
动机
- 图像-文本匹配连接了视觉和语言,其关键的挑战在于如何学习图像和文本之间的对应关系;
- 现有的工作基于对象共现统计学习粗对应关系,而没有学习细粒度的短语对应关系。
贡献
- 提出了一种图结构匹配网络(GSMN),该网络明确地构造图像和文本图结构,并通过学习细粒度的短语对应进行匹配,是第一个在异构的视觉图和文本图上执行图像文本匹配的框架;
- 第一个利用图卷积层传播节点对应关系,并利用它来推断细粒度的短语对应关系的工作。
以前的方法
图像-文本匹配的关键问题在于学习图像和文本的对应关系,以便准确地反映图像-文本对的相似性。
学习全局对应关系:
将整个图像和文本映射到一个共同的潜在空间中,在这个空间中对应的图像和文本可以统一成相似的表示,不同方法主要是设计特定网络或添加约束条件等。
学习局部区域-单词对应关系:
学习显著区域与关键词之间的局部对应关系来推断图像-文本对的全局相似度。
但是现有的工作只学习基于对象共现统计的粗对应,没有学习结构化对象、关系和属性的细粒度对应。结果造成了两方面的限制:(1)由于对象之间的联系过多,很难掌握关系和属性之间的对应关系。(2)没有描述关系和属性的指导,容易导致对象对应错误的类别。如下所示,粗糙的对应会错误地将单词“dog”与图像中所有的狗联系在一起,而忽略了狗的细节,即棕色或灰色。
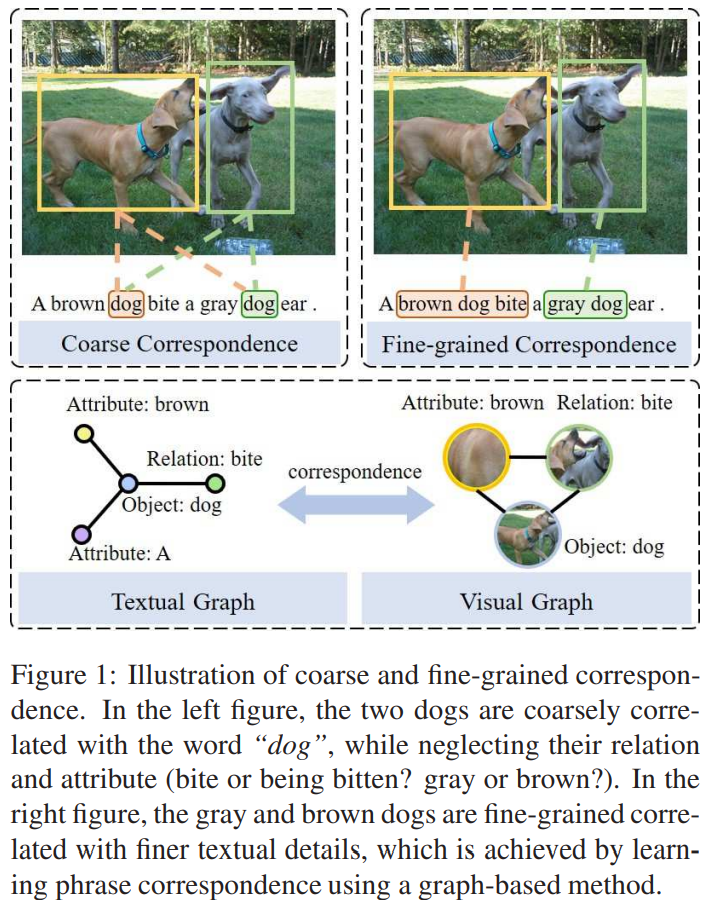
本文的方法
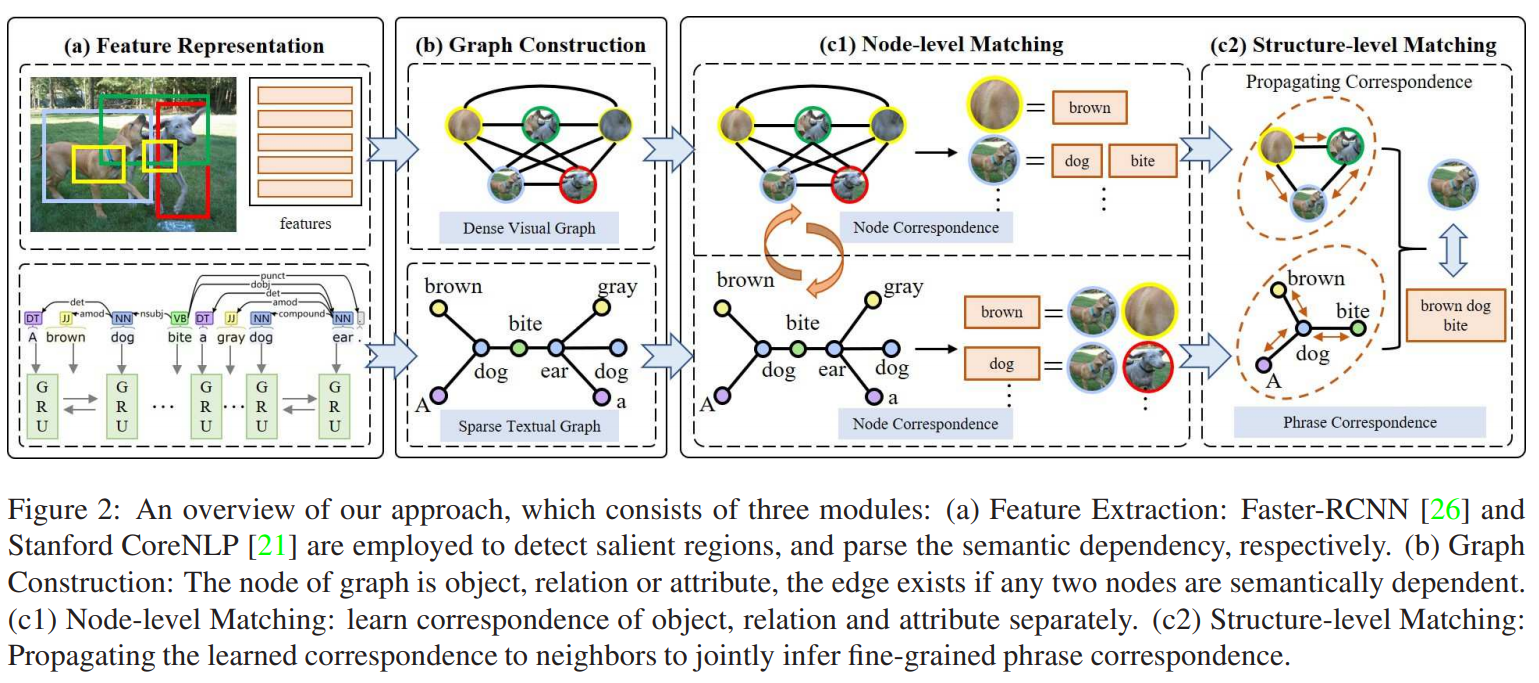
网络框架如上图所示,主要由三个模块组成:(1)特征提取:使用Faster-RCNN和Stanford CoreNLP分别检测显著区域和解析语义依赖性得到图像特征和文本特征;(2)图的构造:图的节点是对象,关系或属性,如果任意两个节点在语义上是相关的,则边存在,由此构建视觉图和文本图;(3)图的匹配:节点级匹配分别学习对象、关系和属性的对应关系,并在结构级匹配时将学到的对应关系传播到相邻节点,以共同推断出细粒度的短语对应关系。
图结构
文本图:
为每个文本建立一个无向稀疏图,使用矩阵表示每个节点的邻接矩阵,为边的权值矩阵,表示节点之间的语义依赖性。
为了构造文本图,文章使用Stanford CoreNLP确定文本中的语义依赖关系。它不仅可以解析句子中的宾语(名词)、关系(动词)和属性(形容词或量词),还可以解析它们的语义依赖关系。即将每个单词看作图节点,如果它们之间存在语义依赖则存在边,使用来表示单词表征的相似矩阵:
其中表示第个和第个节点的相似性,是一个比例因子,边的权值矩阵为相似矩阵和邻接矩阵的Hadamard积,如。
视觉图:
建立一个无向全连通图,其中节点为Faster-RCNN检测到的显著区域,每个节点跟其它所有节点关联,且使用极坐标建模每张图像的空间关系,从而消除了成对区域的方向和距离,这可以捕获不同区域之间的语义关系和空间关系。例如,“on”和“under”的关系显示了与物体“desk”相反的相对位置。为了得到全连通图的边的权值,文章以成对区域的边界框的中心为基础计算极坐标,并将边界权值矩阵设置为成对的极坐标。
多通道图像匹配
给定文本的文本图,图像的视觉图,目标是匹配两个图以学习细粒度对应关系,得到相似度作为图像-文本对的全局相似度。定义文本图的节点表征为,视觉图的节点表征为。其中,m和n为文本图和视觉图的节点数,d为表征的维数。为了计算这些异构图的相似度,首先执行节点级匹配,以将每个节点与另一个模态图中的节点相关联,即学习节点对应关系,然后通过将关联节点传播到邻居来执行结构级匹配即学习短语对应关系,从而共同推断出结构化对象,关系和属性的细粒度对应关系。
节点级匹配:
文本图和视觉图中的每一个节点会匹配另一个模态图中的节点,以学习节点对应关系。
首先计算视觉节点和文本节点的相似度,定义为之后再沿着视觉轴计算函数,相似性度量视觉节点与每个文本节点的对应关系。然后,将所有的视觉节点聚合为其特征向量的加权组合,其中的权重是计算出的相似度:
其中, 是一个聚焦于匹配节点的缩放因子。与以前的方法相比,作者提出了一个多块的模块,该模块计算文本节点和聚合的视觉节点的块相似度,这允许不同的块在匹配中扮演不同的角色。具体而言,将文本节点的第个特征及其对应的聚合的视觉节点划分为个块,分别表示为和。多块相似度是在成对块中计算的,例如,计算第个块的相似度为。其中为标量值,为余弦相似度。将所有文本块的相似度拼接,得到第个文本节点的匹配向量,即
其中表示连接,通过这种方式,每个文本节点都与其匹配的视觉节点相关联。同理,当给定一个视觉图时,在每个视觉节点上进行节点级匹配,相应的文本节点将以不同的形式相连:
然后由多块模块对每个视觉节点及其关联的文本节点进行处理,生成匹配向量。
结构级匹配:
结构级匹配将节点级匹配向量作为输入,并将这些向量与图的边一起传播到相邻的节点。
这样的设计有利于学习细粒度的短语对应,作为相邻节点的指导。例如,一个句子”一只棕色的狗咬了一只灰色的狗的耳朵”,第一个”狗”会在一个更细的层次上对应视觉上的棕色狗,因为它的邻居“咬”和“棕色”指的是棕色的狗。具体来说,通过使用GCN对邻域匹配向量进行积分来更新每个节点的匹配向量。GCN层将应用K个核去学习如何集合邻域匹配向量,公式为
其中表示第个节点的邻域,表示边的权值,和是第个核需要学习的参数。应用了个内核,空间卷积的输出被定义为对个内核的输出的串联,从而产生反映连接节点对应关系的卷积矢量,这些节点形成了局部短语。
通过传播相邻节点对应关系,可以推断出短语对应关系,并以此推断出图像-文本对的整体匹配得分。文章将卷积后的向量输入到一个多层感知器中,共同考虑所有短语的学习对应关系,并推断出全局匹配分数,它表示一个结构图与另一个结构图的匹配程度,这个过程被表述为:
其中为,图像-文本对的整体匹配得分为两个方向上的匹配得分之和:
目标函数:
采用三元组损失作为目标函数,当使用文本作为查询时,在每个小批中对其匹配的图像和不匹配的图像进行采样,形成正对和负对,正配对中的相似度应该比负配对中的相似度高一个阈值。同理,当使用图像作为查询时,负样本应为与给定查询不匹配的文本,其与正对的相似度也应满足上述约束条件。文章主要优化产生最大损失的硬负样本,为:
其中是硬负样本,等价于,是计算的图像-文本对的全局相似度。
部分实验结果
数据集:,,其中每一张图像对应五个句子。
评测指标:,表示在前个结果中被检索到的ground truth的百分比;总的匹配分数
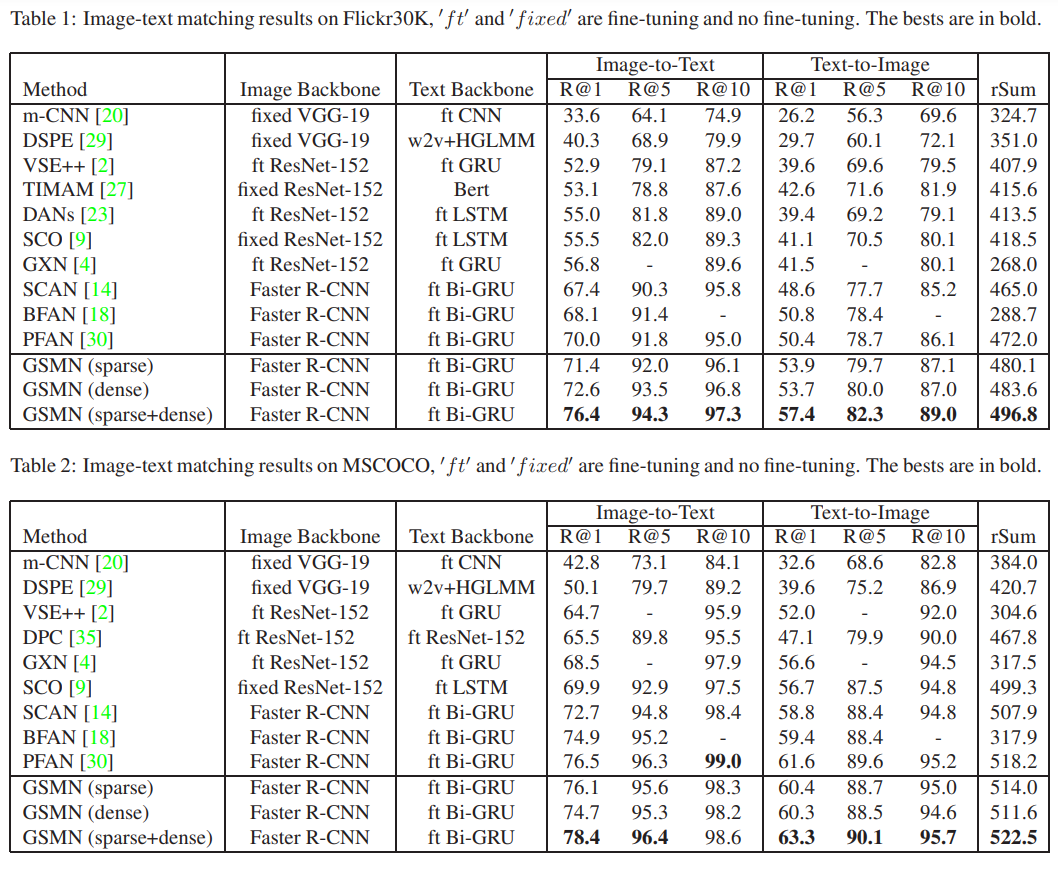
在,数据集上的定量结果:
在框中显示具有分数的节点对应关系和短语对应关系:

上的文本到图像匹配可视化,对于每个文本查询,显示排在前3位的图像,其中不匹配的图像带有红框,匹配的图像带有绿框:

上的图像到文本匹配可视化,对于每个图像查询,显示排名前5的文本,其中不匹配的被标记为红色:
