动机
- 基于潜在空间对比学习的判别方法显示出了很大的前景,但是现有的方法需要专门的架构或
memory bank。
贡献
- 提出了一个简单的视觉表示对比学习框架
SimCLR,其简化了现有的对比自监督学习算法而不需要专门的架构或memory bank; - 探讨了对比学习主要组成部分的作用,表明1)数据增强的组合方式对于无监督对比学习有重要的影响;2)在表征和对比损失之间引入一个可学习的非线性变换(
MLP),可以大幅提升学习的表征质量;3)具有对比交叉熵损失的表征学习得益于归一化嵌入和适当调整温度系数;4)收益于更大的batchsize,更长的训练,以及更深更广的网络。
本文的方法
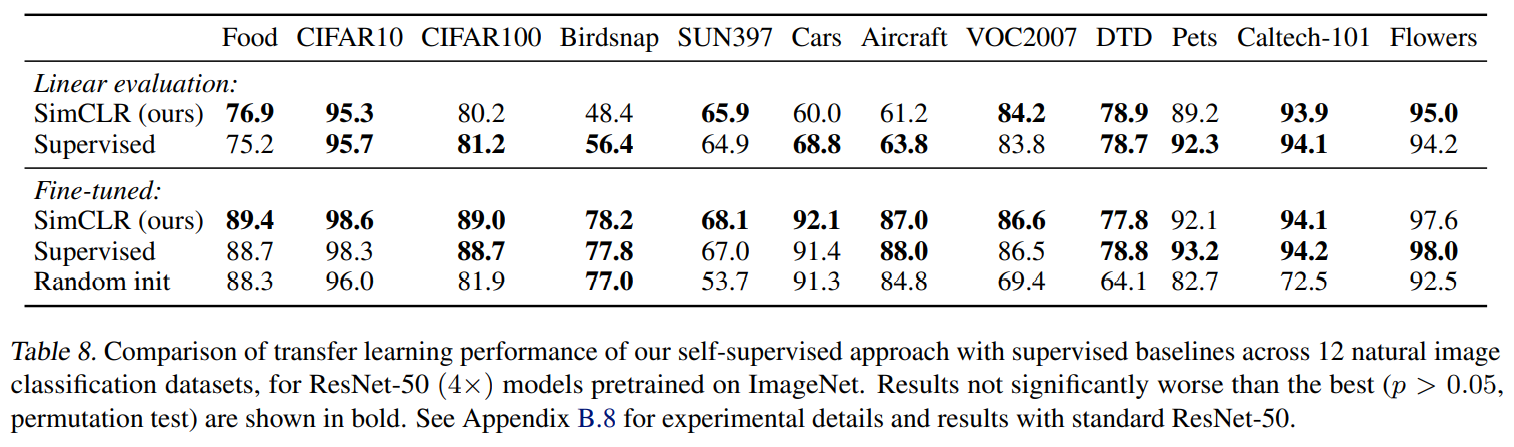
SimCLR通过在潜在空间的对比损失最大化相同数据示例的不同增强视图之间的一致性来学习表征,如上图所示,该框架主要由四部分构成:
data augmentation
对于任意给定的数据示例,随机转换为两个相关视图和,将其视为一个正对。本文使用三种增强方法:随机裁剪
random cropping,随机色彩失真random color distortions和随机高斯模糊random Gaussian blur。base encoder
其作用是从增强后的数据集中提取表征,得到,是经过平均池化层的输出。
projection head
其作用是将编码后的表征映射到应用对比损失的潜在空间中,本文使用两层的
MLP,得到,其中是ReLU。contrastive loss
若给定一个包含正对和的数据集,对比预测任务的目的是从中找出给定的对应的。
随机采样个样本,通过数据增强得到个数据点,由此得到个正对,对于每个正对,其余个样本均视为负样本。定义表示正则化的和之间的点积,即余弦相似度,由此正对的损失定义为:
其中,是一个指示函数,当且仅当时取1,是温度参数。对所有mini-batch中的正对施加该损失,称该损失为NT-Xent(归一化的温度尺度的交叉熵损失)。

本文方法不使用memory bank训练模型,而是采用大的batchsize,为了克服大的batchsize使用SGD/Momentum进行优化时可能导致的训练不稳定问题,论文对每个batchsize都采用了LARS优化器。
此外,由于采用ResNet架构,对于数据并行的分布式训练,BN的均值和方差通常在每张卡上进行局部的聚合,而对比学习中正对在同一张卡中计算,模型可能利用局部的信息提高预测精度而不改善学习的表征,故本文使用Global BN聚合所有device上的均值和方差,其它方法包括Shuffle BN或者LN。
数据增强
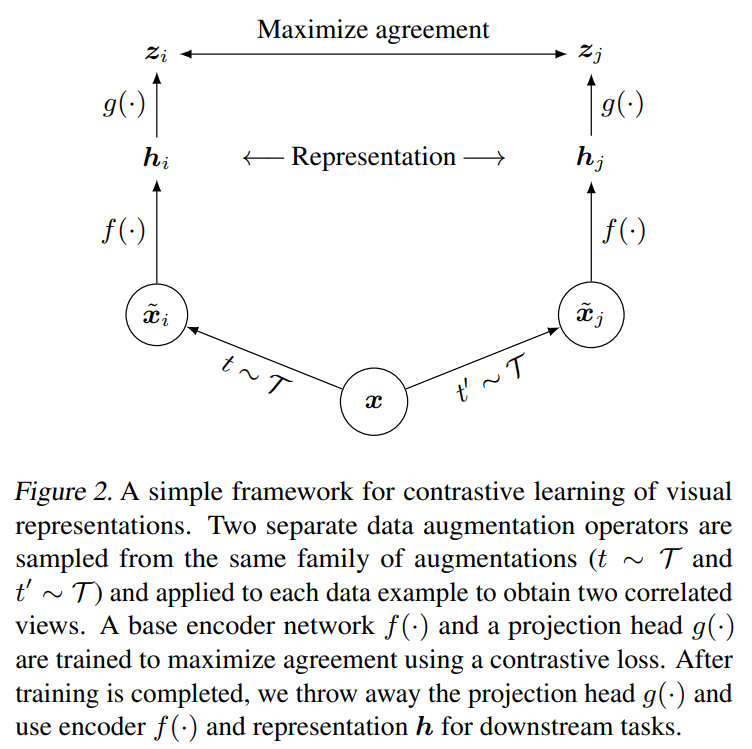
目前数据增强方法没有被定义为对比预测任务的标准方法,现有的方法主要通过改变结构来实现对比预测任务,作者证明可以通过对目标图像进行数据增强可以创建包含下述两种预测任务的一系列预测任务,即整体-局部预测和邻近预测。
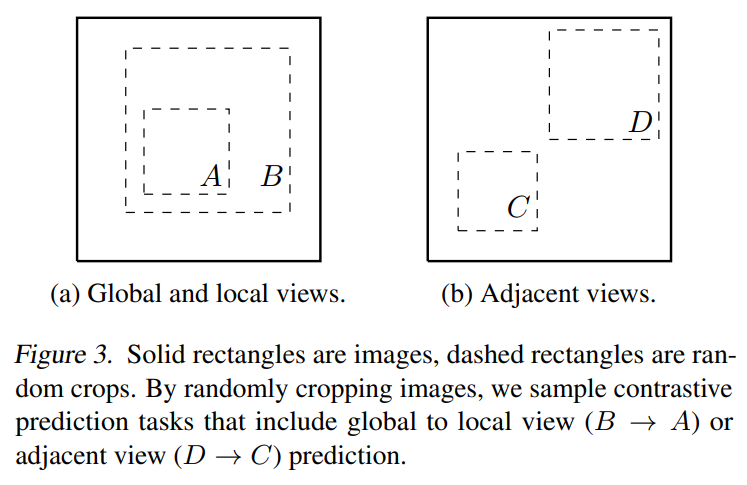
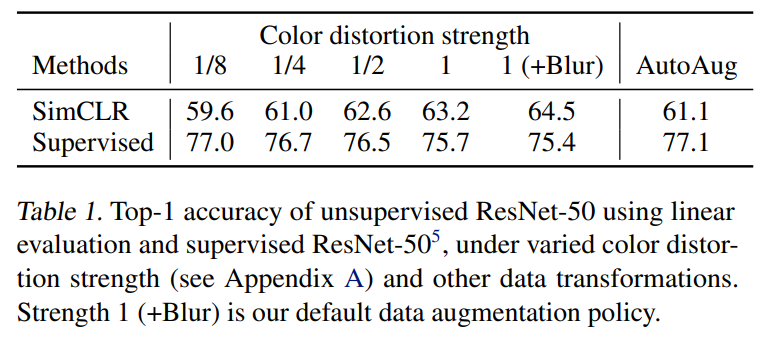
文章只采用随机裁剪random cropping,随机色彩失真random color distortions和随机高斯模糊random Gaussian blur三种增强方法,采用非对称的数据转换设置,即先随机裁剪图像并调整到相同的分辨率,对其中一个分支应用目标转换,另一个分支则做恒等变换,这种非对称的数据增强会伤害性能,但在实质上不会改变其影响。由下图可以发现,组合增强方法会增大预测难度,但是能提升表征质量,最后作者发现,随机裁剪和颜色失真的组合最有利于学习表征。
且作者发现对比学习比有监督学习更需要数据增强。
编码器和投影头的结构
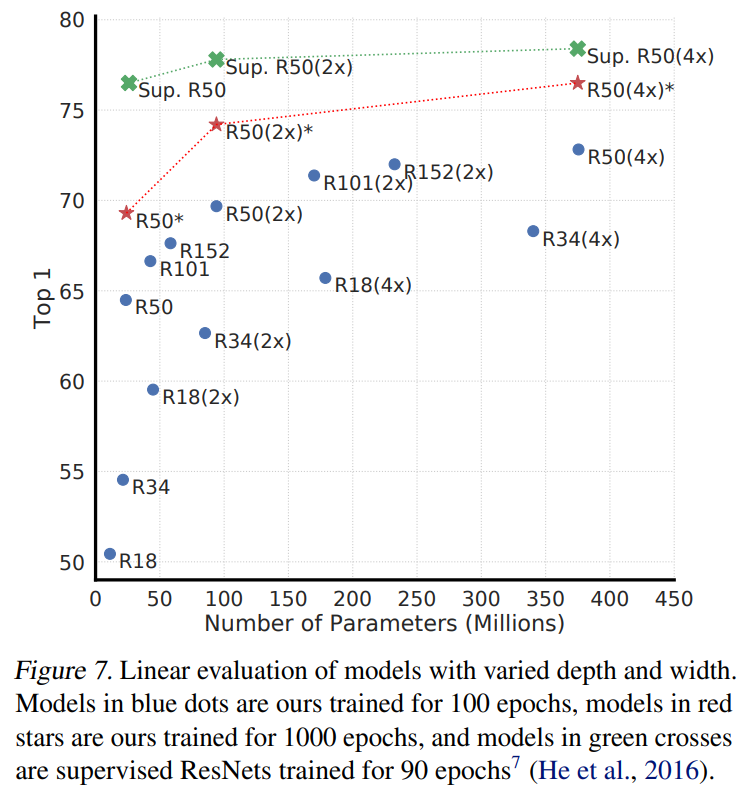
- 无监督对比学习收益于更大的模型
非线性投影头提高了表征质量
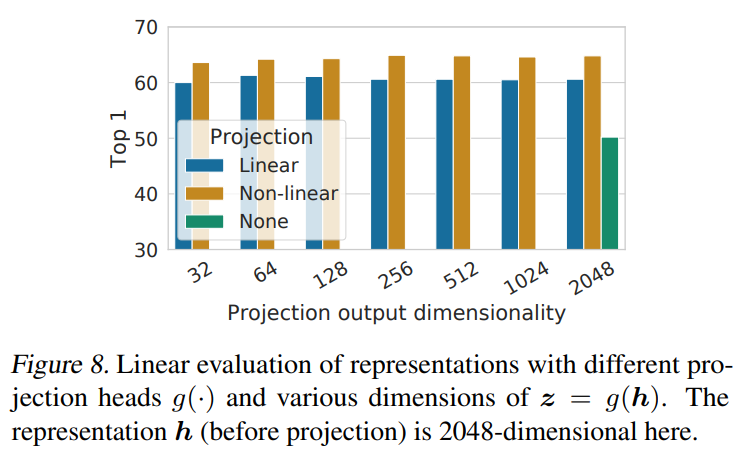
即使使用非线性投影,投影头前的隐藏层比投影头后的层的表征更好。作者通过对非线性投影之间的映射和使用非线性投影后的映射,发现比保留了更少的信息,作者认为是删除了一些对下游任务有用的信息,如颜色等,这样使得在训练过程中这些信息更多在阶段形成。

损失函数和batchsize
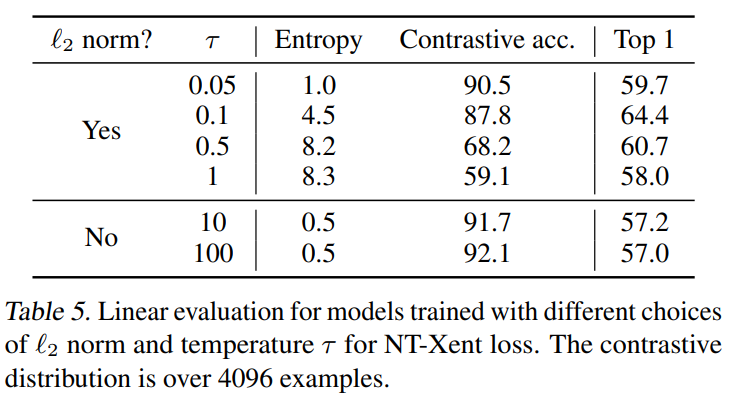
温度可调的归一化交叉熵损失比其他方法更有效

作者额外测试了使用/不使用归一化(即余弦相似度/点积)的情况和不同的对对比任务精度和表征的性能,发现不使用归一化会提升对比任务精度,但是会降低表征的线性分类结果。
对比学习收益于更大的batchsize和更长的训练时间
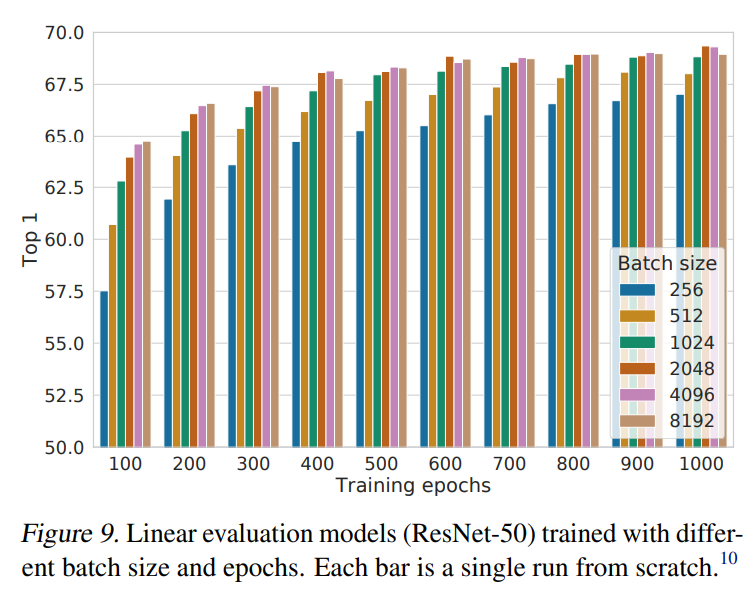
部分实验结果
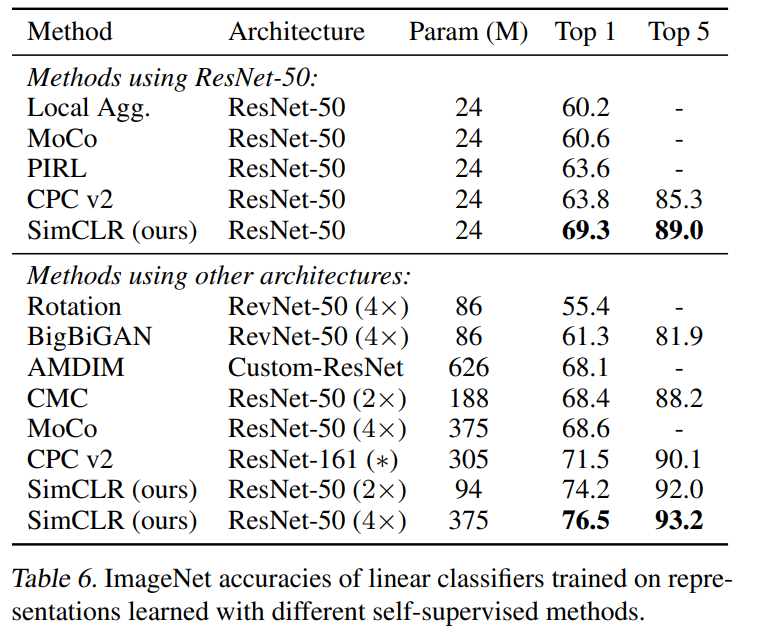
无监督的线性分类结果
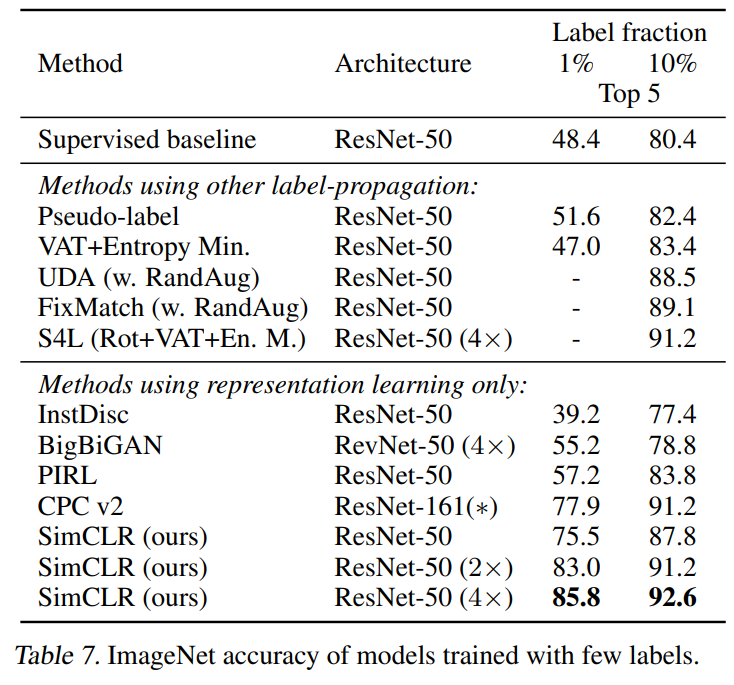
半监督的线性分类结果
迁移学习的结果