动机
贡献
对比学习设置
对比表征学习希望学习一个嵌入函数,它将一个观测映射到半径为的超球面上的一点,其中是温度尺度超参数。
假定一组表示语义内容的离散潜在类,则相似对则具有相同的潜在类别。用表示潜在类的分布,定义联合分布,边缘分布简写为,并假定。假设是均匀分布,而表示另一类的概率,而是未知的类先验,故需要认定为超参数或被估计。
设为对输入赋予类别的真实的潜在假设(可以理解为一个分类器),使用表示标签相等的关系,表示与有相同标签的数据点的分布,表示与不同标签的数据点的分布,表示从中采样一个数据点。
对于每个数据点,用于学习表征的噪声对比估计(NCE)损失函数使用一个与相同标签的正例和不同标签()的负例(采样自):
通常取,即负样本数。负样本分布经常被选择为边缘分布,或者在实践中是它的经验近似。本文的问题是:是否有更好的方法来选择。
困难负样本采样
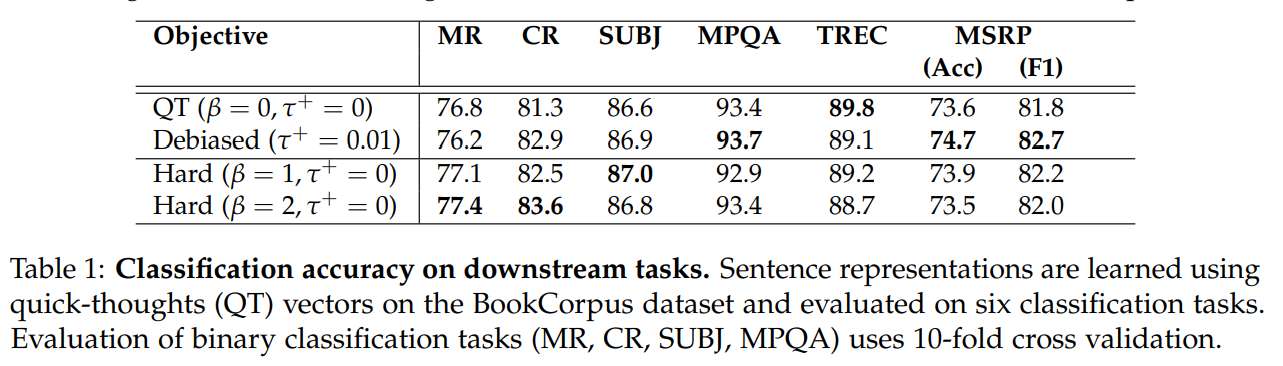
对于什么是好的负样本,本文给出两个定义:
- 应该只采样标签跟锚点不同的负样本;
- 最有用的负样本是那些被认为与锚点相似的样本。
即如上图,需要选择与锚点不同标签的负样本,且在嵌入空间与锚点相近的负样本在训练期间能提供更显著的梯度信息。在对比学习中无监督,则定义是不可能做到的,本文则提出了一种方法,在坚持定义时,结合额外的概念hardness,hardness是一个trades-off(在hard negatives提升学习表征和错误的negatives损害性能之间,因为最困难的点是在嵌入空间中离锚点最近的点,但离得近的点有较高的倾向有相同的标签,如果没有去除假负样本会造成损害)。当hardness完全调低,则得到Debiased Contrastive Learning中的方法,即近似支持定义,而不支持定义,此外本文希望设计一种有效的采样方法,使得在训练期间不会增加额外的计算开销。
提出的困难负样本采样方法
首先在上设计一个分布,它依赖于嵌入和锚点。从采样一个batch的负样本,则对应的分布定义为:
其中,的指数部分是均值方向为,集中参数(concentration parameter)为的非归一化von Mises–Fisher分布。对于,在的条件下保证了是不同的潜在类别(定义);集中参数则控制了上的权重点与锚点有较大内积(相似度)的程度(即上式中,,同时表示为负样本的概率,使得相似度大的负样本,其取值更大,则采样时更容易采到)。又由于位于半径为的超球面上,故有,故偏好有大内积的点等同于偏好有小欧氏距离平方的点。
为了实现一种实用方法,通过采用Pull-learning的观点重写这个分布,则得到(类似全概率公式):
其中,则可以得到负采样的分布,其有两个可跟踪的分布构成,因为有从采样的样本,且能够近似从采样的样本(使用语义不变性转换)。
由上述,可以通过从中生成样本,且能使用rejection sampling近似从采样的样本,但rejection sampling涉及到在采样batch时增加一个额外的速度较慢的步骤。本文改写了对比损失,固定并使得:
将代入上式,则得到hardness-biased目标函数:
这个目标函数表明只需要估计期望和,可对采样自和的样本使用经典的Monte-Carlo importance sampling:
其中,,分别是和的配分函数,用经验项,(其中是中心在的Dirac delta function)来近似和,而和可以得到如下的经验估计:
文章建议重新调整目标函数的权重,而不是修改采样过程,文章只需要额外的两行代码而不需要额外的计算开销。

关于Hard Sampling的分析
此外,文章分析了Hard Sampling是在Marginal和Worst-Case Negatives之间的中间情况,并分析了在Worst-Case Negative情况下负样本在超球面的最优嵌入,见原论文part 4,相关证明略。
文章在part 6讨论了两个问题:
是否更难的样本一定更好?
不能设置过大的,过大的时候靠近的样本,存在过多的假的负样本(与是同类)
将设置为较大的值,则模型只关注最难的样本,但下图的实验显示更大的并不一定会有更好的结果,且当在训练过程中使用真正的正对(绿色曲线,对于正对使用标签信息,对于负对不使用),下游任务的性能随着单调增加直至收敛。这说明,在的条件下,使用真实的来修正采样与具有相同标签的,但实际使用一组数据增强来近似,则只能部分修正。对于大的,这种情况会很偏向,而接近,其中有许多与有相同的标签,如果不纠正,将会对性能有害。
避免错误的负样本会改善这个采样?
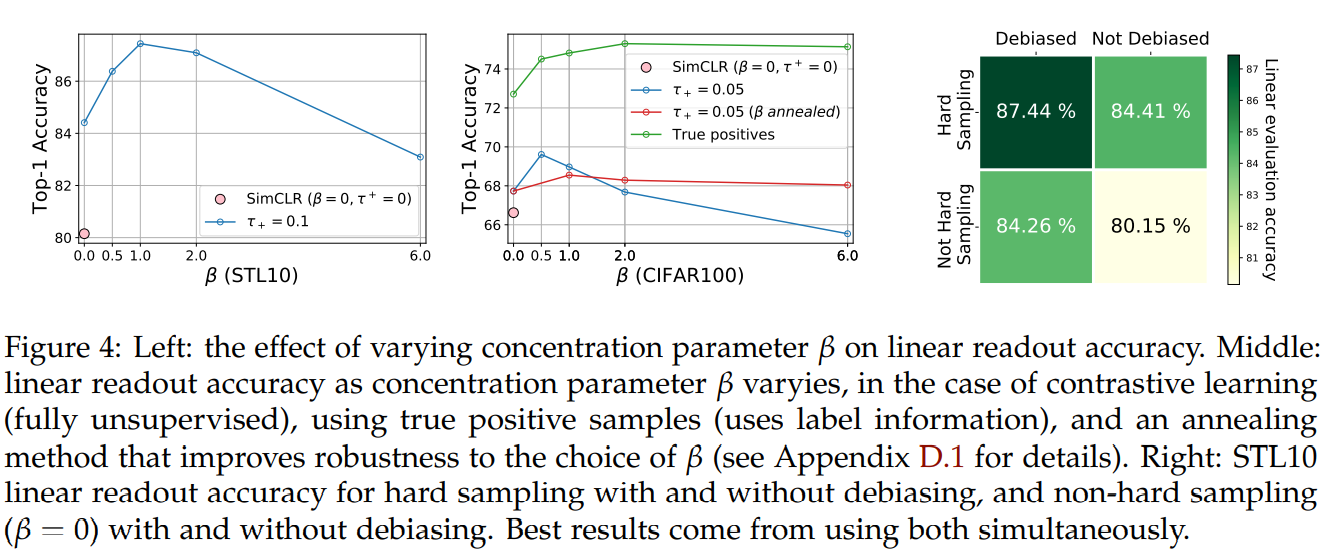
称条件为debiasing,用来避免错误的负样本,文章测量了这部分的作用。上图最右的图像显示了在hard sampling和均匀采样时,带debiasing都比不带debiasing好。
下图比较了这四种情况下的正负对余弦相似度的直方图,hard sampling比均匀采样的重叠更少,能更好的权衡更高的不相似的负对和较少的相似的正对,对于带debiasing和不带debiasing的情况类似。
部分实验结果
图像表征:
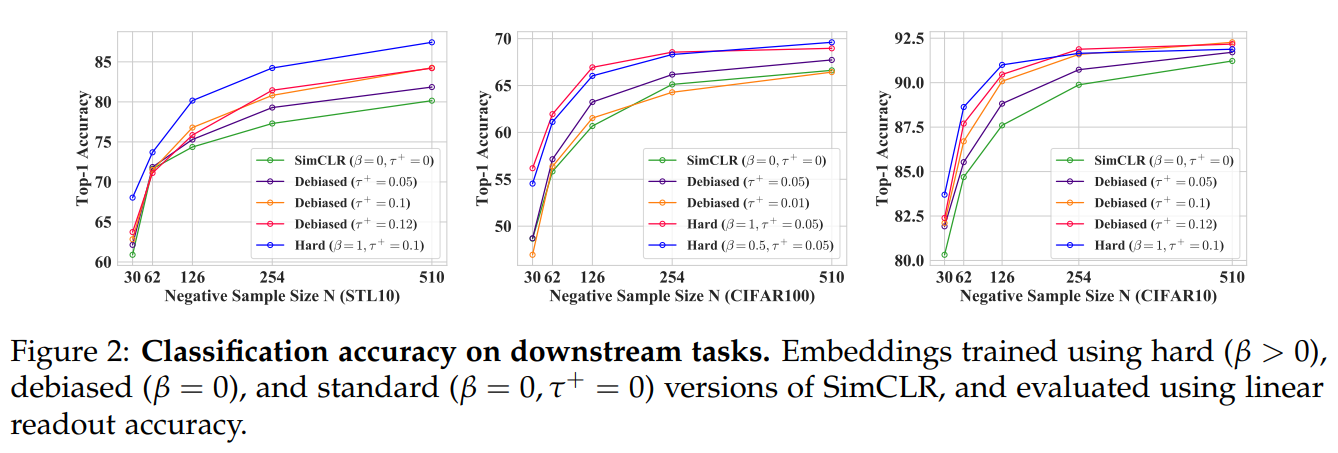
图的表征:
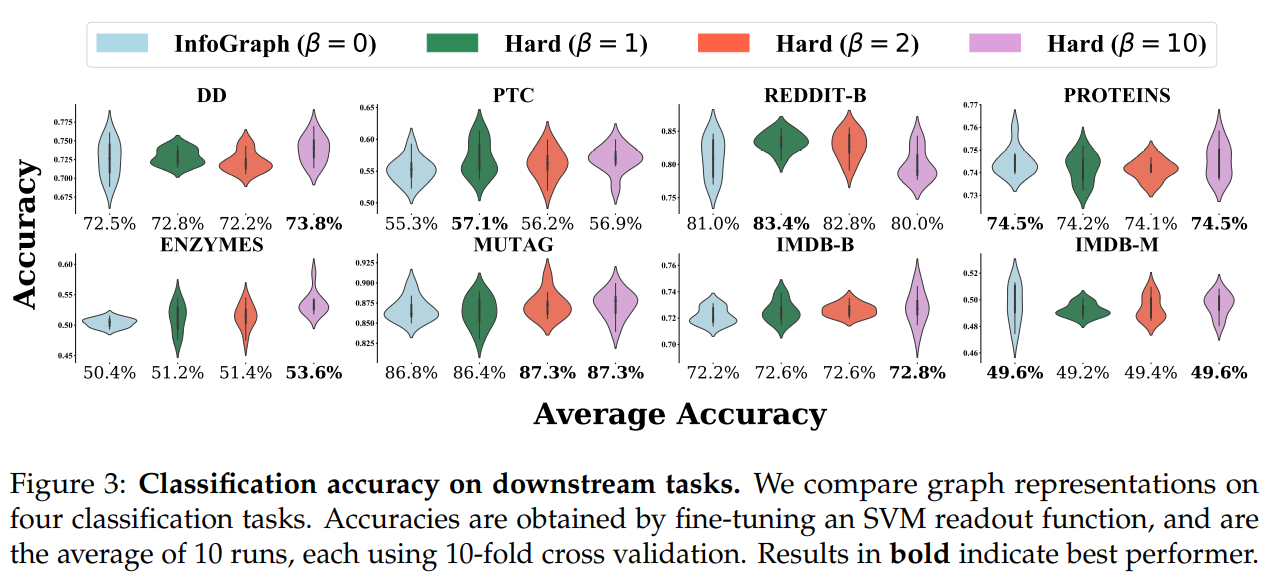
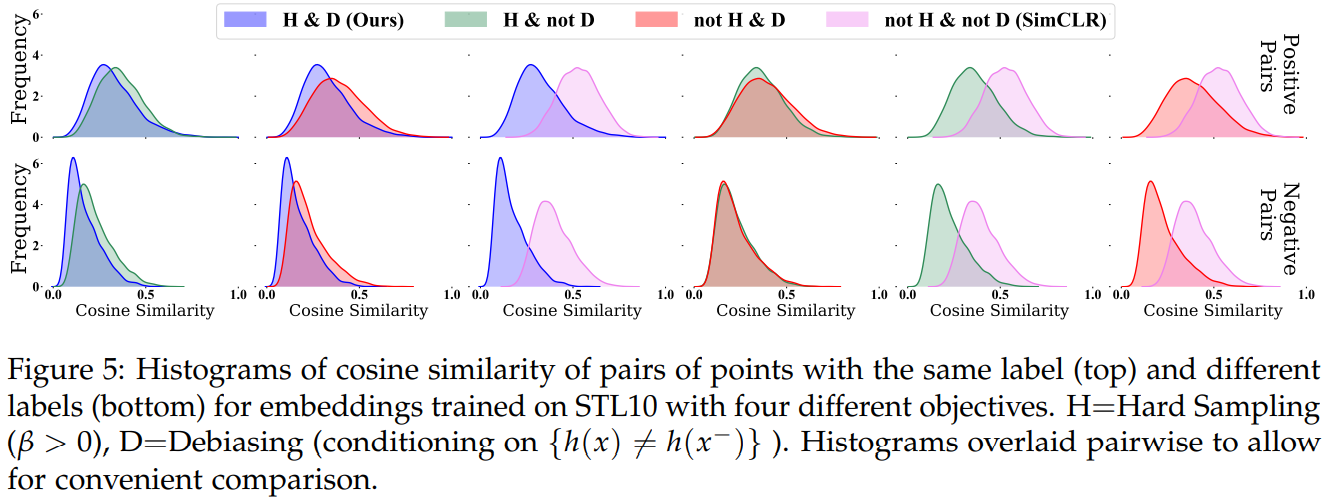
句子表征: