SimCLR v1链接:论文阅读-contrastive-learning-A Simple Framework for Contrastive Learning of Visual Representations
动机
- 视觉表示的自监督学习进展较快,想要探讨半监督训练(少量有标签数据,大量无标签数据)的方法,并探讨一系列模型结构选择是否有利于有监督微调和半监督学习。
贡献
- 实验表明,半监督学习(通过
task-agnostic使用无标签数据),标签越少,越可能受益于一个更大的模型,更大的自监督模型具有更高的标签有效性,即使它们更可能潜在过拟合,但当只对少量标签示例进行微调时,它们的表现会显著更好。 - 尽管大模型对于学习一般表征很重要,但当涉及特定目标任务时,额外的容量可能不是必要的,因此针对特定任务的无标签数据的使用,可以进一步提高模型的预测性能,并迁移到更小的网络中。
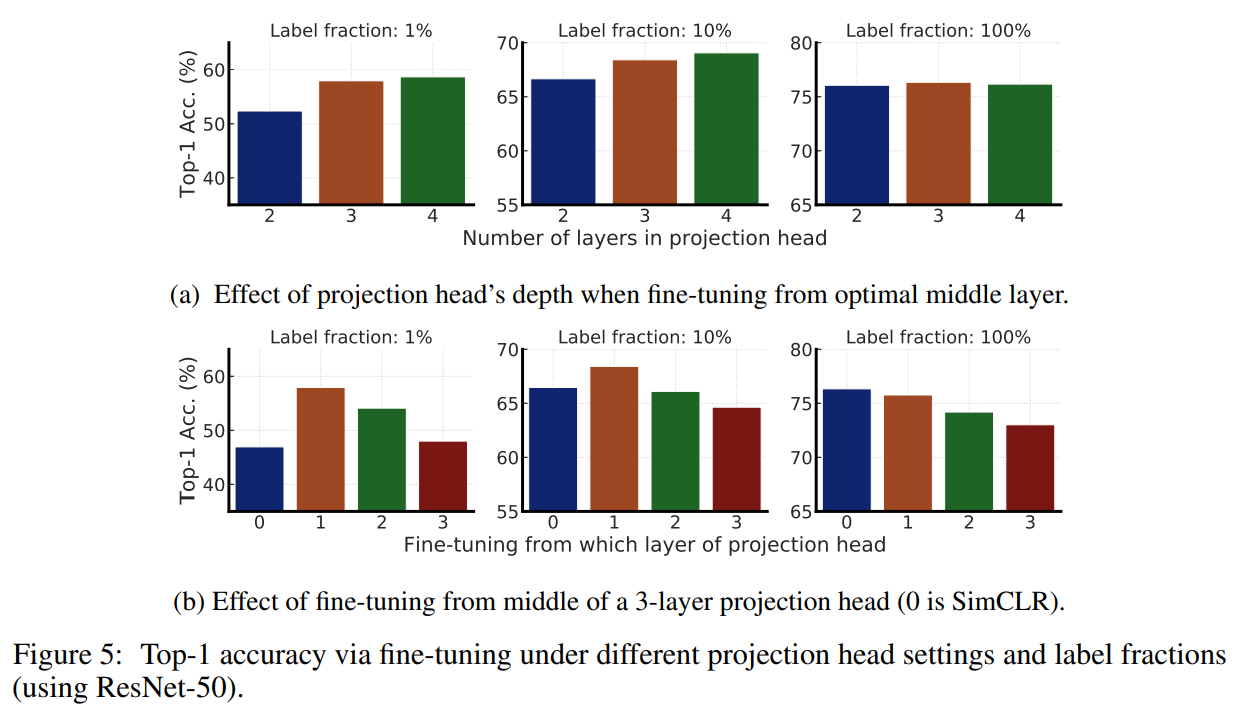
- 进一步证明了非线性变换(即投影头)的重要性,更深的投影头不仅可以提高线性评估的表征质量,还能提高从投影头中间层进行微调时的半监督性能。
本文的方法
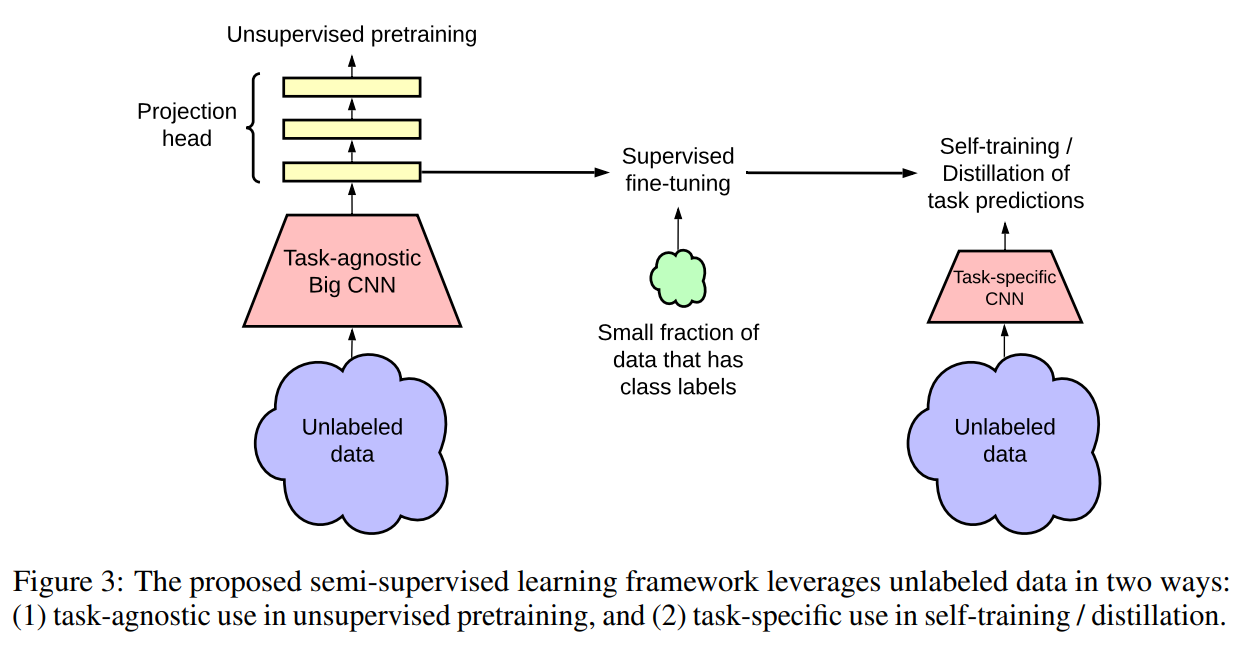
半监督学习常用的两种方法:1)首先进行无监督的预训练,再进行有监督的微调,该方法以一种task-agnostic的形式使用无标签数据,因为监督标签只在微调时使用;2)在监督学习时直接利用无标签数据作为一种正则化形式,该方法以task-specific的形式使用无标签数据,以鼓励不同模型或不同数据增强条件下对无标签数据的类别标签预测的一致性。
本文提出的半监督学习框架以task-agnostic和task-specific的形式利用无标签数据,即首先以task-agnostic的方式对无标签数据进行无监督预训练来学习一般表征;然后通过有监督微调使得一般表征适应于特定任务;最后以task-specific的方式使用无标签数据,进一步提高预测性能,并获得更小的模型,即使用经过微调的教师网络输入的标签在无标签的数据上训练学生网络。故本文方法如上图所示,包含三个主要步骤:1)预训练;2)微调;3)蒸馏。
使用
SimCLR v2无监督预训练同
SimCLR一样,对于正对样本,对比损失函数为:相校于
SimCLR,SimCLR v2主要在三个方面进行了修改:- 为了充分利用预训练的能力,探索了更大的模型。将
ResNet-50(4x)替换为ResNet-152(3x)并加上selective kernels(SK是通道注意力机制),在的标签数据下提升了的top-1准确率; - 增加了非线性网络的能力,将两层的
MLP替换为三层,并从第一层中间层微调,在的标签数据下提升了的top-1准确率; - 受
MoCo启发,增加了一个memory网络,由于batchsize已经足够大,在的标签数据下提升了约的top-1准确率。
- 为了充分利用预训练的能力,探索了更大的模型。将
微调
与
SimCLR不同的是,保留部分投影头网络,使得task-agnostically的预训练网络微调适应特定任务,保留的网络跟有标签数据的数量共同影响微调的过程。通过无标签数据进行自训练/知识蒸馏
为了进一步改进目标任务的网络,本文直接利用无标签数据,即使用微调网络作为教师网络输入标签来训练学生网络。具体地说,在不使用真正标签的情况下,最小化如下的蒸馏损失:
其中,,是温度系数,产生的教师网络在蒸馏时固定,只有产生的学生网络在训练。
虽然本文只使用无标签数据蒸馏,但当有标签数据数量较多时,可以使用加权组合将蒸馏损失与真实示例结合起来:
这个过程可以使用相同的模型架构(自蒸馏),从而进一步提高特定任务的性能;也可以使用较小的模型架构,从而得到更紧凑的模型。
部分实验结果
采用ImageNet ILSVRC-2012数据集,随机采样或的有标签数据,在训练时均采用LARS优化器。
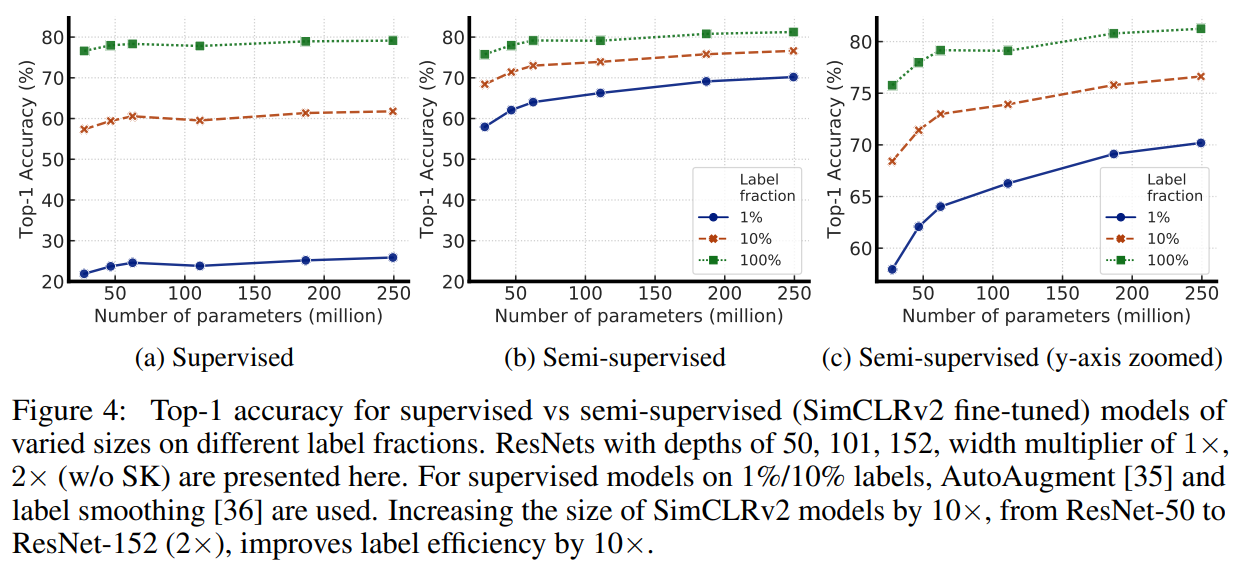
模型越大,标签有效性越高
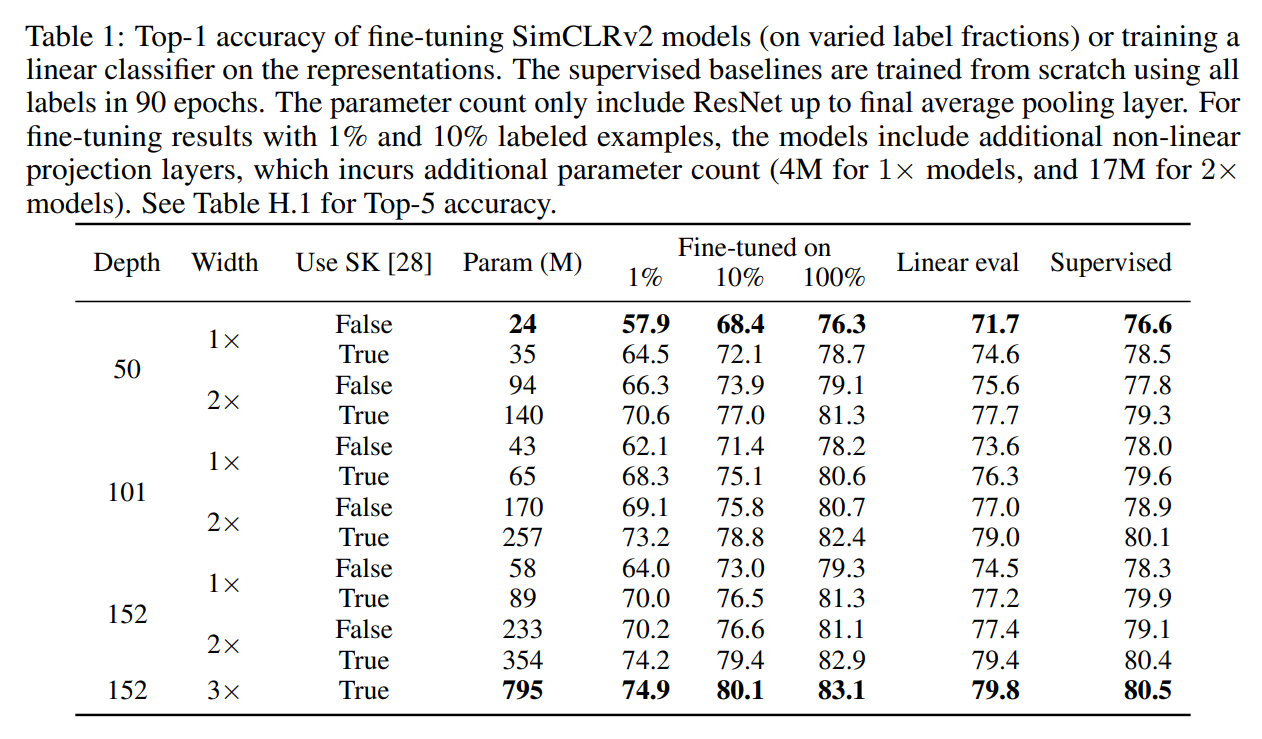
更大/更深的投影头可以提升表征学习
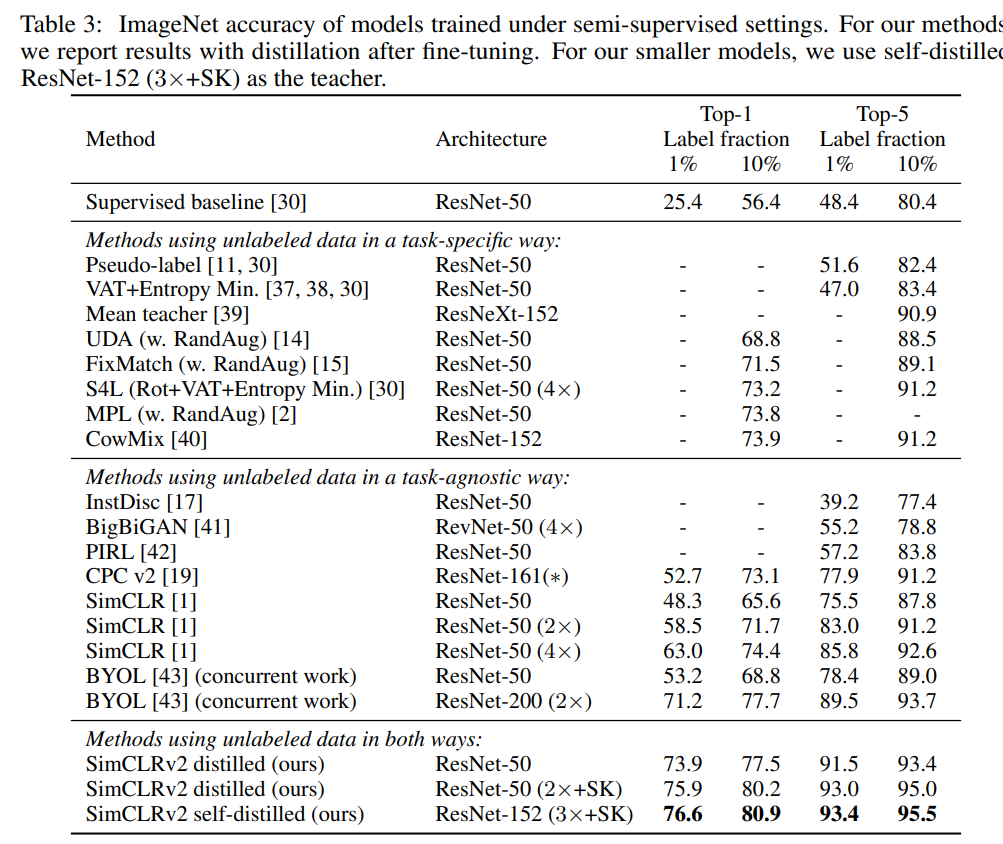
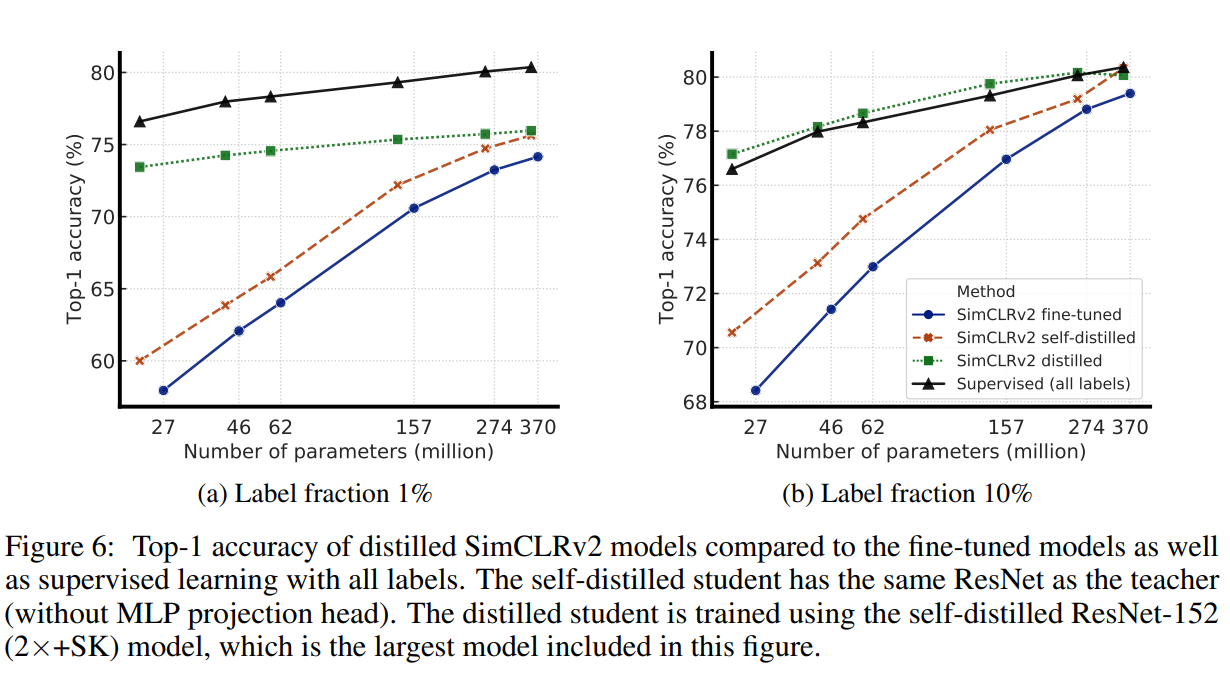
使用无标签数据的蒸馏改进了半监督学习

跟其它半监督方法的比较