动机
视觉关系检测(VRD)是通过提供一个
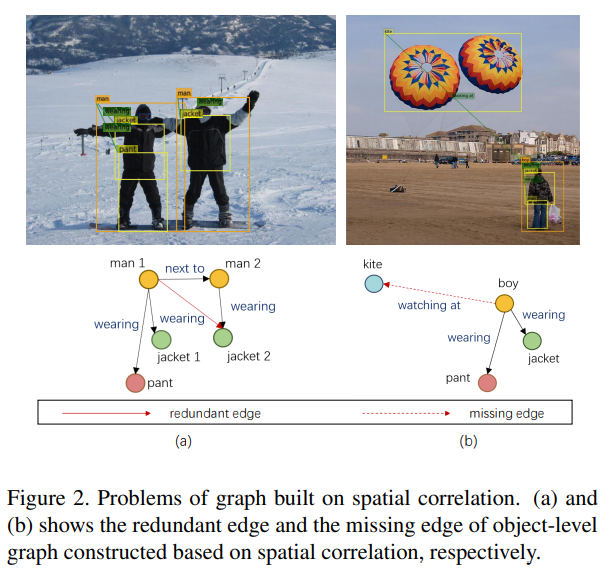
主语-谓语-宾语的结构三元组来描述两个对象之间的关系,现有的基于图的方法主要通过对象级图来表示关系,忽略了对于三元组依赖关系的建模;先前使用图网络的方法是基于对象的空间相关性来构建的,仅基于空间相关性构造图会带来一些不合适的边,如冗余边或缺失边,而先验知识有助于图的构建过程,并直接参与关系推理。
贡献
提出了一个层次图注意力网络(HGAT)去探索
object-level和triplet-level的三元关系,通过显式地建模三元组之间的依赖关系,可以在关系推理中加入更多的上下文信息;在图中引入先验知识和注意力机制,以减轻初始化图时不准确带来的不利影响,在注意力机制下,节点可以根据视觉或语义特征的相关性,通过给这些节点分配可学习的权重,来关注邻节点的空间和语义特征。
本文的方法
问题定义:
对于一个给定图像,视觉关系检测的目的是提供几个关系三元组,如主语-谓语-宾语,定义和为对象集合和谓词集合,则关系集合可以被定义为,则视觉关系检测的概率模型可以被定义为:
其中和是subject和object的bounding box,而和是对应的bounding box的得分。
框架:
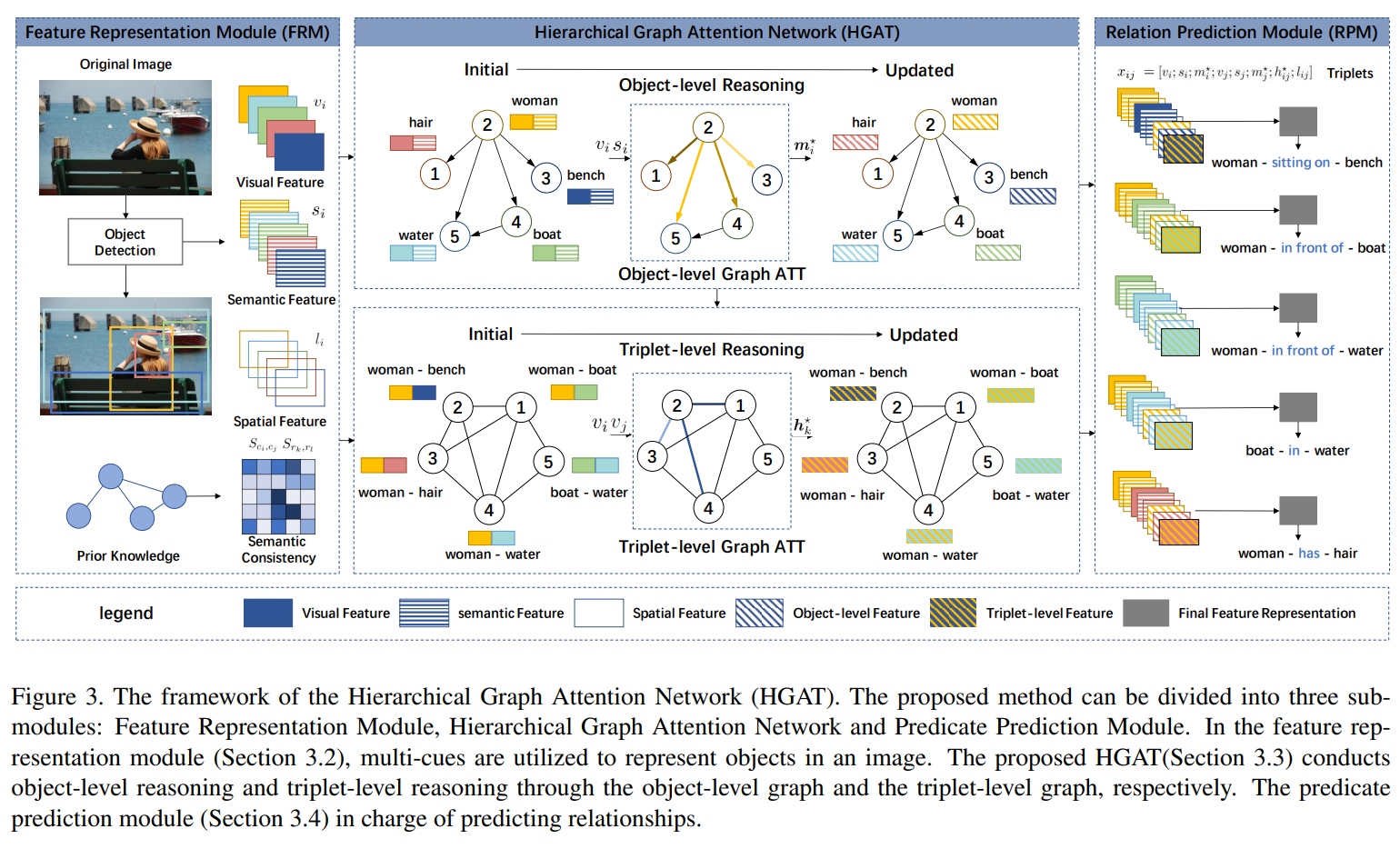
如上图所示,本文框架可分为三个子模块:特征表示模块、层次图注意力网络和谓词预测模块。在特征表示模块中,目标检测器生成带有边框和标签的目标区域候选,然后给出每个目标的视觉、空间和语义线索以及成对目标对应的相对特征;接下来,层次图注意力网络采用层次图结构进行 object-level和triplet-level的推理,对于每个节点,注意力机制为其相邻节点分配合适的权值,并得到最终的节点表示;而谓词预测模块则负责由已有的图预测关系。
特征表示
特征表示模块以图像为输入,输出为具有视觉特征、空间特征和语义特征的边框。
候选区域生成
采用Faster R-CNN,首先对RPN产生的候选区域进行采样,其中,再对其执行的NMS,保留置信度大于的候选区域作为检测到的目标,并收集得到所有的对象位置和标签。
特征提取
在特征提取中,考虑了视觉表征、空间特征和语义嵌入。
视觉特征
对于一个关系实例,表示其对应的主语、谓语、宾语的
bounding box,其中指的是和的并集,它用以捕获周围的上下文,本文采用VGG-16,并对RoI Pooling的特征作为,视觉特征被表示为。空间特征
为了得到
bounding box的相对空间特征,采用box regression的思想,假设为到的box delta,和分别表示和之间的归一化距离和iou,且和的并集记为,则主语和宾语的相对空间位置定义为:语义特征
同一对对象之间可能存在不同的关系,相同的谓词也可能用来描述不同类型的对象对。文章采用语义嵌入层将对象类别映射为词嵌入,然后将主语和宾语的嵌入向量连接起来并通过一个全连接层学习对象对表示,语义特征用表示。
先验知识蒸馏
为了表示语义一致性,故利用先验知识数据中每对概念的共现累积数,假设先验知识数据中有个实例,设表示概念和共现的频率,表示概念出现的频率,基于点互信息定义语义一致性,即当和独立出现或者共现的频率比它们独立出现的频率低时,这个值为0,否则为正,如果共现的可能性大于单独出现的可能性,这个值会变大:
三元组的语义一致性计算方式相同,实验中的先验知识来自关系检测数据集。
层次图注意力网络
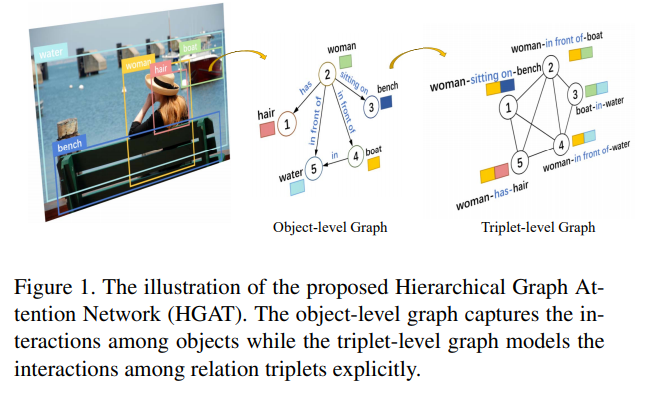
为了在图像中对object-level和triplet-level的依赖进行建模,需要考虑两种类型的图。一种是对象级图,它对对象之间的交互进行建模并进行对象级推理。另一种是基于三联体之间的交互构造的三联体图,进行三联体推理。
对象级推理
对象级图构建
对象级图包含一个节点集和一个边集,每个节点表示一个对象,由一个边界框和对应的嵌入属性组成,每条边表示和之间的谓词,其中关系三元组和是不同的实例,故为有向图。
利用和来估计两个目标候选的空间相关性,空间图被定义为:
此外,利用语义一致性定义语义相关性:
所以,对象级图为,为或操作。
对象级注意力
将视觉和语义的联合特征作为节点的属性,则属性向量可以表示为,图注意力机制可表示为:
其中表示生成的隐藏层特征,注意力系数的定义为:
其中,为投影矩阵,为偏置项,是根据每条边的方向选择的变换矩阵。
三元组级推理
三元组级图构建
某些关系更有可能同时发生,如
person-ride-bike更可能与car-on-street而不是elephant-on-grass共同出现,三元组级图是用来捕获关系实例之间的依赖关系的。假设节点集表示可能的三元组关系,边集表示三元组之间的相互作用,则三元组级图是一个无向图,被定义为:三元组级注意力
节点的属性特征为三元组的视觉特征,记为,生成的隐藏层特征表示为:
其中,为投影矩阵。
谓词预测
谓词预测模块的输入是来自对象级推理和三元组级推理的特征,输出是几个关系三元组,第个对象和第个对象之间交互的最终表示是上述特征的串联:,那么第个和第个对象之间的谓词类别置信度为,其中为映射交互嵌入以匹配谓词类别的嵌入矩阵,实验中使用了多类别交叉熵损失。
部分实验结果
数据集:Visual Relationship Detection (VRD),visual Genome(VG);VRD数据集包含5000个图像,100个对象类别和70个谓词类别;VG采用简化版本,包含99658张图像,200个对象类别和100个谓词类别。
评价指标:Predicate Detection (Predicate Det):给定一个ground truth对象的位置和类别,网络预测对象之间的关系;Relationship Detection (Relationship Det):网络同时预测对象的位置(边框)、类别及对象之间的关系。两者均采用作为评测指标,表示计算前个预测中真实正预测占注释关系总数的比例,实验中为与每个对象关联的谓词的数量。
消融实验:
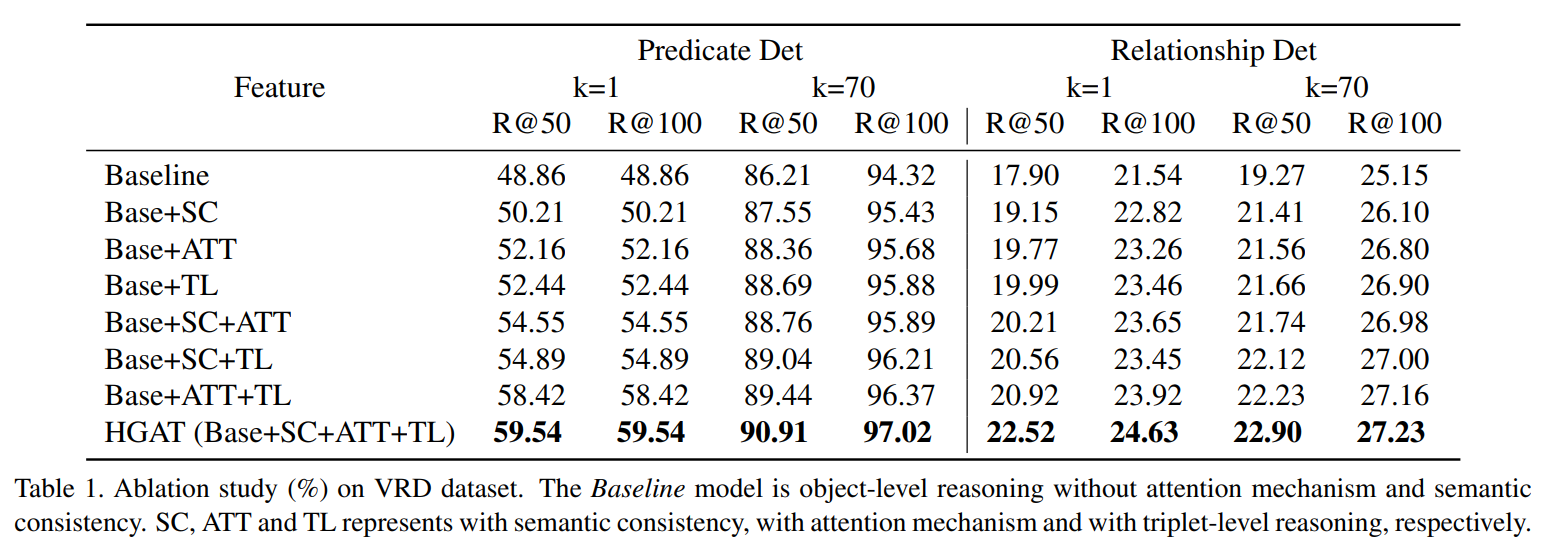
在VRD数据集上的定量实验:
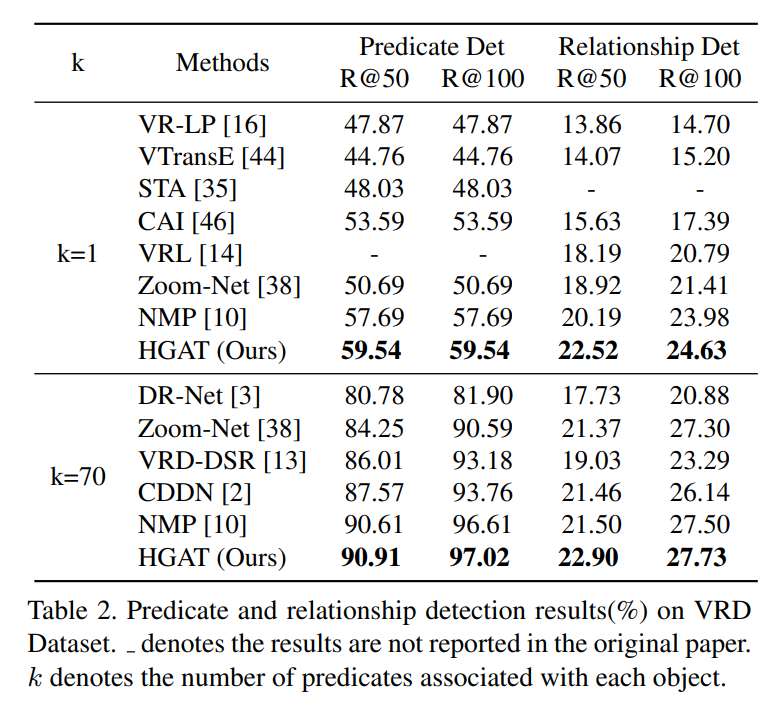
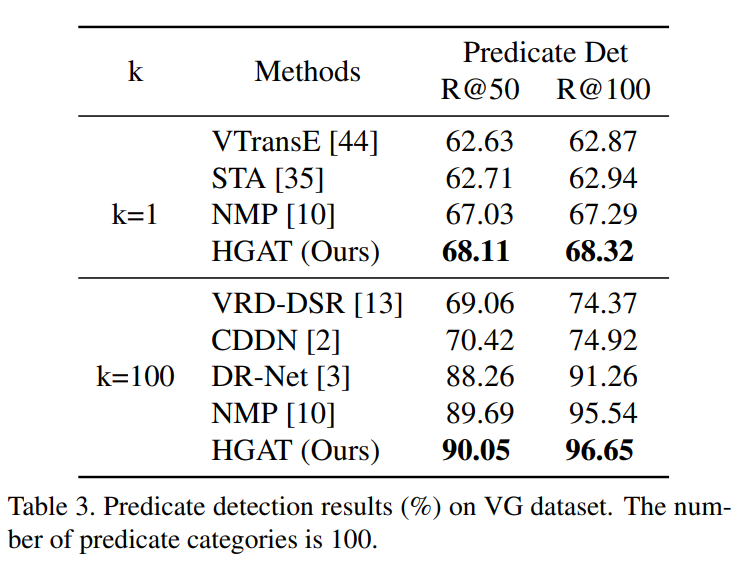
在VG数据集上的定量实验:
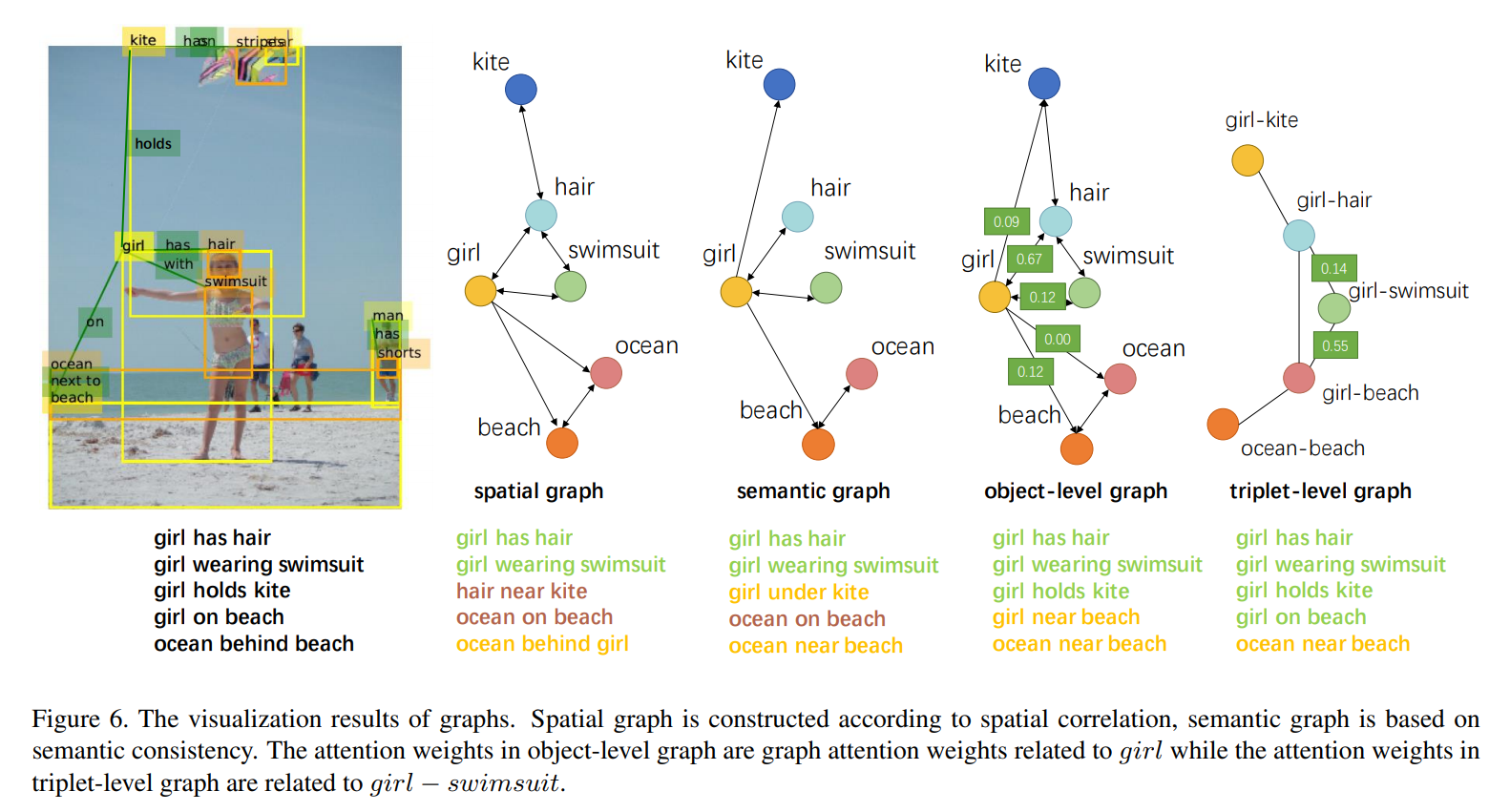
定性结果,绿色、黄色和红色分别表示正确的三元组、正确但没有注释的三元组和错误的三元组: