原型之间的距离,定义以下旋转感知距离度量:
其中,通过三线性插值以角度旋转3D特征图中的内容,考虑沿垂直轴的增量对于进行详尽的搜索。
模型通过平均标记示例的特征来初始化概念原型,如对于红色等,对风格编码通过颜色全连接层的输出求平均,对于对象类别,找到每个形状嵌入的对齐,用于计算,并对对齐的嵌入求平均。
当为概念提供注释时,可以使用交叉熵损失来共同调整原型和神经网络(以及D3DP-Nets的权值),交叉熵损失的对数是神经嵌入和原型之间的内积,如,其中表示旋转感知距离度量,是属性的神经网络,是属性的概念集合,是目标的属性的值,是概念对应的原型,故用于训练原型的损失为:
其中,是属性的集合。
部分实验结果
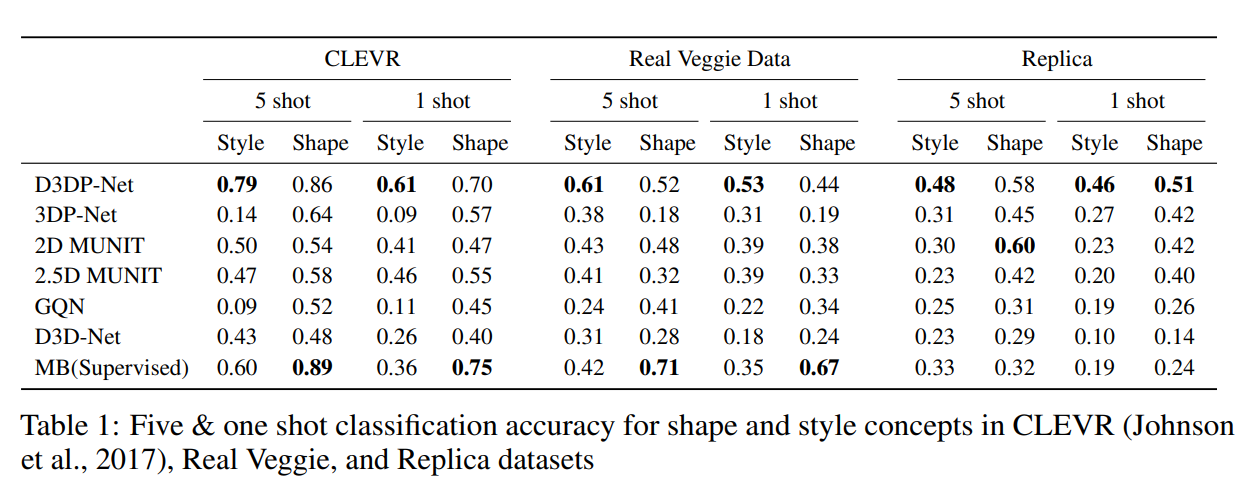
few-shot目标形状和风格类别学习
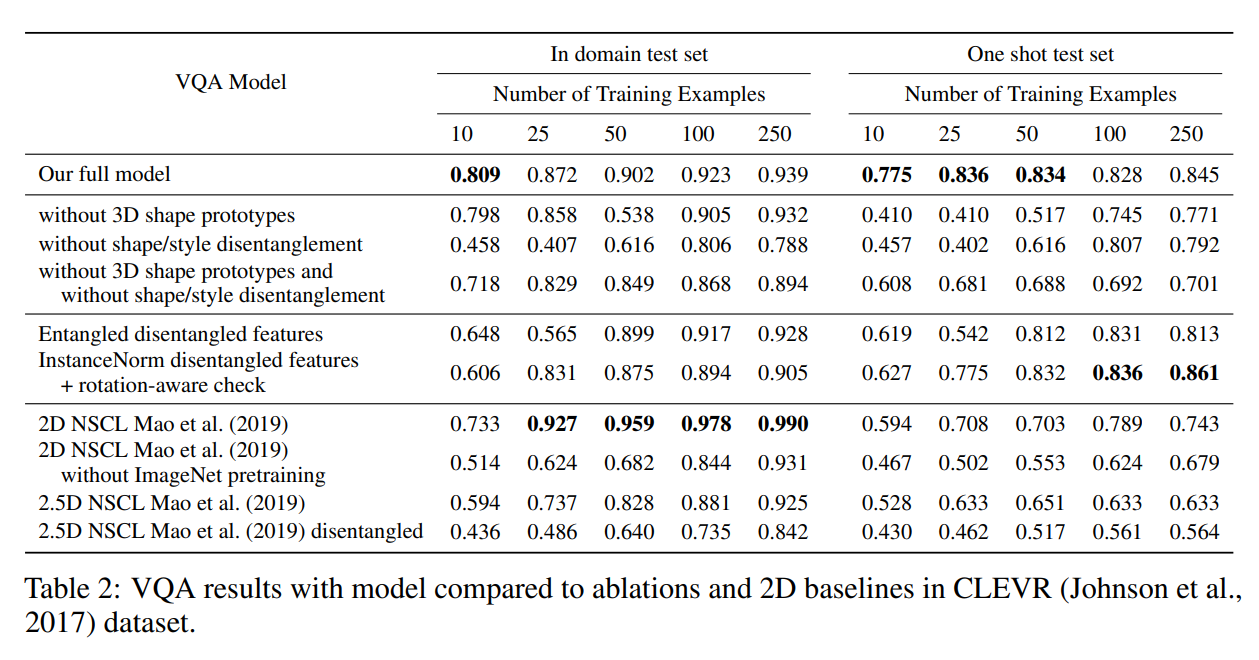
few-shot视觉回答
视图预测

文本语言的3D场景生成
