
动机
- 图像和句子匹配的关键是准确地度量图像和句子之间的视觉-语义相似度;
- 然而,现有的方法大多仅利用各模态内部的模内关系或图像的区域与句子中的单词词之间的模间关系来进行跨模态匹配任务。而各模态内部的模内关系以及图像的区域与句子中的单词之间的模间关系可以相互补充和增强,实现图像与句子的匹配。
贡献
- 在统一深度模型中联合建模图像区域和句子单词的模内关系和模间关系,提出了一种用于图像和句子匹配的多模态交叉注意力(MMCA)网络;
- 提出了一个新颖的交叉注意力模块,它不仅能够利用每个模态的模内关系,而且能够利用模间的关系去互补和增强图像与句子的匹配关系。
本文的方法
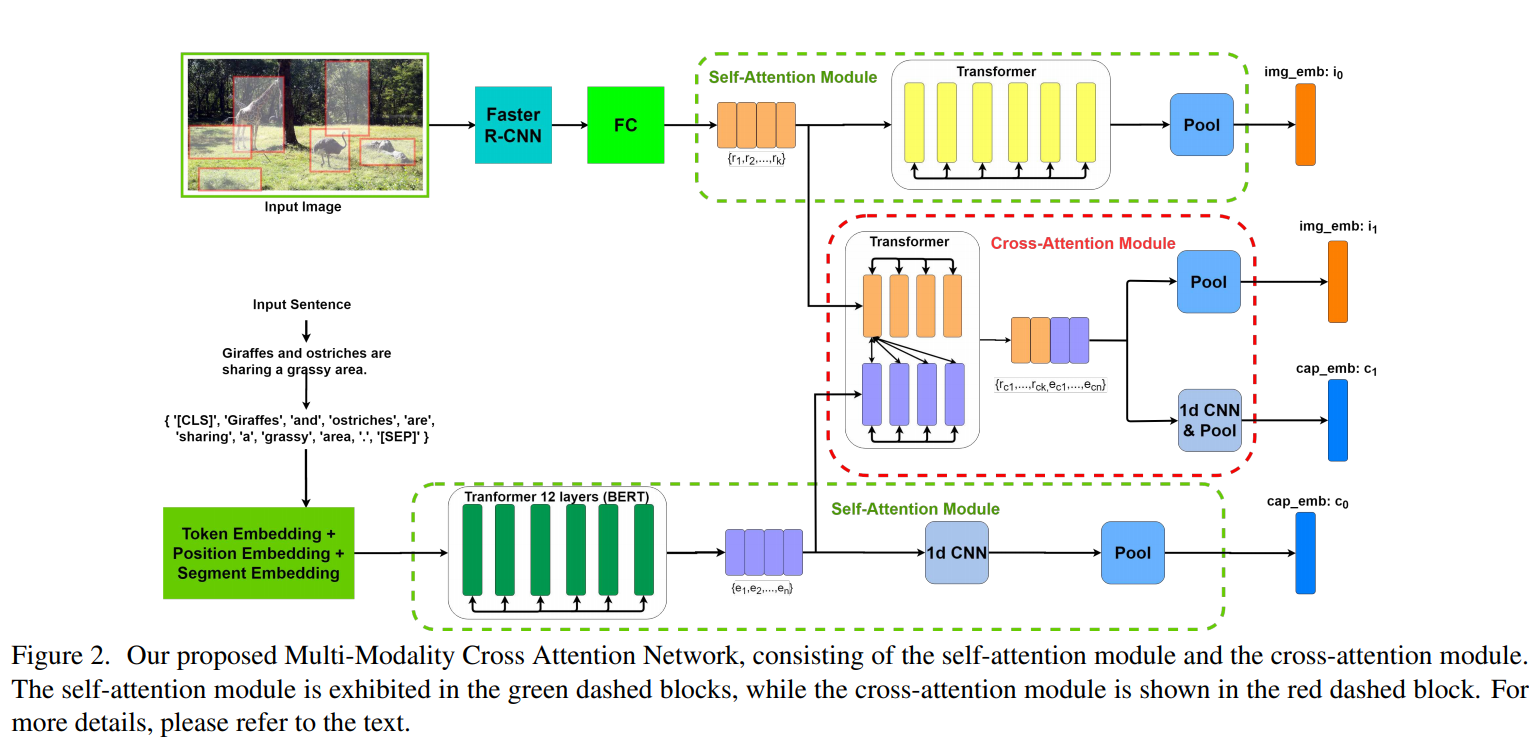
如上图所示,文章提出的多模态交叉注意力网络主要由两个模块组成,即自注意力模块和交叉注意力模块。对于输入的图像和句子对,将图像输入到Visual Genome预训练好的网络中去提取图像区域,同时将每个句子的Word-Piece tokens作为句子的语义片段。在提取出的图像区域表征和句子单词表征的基础上,利用自注意力模块对模内关系建模,并采用交叉注意力模块对图像区域和句子单词间的模间关系和模内关系建模,同时考虑模内和模间关系,可以提高图像和句子片段的特征识别能力。然后对这些片段表征进行聚合,得到给定的图像-句子对的两对嵌入向量和,用于图像和句子的匹配。
候选实例提取
图像候选实例:
对于图像,使用Visual Genome预训练好的自底向上的注意力模型去提取图像区域特征,输出是一组区域特征,表示第个区域的卷积特征的平均池化,再经过一个全连接层得到变换后的特征。
句子候选实例:
对于句子,使用句子的Word-Piece tokens作为句子的语义片段,最终每个单词的嵌入向量是其标记嵌入、位置嵌入和片段嵌入的组合,记为。
自注意力模块
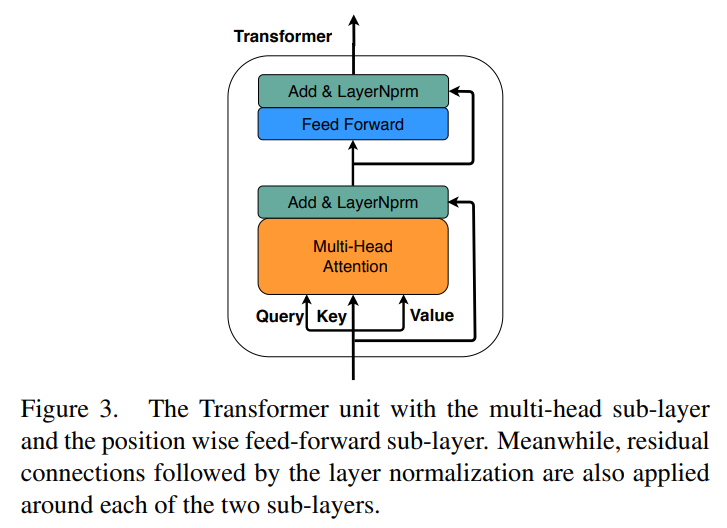
自注意力模块可以有效地开发模内的关系。注意力模块可以描述为将一个查询和一组键值对映射到输出,注意力函数的输出是该值的加权和,其中通过查询及其对应的键确定权重矩阵。特别地,对于自注意机制,查询、键和值是相等的。
在多头自注意力子层中,注意力被计算次,这是通过使用不同的可学习的线性投影将查询()、键()和值()投影次来实现的。具体而言,对于给定的片段集合,其中,表示图像区域或句子词的叠加特征,首先计算输入的查询、键和值:,,,其中,,,,表示第个抽头,然后可以得到权重矩阵,并通过下式计算其加权和:
之后,计算所有抽头的值,并将它们连接在一起:
其中,是抽头数。
为了进一步调整片段表示,前馈子层用两个全连接层分别对每个片段进行相同的变换,并且后跟Add & LayerNorm及residual connections。
通过上述自注意力单元,图像中的每个区域或者句子的单词都可以注意到同一模态下其它片段的特征。对于图像,其细粒度的表征经过上述Transformer单元得到包含区域间关系的特征,接下来通过一个平均池化来聚合图像区域的表征,最终得到图像的全局表征,由于聚合了的片段特征,故表征包含了模内的关系:
对于文本数据,提供标记将句子转换为预先训练好的Bert模型,其输出也包含了内部模态信息,然后利用卷积神经网络提取局部上下文信息,并使用三种窗口大小(单格、双格、三格)来捕获短语级信息,对于第个单词,使用窗口大小为的卷积输出:
接下来,跨所有单词位置执行最大池化操作:,再将连接并经过全连接层得到最后的句子嵌入向量,包含了文本数据的模内关系:
交叉注意力模块
使用交叉关注力模块在统一模型中建模模间和模内关系。交叉注意力模块取图像区域和句子单词为输入,然后Y被传递到另一个Transformer单元,其中片段的查询、键和值由以下方程式组成:
则注意力为:
为了使推导简单易懂,在上面的方程中去掉了softmax和缩放函数,得到下面的式子:
已知,则视觉和文本片段的特征更新为:
该结果表明,该Transformer单元的多头子层的输出同步考虑了模间和模内的关系。然后送入前馈子层,最终得到Transformer单元在交叉注意力模块的输出。
为了得到整个图像和句子的最终表征,将拆分为和,分别经过平均池化和卷积层加最大池化,得到最终的图像和句子嵌入向量和。
损失函数
由此对于给定的图像-句子对,将学到两对嵌入向量和,由此计算图像和句子的相似度,,其中是一个平衡参数。
然后,模型使用bi-directional triplet ranking loss进行训练,使匹配的图像和句子的相似度分数大于不匹配的图像和句子的相似度分数:
其中,是边界值,代表真实匹配的图像-句子对,表示mini-batch中的硬负样本,例如。
部分实验结果
数据集:,,其中每一张图像对应五个句子。
评测指标:,表示在前个结果中被检索到的ground truth的百分比。
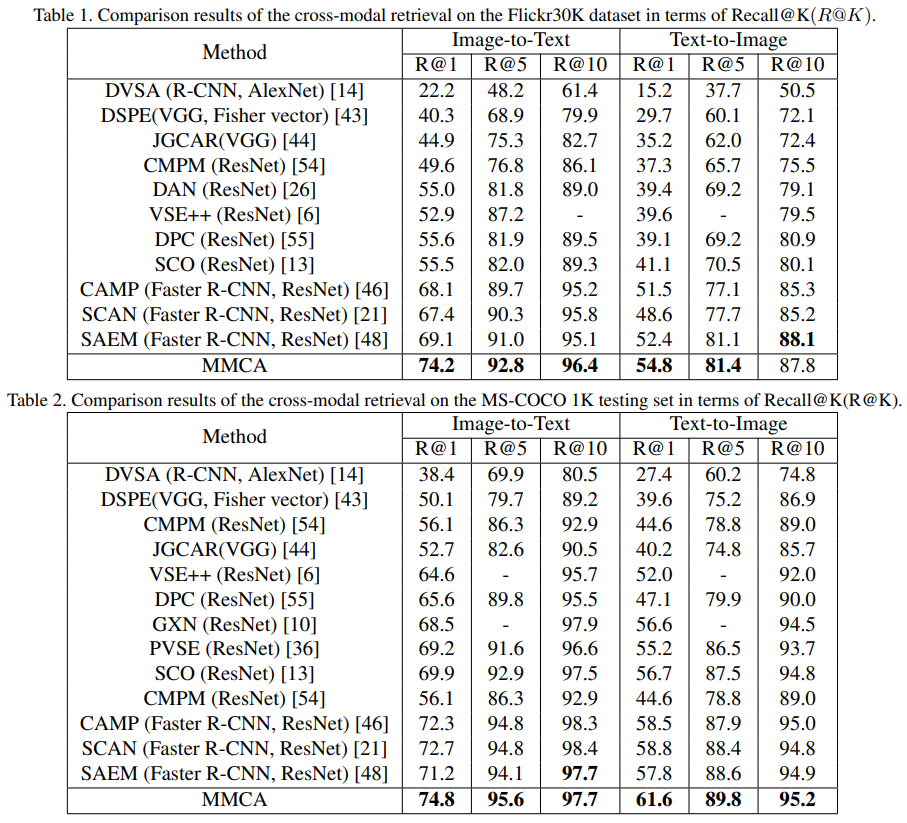
在两个数据集上的定量结果:
上图像到句子的查询结果,显示前5个检索句子。绿色的句子是正确的匹配,黑色的描述是错误的匹配:

上句子到图像的查询结果,显示前四位的检索图像。绿色框中的图像是真实匹配的,而红色框中的图像是虚假匹配的:
