动机
- 现实情况下数据集的数量会受到限制,训练
GAN时使用过少的数据通常会导致判别器过拟合,而导致它对生成器的反馈变得无意义,从而训练不收敛; - 数据增强在训练分类器这样的判别语义信息任务上是有效的(数据增强导致这些语义保持失真的不变性增加),但简单的数据增强在生成样本中会导致“泄漏”(即
GAN会学习生成增强的数据分布,如:噪声增大会导致有噪声的结果,即使数据集中没有噪声)。
贡献
- 演示了如何使用各种各样的增强来防止判别器过拟合,同时确保不会有任何增强泄漏到生成的图像中;
- 提出了一种自适应判别器增强机制,在有限的数据下能够稳定训练,且有较好的生成质量,该方法不需要改变损失函数或者网络结构。
GAN的过拟合
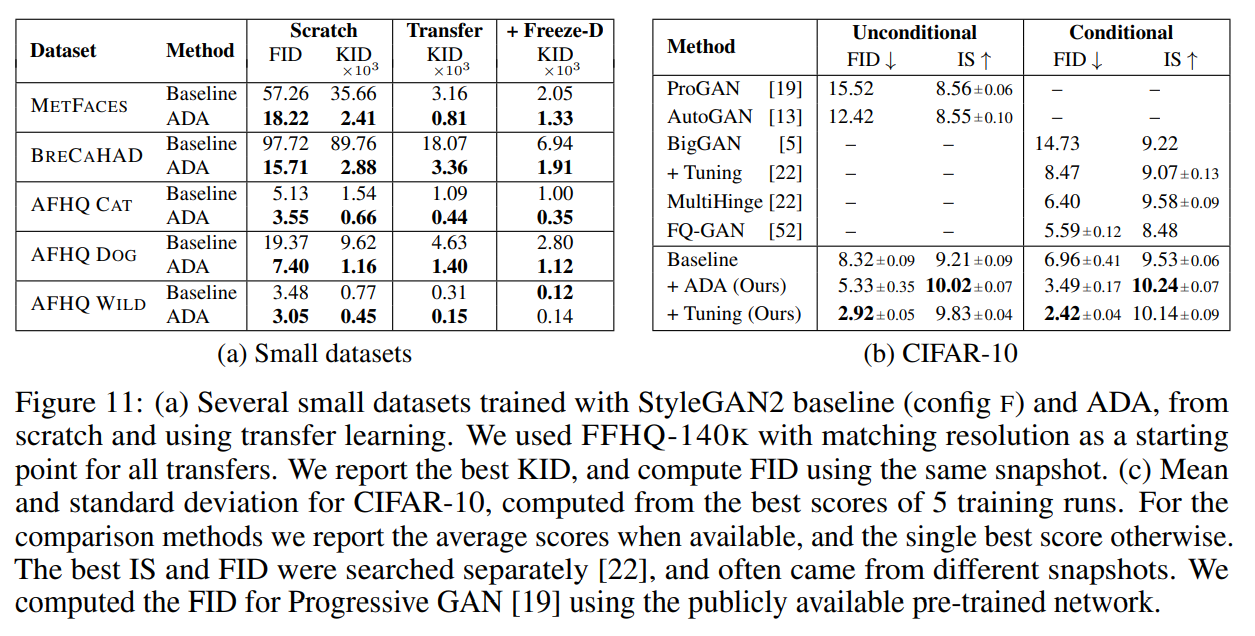
如上图,(a)显示了FFHQ不同子数据集的FID结果,随着训练的发生,FID由下降到上升,训练数据越少,转折点越早发生;(b)(c)显示了训练过程中真实图像和生成图像的判别器的输出分布,最初分布是重叠的,随着判别器越来越自信,分布会漂移分开,FID开始上升的点同分布之间失去足够得重叠时间是一致的,说明发生了过拟合,且判别器过拟合时,即使是真实数据的验证集,判别器的输出也会接近于生成数据分布,即说明了判别器过拟合到了训练数据上。本文由此提出了一种解决方法:使用通用的数据增强,防止判别器过度自信。
随机判别器增强
根据定义,任何应用到训练数据集的增强都将继承到生成的图像。而最近的平衡一致性正则化bCR希望增强不会”泄漏”到生成图像,它认为将两组增强应用在相同的输入图像,应该产生相同的输出。其对判别器损失添加上一致性正则项,并对真实图像和生成图像强制执行判别一致性,而在训练生成器时则不应用数据增强或一致性损失。该方法希望使得判别器对于使用的增强视而不见而成为一般化的判别器,但是bCR的生成器可以自由地生成包含增强的图像而不受到任何惩罚,故其效果与数据集增强相似。
本文的方法类似于bCR,对判别器的所有图像应用一组增强,但没有添加一致性正则化损失,而是仅使用增强图像来训练判别器,并且在生成器时也这样做。可能会怀疑这种方法的判别器没有看到真实的训练图像,能否正确指导生成器而是否有效,为此本文研究了这种方法不会“泄漏”到生成图像的增强的条件。

设计不泄漏的增强
判别器增强意思是给予判别器失真甚至损坏的图像,但要求生成器产生与训练集无法区分的样本。Bora et al.表明只要破坏过程表示为数据空间上概率分布的可逆变换,则训练可以隐式地消除破坏并找到正确的分布。本文称这种数据增强操作非”泄漏”。
这种可逆变换允许仅观察增强集就可以得出有关基础集的相等或不等的结论,这并不意味着在单个图像上执行的增强操作必须是可撤销的,如将输入图像的时间设置为0,在概率分布上是可逆的:即忽略黑色图像,也可推断出原始分布;从中均匀选择的随机旋转是不可逆的:增强后不能辨别方向之间的差异。
如果这种旋转只是以的概率执行,则情况会改变:这增加了的相对发生概率,只有生成的图像具有正确的方向,增强分布才能匹配。
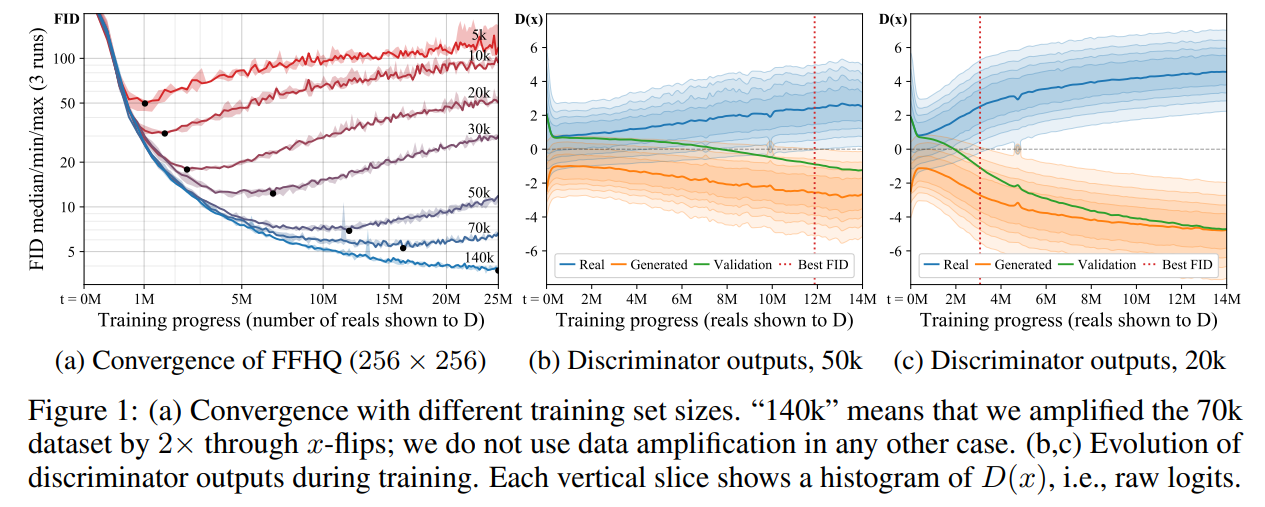
如上图,使用了三个示例验证分析,表示不同时,模型生成的图像及FID可视化。对于各向同性缩放,则不会“泄漏”;对于随机倍数旋转,当过大时则生成器无法知道图像应该朝向哪个方向,会随机选择一种可能性;对于连续的色彩增强序列同理。
文章采用的增强方法
基于RandAugment的方法,考虑了种变换,主要分为六类:pixel blitting (x-flips, 90◦
rotations, integer translation), more general geometric transformations, color transforms, image-space filtering, additive noise和cutout。由于在训练生成器时也会使用增强,故要求增强是可区分的。
在训练过程中,使用一组预先定义的变换按固定顺序处理输入到判别器的图像,增强的强度由控制,每个变换有的概率应用或的概率跳过,对于所有变换,始终使用相同的。尽管很难让判别器看到干净的图像,但只要值在安全限值下,生成器可以被引导生成干净的图像。
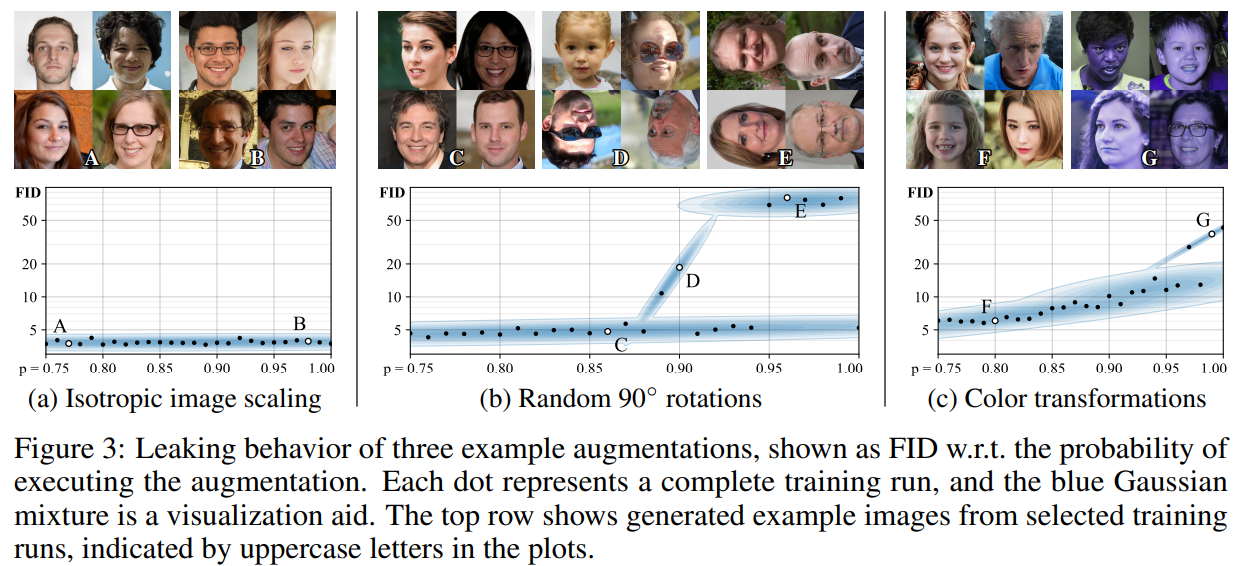
上图的结果,通过对不同的增强类别和数据集大小对扫描来研究随机判别器增强的有效性。在多数情况下,可以显著改善结果,其最佳增强强度主要取决于训练数据的数量。对于的训练集,Blit和Geom起主要好处,Color适度有益,其余无用;对于,较高的值帮助不大;对于,所有的增强都是有害的。文章在之后的测试中,只使用Blit, Geom, Color。最后一张图显示,较强的增强在减少过拟合的同时,会减缓收敛速度。
自适应判别器增强
文章设置一个单独的验证集,并观测其相对于训练集的行为,可以看到过拟合开始时,验证集的行为越来越像生成图像。对于训练集,验证集和生成图像,分别用,和表示判别器的输出,用表示个连续mini-batch上的均值,实验中采用,batchsize为,对于图的观察结果转换为两个可能的过拟合启发式公式:
由上式,当表示没有过拟合,表示完全过拟合。文章的目标是调整增强概率,使所选的启发式方法匹配一个合适的目标值。第一个启发式表示了验证集相对于训练集和生成的图像的输出,第二个启发式估计训练集中获得正向判别器输出的部分(即判别器输出为真的部分),与直接查看相比,其对所选择的目标值和其它超参数的敏感性更低。
文章将初始化为,并根据选择的过拟合启发式,每个mini-batch调整一次的值,如果启发式表明过拟合过大/过小,则通过增加/减少一个固定的数量的。通过设置调整的大小,以便可以足够快的从升到,如图像,每一步之后都为,称其为自适应判别器增强(ADA)。
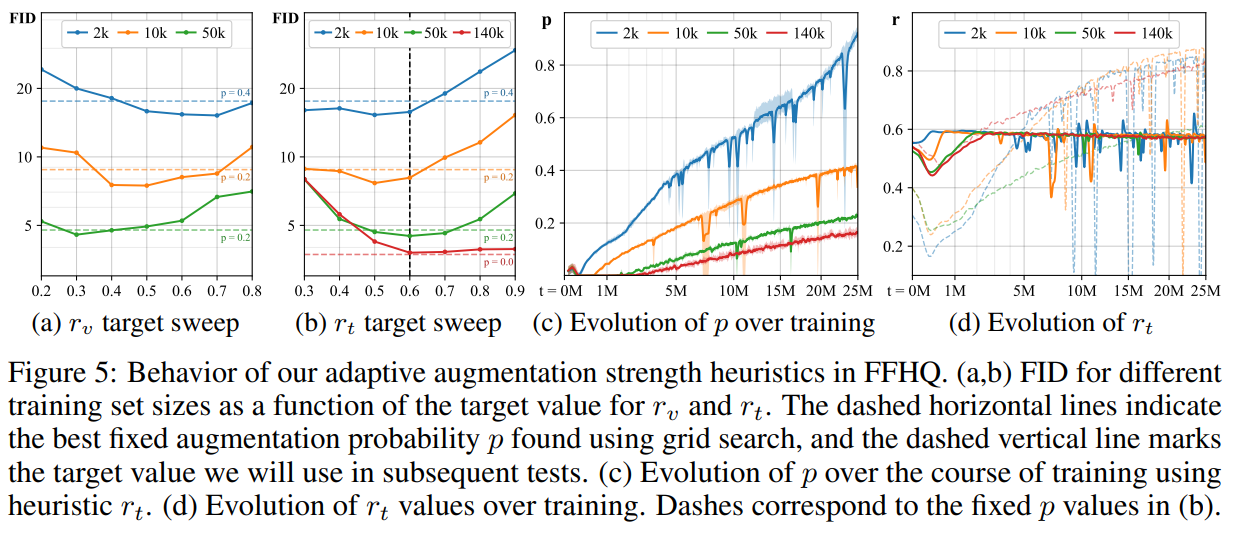
上图(a),(b)测量了目标值的影响,观测到和都可以有效防止过拟合,且提高了使用网格搜索找到的最佳固定的结果,后续的目标值选用为;(c)显示了在使用训练过程中随时间变化的结果;(d)则对比了自适应和固定时,的演变,表明固定在开始时往往太强,在结束时往往太弱。
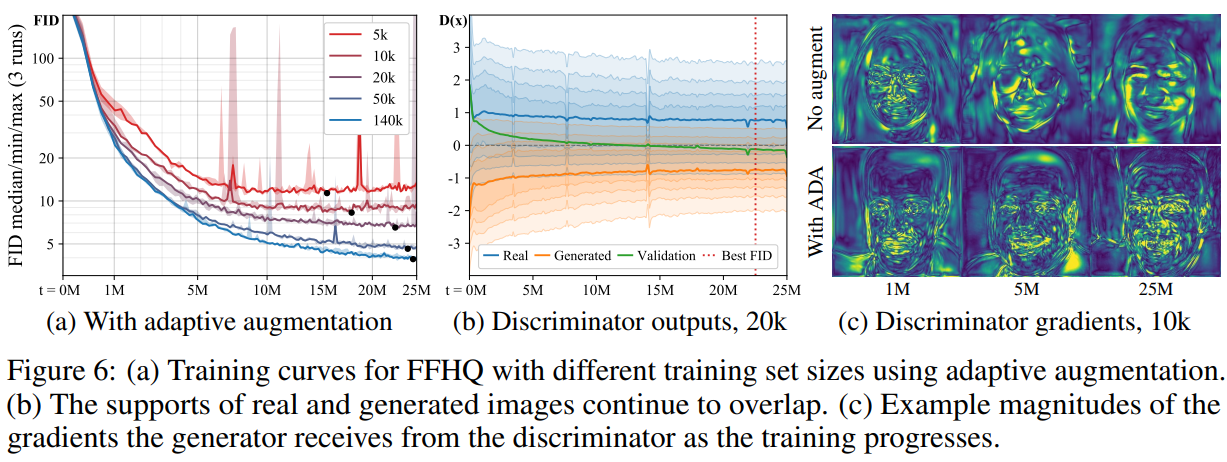
上图使用ADA重复了图的设置,发现无论数据集的大小如何,都可以实现收敛且不再过拟合。如果没有增强,生成器从判别器接收的梯度会随时间变得非常简单:判别器开始只关注少数特征,生成器可以自由创建没有意义的图像。使用ADA后,梯度场保持的更加详细,从而避免了情况的恶化。
部分实验结果
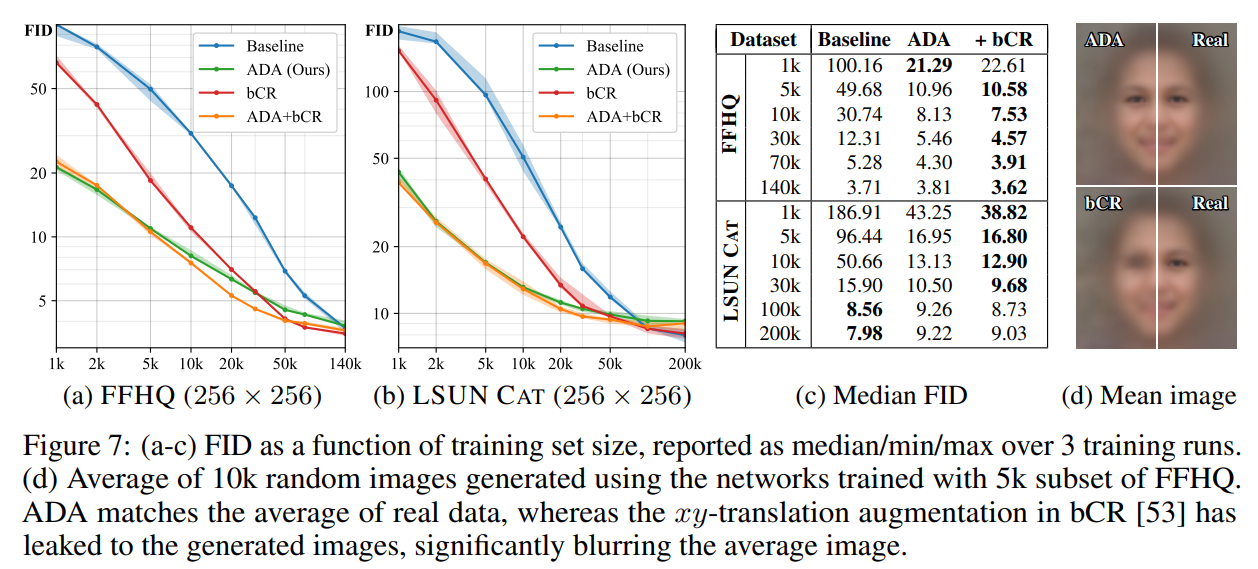
在FFHQ和LSUN数据集上的结果:
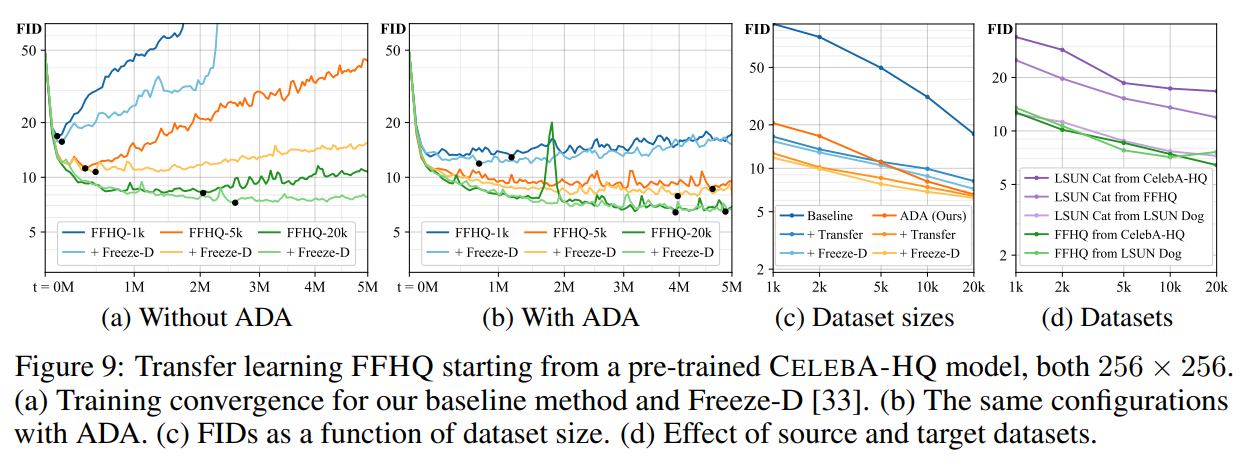
迁移学习:
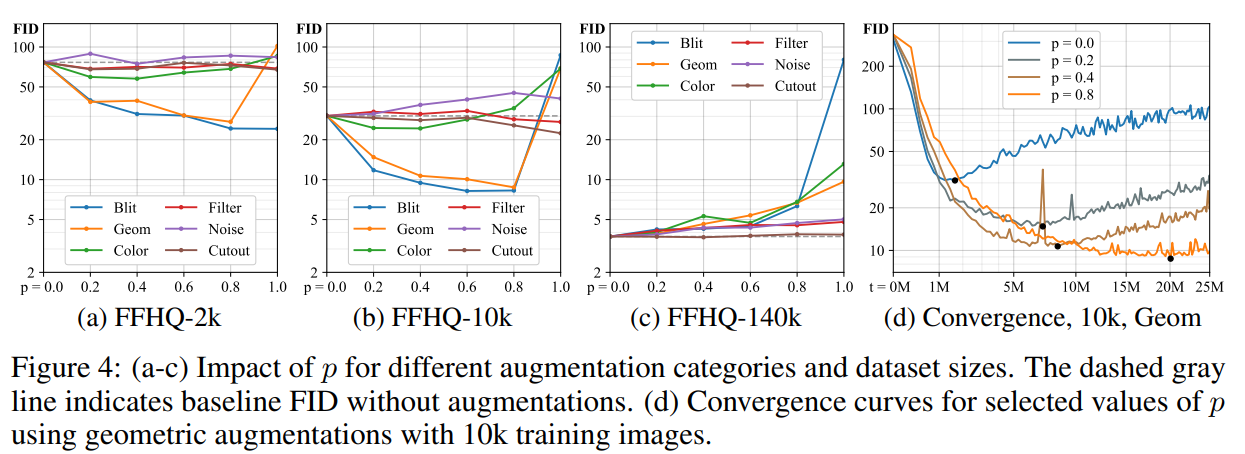
小数据集结果: