2020-12-17 update
MoCo,SimCLR,MoCo v2,SimCLR v2,SwAV,BYOL,SimSiam
自监督学习
参考博客:Contrastive Self-Supervised Learning
现在的自监督方法主要分为如下两类:生成方法和对比方法。
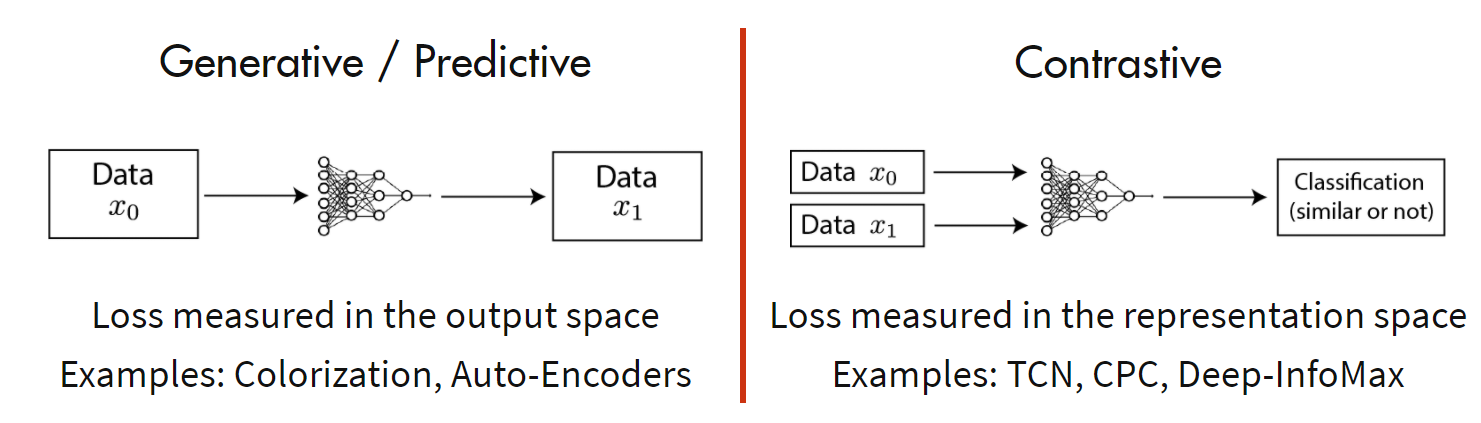
其中生成方法专注于像素空间的特征,使用像素级的损失可能导致此类方法过于关注像素级的细节,而不是抽象的语义信息,且基于像素的方法通常假设每个像素之间相互独立,难以有效建立空间关联及对象的复杂结构;而对比方法通过对比正样本和负样本来学习潜在空间地表征,利用该表征去完成下游任务。
具体来说,对于任意数据点,对比方法的目的是学习一个编码器使得:
其中,是的正样本,是的负样本,函数评估两个特征之间的相似度。
所以对于一个锚点数据,对比学习通过构建一个softmax分类器正确地对正样本和负样本进行分类,同时函数鼓励正对之间具有较大的相似性,而负对之间有较小的相似性,采用交叉熵损失,故对于一对正对,其对比学习的损失函数InfoNCE的一般形式为:
其中,是温度系数超参数,上式表明包含一个正对和个负对,最小化InfoNCE也可以解释为最大化和之间的互信息下界,即代表知道之后,的信息量减少的程度。
MoCo
MoCo的主要优化方向是增加负对数量,其通过一个先进先出的队列构建动态字典,使其具有大容量,同时使用基于滑动平均的动量编码器来保证一致性。原文:Momentum Contrast for Unsupervised Visual Representation Learning
阅读笔记:[论文阅读-contrast-learning-Momentum Contrast for Unsupervised Visual Representation Learning]
作者从字典查找的角度,解释了对比学习,即考虑一些已编码的query和一系列编码样本(即key),假设与匹配,则对比损失的目的是尽量使得与之间的距离减少而使得与其它key之间的距离增大,故损失函数为:
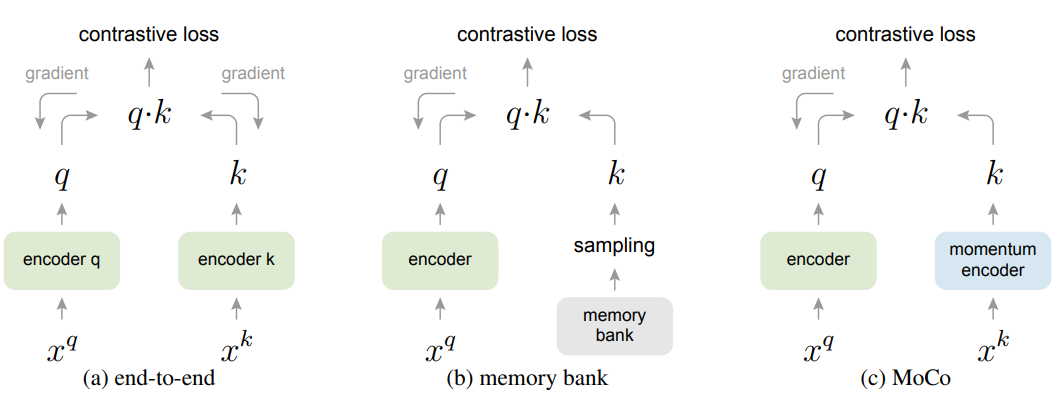
如上图,作者首先比较了与先前方法的区别,发现:
end-to-end方法使用当前batch的样本作为字典,key的编码一致性得到保证,但字典大小跟batch大小有关,受到显存大小限制;memory bank方法的字典由数据集中所有样本的表征组成,支持的字典更大,但由于不断迭代的编码器,其key的一致性较差。
由此,作者提出MoCo,使用队列的形式来保证字典的大小,且使用基于滑动平均的动量编码器来保证一致性,其网络模型如下图所示:
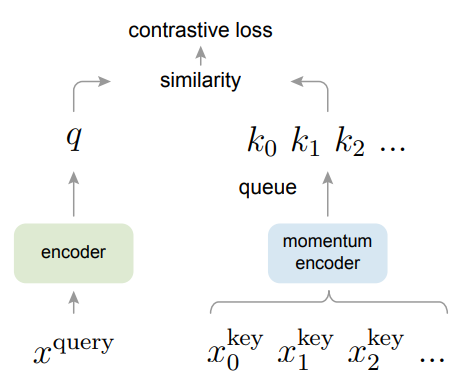
MoCo的训练步骤,初始化时两个编码器参数相同,对于每个mini-batch:
- 由两种随机增强得到和,再分别由两个编码器得到归一化后的
query和key,同时去掉的梯度更新; - 计算正对和负对的相似度矩阵,其中和是正对,和队列是负对,由此计算交叉熵损失并更新编码器;
- 动量更新编码器$f_k=mf_k+(1-m)f_q$;
- 更新字典,采用先进先出的队列,使得之前进行的入队,队首最早的
mini-batch的特征出队。
SimCLR
SimCLR采用end-to-end形式,主要探讨了数据增强方法、非线性变换、batchsize、损失函数等对对比学习的影响。原文:A Simple Framework for Contrastive Learning of Visual Representations
阅读笔记:论文阅读-contrastive-learning-A Simple Framework for Contrastive Learning of Visual Representations
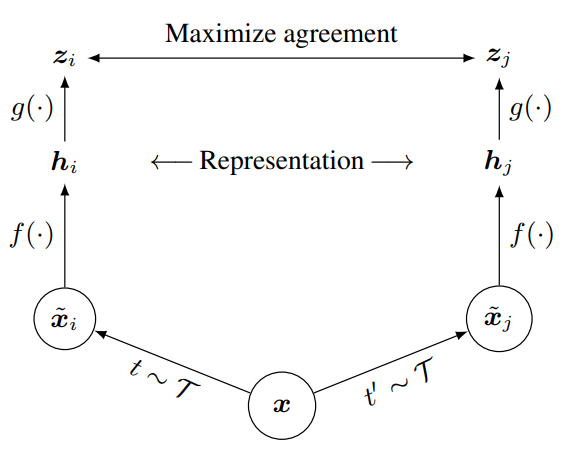
SimCLR通过在潜在空间的对比损失最大化相同数据示例的不同增强视图之间的一致性来学习表征,如上图所示,该框架主要由四部分构成:
data augmentation
对于任意给定的数据示例,随机转换为两个相关视图和,将其视为一个正对。本文使用三种增强方法:随机裁剪
random cropping,随机色彩失真random color distortions和随机高斯模糊random Gaussian blur。base encoder
其作用是从增强后的数据集中提取表征,得到,是经过平均池化层的输出。
projection head
其作用是将编码后的表征映射到应用对比损失的潜在空间中,本文使用两层的
MLP,得到,其中是ReLU。contrastive loss
若给定一个包含正对和的数据集,对比预测任务的目的是从中找出给定的对应的。
随机采样个样本,通过数据增强得到个数据点,由此得到个正对,对于每个正对,其余个样本均视为负样本。定义表示归一化的和之间的点积,即余弦相似度,由此正对的损失定义为
其中,是一个指示函数,当且仅当时取1。
作者通过实验发现了一系列结论:
- 数据增强的组合方式对于无监督对比学习有重要影响,无监督对比学习比有监督学习更需要数据增强,在本文使用随机裁剪和颜色失真的组合最有利于学习表征;
- 在表征和对比损失之间引入一个可学习的非线性变换,可以大幅提升表征质量(下游任务时仅保留编码器);
- 无监督对比学习收益于更大的模型,更大的
batchsize和更长的训练时间; - 具有对比交叉熵损失的表征学习得益于归一化嵌入和适当调整温度系数。
MoCo v2
MoCo v2采用了SimCLR的几个设计来改进MoCo:1)非线性投影网络;2)更多的数据增强方法。在较小的batchsize情况下,获得了更好的基准方法。原文:Improved Baselines with Momentum Contrastive Learning
阅读笔记:论文阅读-contrastive-learning-Improved Baselines with Momentum Contrastive Learning
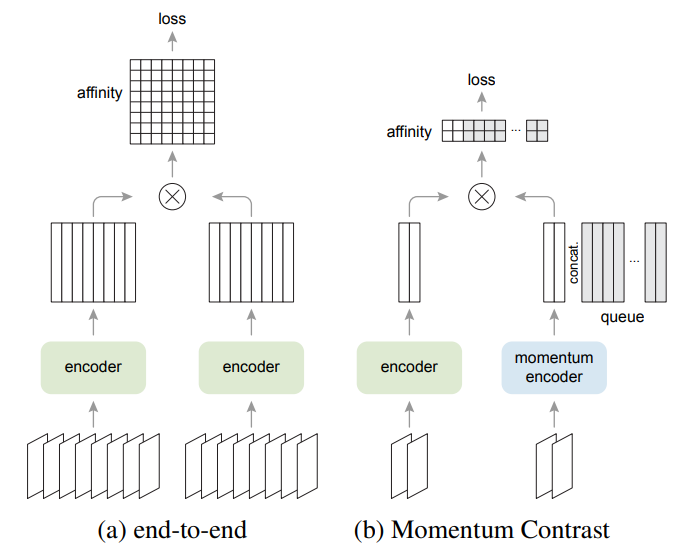
上图主要显示了MoCo跟SimCLR这种end-to-end方法的主要区别,即相似性矩阵的计算方法。作者在实验中主要比较了SimCLR跟MoCo,在较小的batchsize情况下,使用更少的内存和计算,获得了更好的基准方法。为了对比,学习率采用SimCLR的cosine衰减。
SimCLR v2
SimCLR v2主要针对半监督学习,并探讨了一系列模型结构选择是否有利于有监督微调和半监督学习。原文:Big Self-Supervised Models are Strong Semi-Supervised Learners
阅读笔记:论文阅读-contrastive-learning-Big Self-Supervised Models are Strong Semi-Supervised Learners
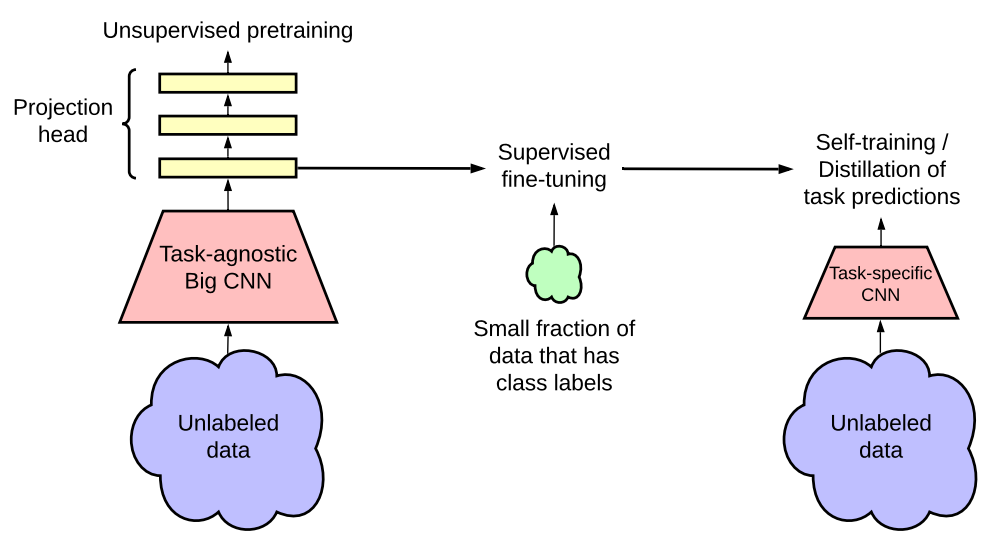
如上图所示,作者提出的半监督学习框架以task-agnostic和task-specific的形式利用无标签数据,即首先以task-agnostic的方式对无标签数据进行无监督预训练来学习一般表征;然后通过有监督微调使得一般表征适应于特定任务;最后以task-specific的方式使用无标签数据,进一步提高预测性能,并获得更小的模型,即使用经过微调的教师网络输入的标签在无标签的数据上训练学生网络。总结为包含三个主要步骤:1)预训练;2)微调;3)蒸馏。
使用
SimCLR v2无监督预训练相校于
SimCLR,SimCLR v2主要在三个方面进行了修改:- 为了充分利用预训练的能力,探索了更大的模型。将
ResNet-50(4x)替换为ResNet-152(3x)并加上selective kernels(SK是通道注意力机制),在的标签数据下提升了的top-1准确率; - 增加了非线性网络的能力,将两层的
MLP替换为三层,并从第一层中间层微调,在的标签数据下提升了的top-1准确率; - 受
MoCo启发,增加了一个memory网络,由于batchsize已经足够大,在的标签数据下提升了约的top-1准确率。
- 为了充分利用预训练的能力,探索了更大的模型。将
微调
与
SimCLR不同的是,保留部分投影头网络,使得task-agnostically的预训练网络微调适应特定任务,保留的网络跟有标签数据的数量共同影响微调的过程。通过无标签数据进行自训练/知识蒸馏
为了进一步改进目标任务的网络,本文直接利用无标签数据,即使用微调网络作为教师网络输入标签来训练学生网络。这个过程可以使用相同的模型架构(自蒸馏),从而进一步提高特定任务的性能;也可以使用较小的模型架构,从而得到更紧凑的模型。
SwAV
SwAV提出了一种基于在线聚类的自监督方法,减少对batchsize的敏感度,且无需memory bank和momentum encoder,并提出了一种新的数据增强方式multi-crop。原文:Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
阅读笔记:论文阅读-contrastive-learning-Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
参考博客:representation learning与clustering的结合(3): SwAV
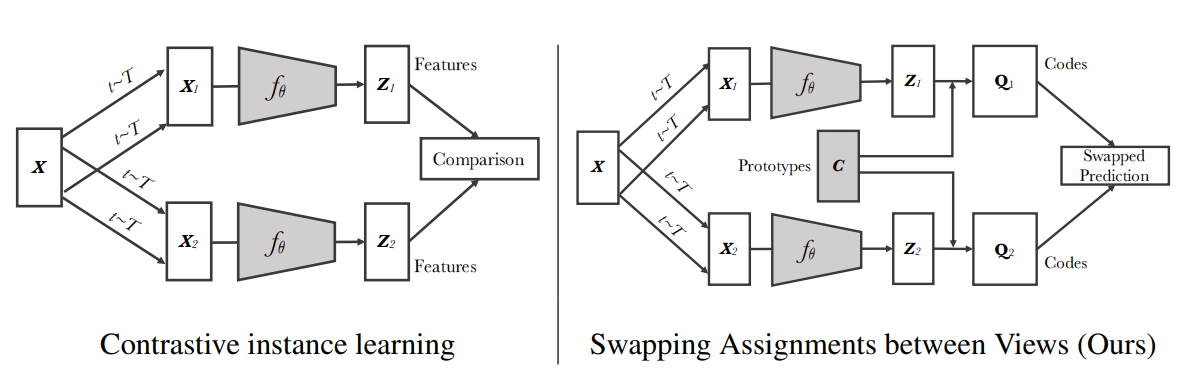
如上图,对于一个batch的图像,应用从图像变换集合中采样的变换,并通过应用非线性映射将增强视图映射到到向量表示,再投影到单位球面上得到个特征向量,通过匹配个可训练的prototypes和codes,假设的维度均为,则,,,故每个元素表示第个样本与第个聚类中心的相似度。
不同于以前的方法使用对比损失去显式比较两两特征,SwAV基于在线聚类,旨在加强同一图像的不同视图之间的映射的一致性。作者定义了一个Swapped prediction problem:
即使用codes和来比较特征和,如果两个特征捕获了相同的信息,则从另一个特征预测codes也是可行的。损失的每一项表示code和概率值的交叉熵损失,该概率由和中所有原型的点积经softmax得到,而对于code的计算,文章通过最大化特征和prototype之间的相似度求解:
在求解时,作者使用了如下的策略:
本来离线的聚类需要遍历整个数据集,而在线聚类只能在当前的
batch中计算,故采用均分约束来防止崩溃解,使得在mini-batch的所有实例都被原型等分,即保证mini-batch中不同图像的codes是不同的,从而防止出现每个图像都有相同的codes这种崩溃解情况;可以将理解为标签,理解为预测值,一般来说标签采用
one-hot的形式,本文验证采用连续值更好。作者解释可能是变为离散值后收敛速度变快,优化过于激进,作者在实现时采用迭代以下公式求解:其中和为重正则化向量,由
Sinkhorn-Knopp算法迭代计算得到。
此外,作者也提出了一种新的数据增强方法,使用两个正常分辨率的crop和采样个低分辨率的部分图像信息的crop进行混合。
BYOL
BYOL不使用负样本对,且对各种batchsize和图像增强方法不敏感。原文:Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
阅读笔记:论文阅读-contrastive-learning-Bootstrap Your Own Latent A New Approach to Self-Supervised Learning
参考博客:Understanding self-supervised and contrastive learning with “Bootstrap Your Own Latent” (BYOL)
现有的自监督学习方法建立在跨视图的预测框架之上,即通过预测同一图像的不同视图来学习表示,该预测问题为一个图像的增强视图的表示应该预测同一幅图像的另一个增强图像的表示,但直接将预测问题投射到表示空间可能会导致崩溃解:即所有图像的不同视图的表示不变。
对比方法改为:从一个增强视图的表示中,学会区分同一图像的另一个增强视图的表示和不同图像的增强视图的表示。但是这种情况会需要比较每一个增强视图的表示与许多负样本的表示,文章则探讨了在防止崩溃解且保持高性能时,负样本是否必不可少。
为了防止崩溃解,一个直接的解决方案是使用一个固定的随机初始化的网络来产生需要预测的目标,在ImageNet上准确率达到,远高于随机初始化的网络本身,故BYOL的核心:从一个给定的特征(target),通过预测目标表征来训练一个新的、潜在增强的表征(online),在此基础上使用一个新的online网络作为下一次训练的新的target网络,在实践中,这里使用一个缓慢移动的online网络的指数平均作为target网络,而不是固定的checkpoints。
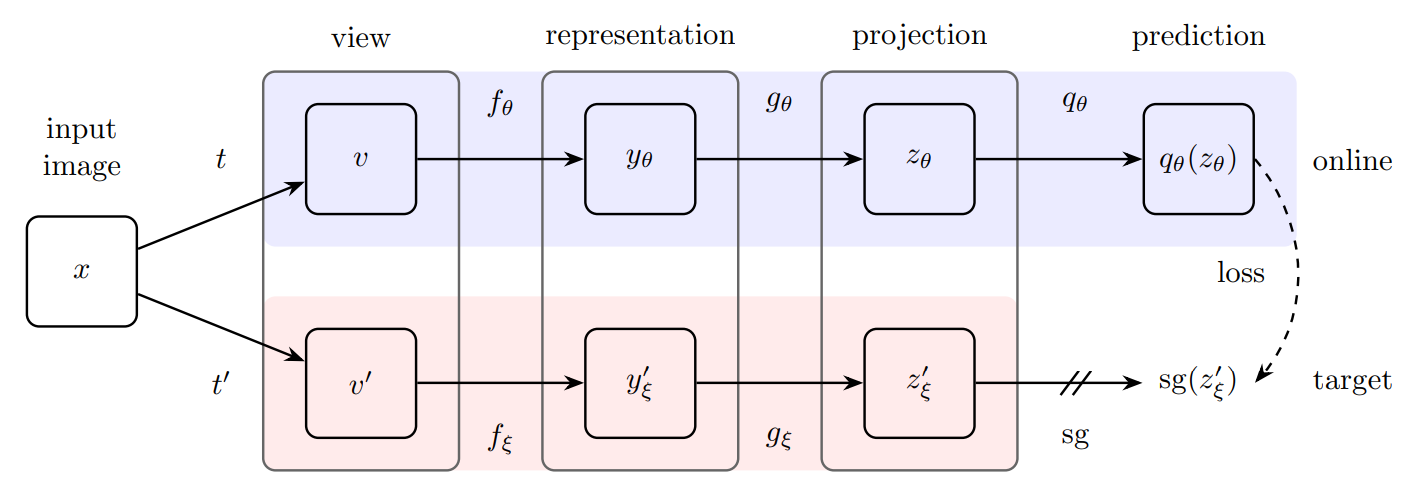
如上图所示,BYOL包含两个神经网络:online和target网络。online网络权重为,由三个阶段组成:encoder、projector和predictor,target网络则权重为,目的是提供训练online网络的回归值,其参数由online网络的参数进行指数滑动平均。输出的预测并分别做归一化,得到和,则采用均方误差,其损失如下:
对于对称损失,则额外将输入online网络,v输入target网络,计算损失,则总损失为,但反向传播每次只更新,这里称为stop-gradient,即:
其中是优化器的学习率,最后训练后,仅保留encoder。
对于防止崩溃解的解释
BYOL的直觉解释是从stop-gradient出发,假设BYOL的predictor是最优的,BYOL关于的更新是基于期望条件方差的梯度,单纯丢弃online投影中的信息不能降低条件方差,且关于不进行梯度更新而是使得更接近,确保predictor在训练过程中接近最优性。
但参考博客通过实验发现:1)在删除BN后,BYOL的性能跟随机网络差不多;2)BN的存在隐含了一种对比学习。即无论输入多么相似,BN都会重新调整输入的分布,由此避免崩塌。
SimSiam
SimSiam对孪生网络进行了研究,发现stop-gradient操作在防止崩溃解中发挥了关键的作用。原文:Exploring Simple Siamese Representation Learning
阅读笔记:论文阅读-contrastive-learning-Exploring Simple Siamese Representation Learning
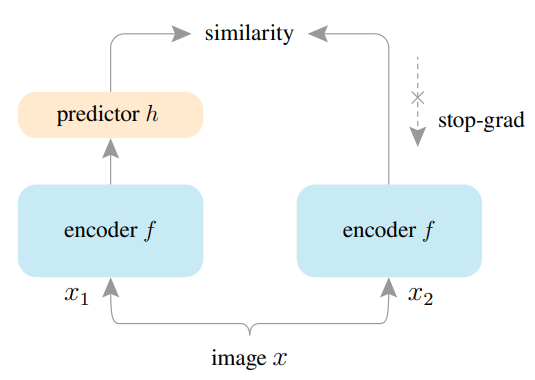
上图为本文的网络框架,输入是图像的两个随机增强视图和,两个视图通过相同的编码器提取特征并映射到高维空间,此外一个预测模块将其中一个视图转换并于另一个视图匹配,该过程为和,则损失函数为最小化负余弦相似度:
其中为归一化,等价于归一化向量的均方误差,此外结合stop-gradient操作定义了一个对称损失,则:
即对于第一项,不会从接收梯度信息,但在第二项会从接收梯度信息,则相反。
和其它方法的比较
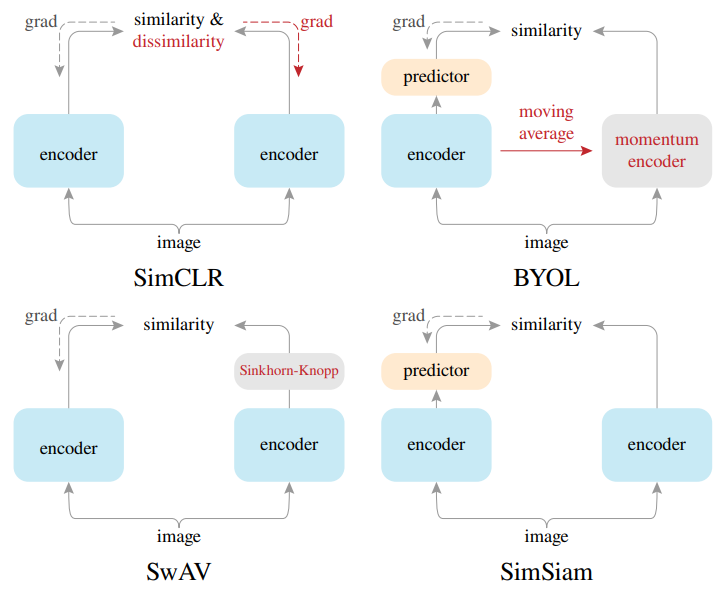
如上图,SimSiam可以作为一个中心来关联几个现有的方法:SimCLR依赖于负采样以避免崩溃解,SimSiam可以看作是SimCLR without negative;SwAV通过在线聚类来避免崩溃解,SimSiam可以看作是SwAV without online clustering;BYOL使用动量编码器,SimSiam可以看作是BYOL without the momentum encoder。
对于防止崩溃解的解释
文章的假设是SimSiam是一个类似于EM算法的实现。它隐式地涉及到两组变量,并解决两个潜在子问题,stop-gradient的出现是引入额外的一组变量的结果,损失如下:
其中,是特征提取网络,是增强方法,是图像,额外引入一个,它是的表示,下标表示使用图像索引访问图像的子向量,其大小正比于图像数量。所以优化问题如下:
描述形式如同k-means,是编码器可学习的参数,类似于聚类中心,是的表征,类似于样本的对应向量(如k-means的one-hot向量),由此通过交替求解两个子问题:
同时作者由实验也验证了,对于避免崩溃起关键作用的是stop-gradient操作。
相关阅读推荐
- Self-Supervised Representation Learning
- Contrastive Self-Supervised Learning
- Prototypical Contrastive Learning: Pushing the Frontiers of Unsupervised Learning
- 一文梳理无监督对比学习(MoCo/SimCLR/SwAV/BYOL/SimSiam)
- 计算机视觉中的自监督表示学习近期进展