动机
- 虽然解纠缠对下游任务的学习表示受到了质疑,但解纠缠对于人类可控数据生成、模型可解释性等等仍具有重要的意义;
- 现有的
VAE方法需要平衡解纠缠能力和生成能力,且学习到的潜在表示的边际分布使得优化过程隐式且复杂; GAN的生成能力更强,但目前对于GAN在无监督解纠缠任务中关注较少。
贡献
- 提出了一种基于
GAN的基于one-hot采样和正交正则化的解纠缠框架。该框架提出一个交替的one-hot采样,通过将一个one-hot向量作为潜在表示来强制排他性,并鼓励每个维度捕获不同的语义特征,同时不牺牲潜在空间的连续性,并对模型权重采用正交正则化来更好的实现解纠缠的目的; - 发现了InfoGAN和类似结构的相关模型的一个弱点,文章将其归纳为竞争和冲突问题,并提出了一个模型结构的改变来解决它,此外,针对模型中生成部分的解纠缠问题,提出了一个新的度量方法。
本文的方法
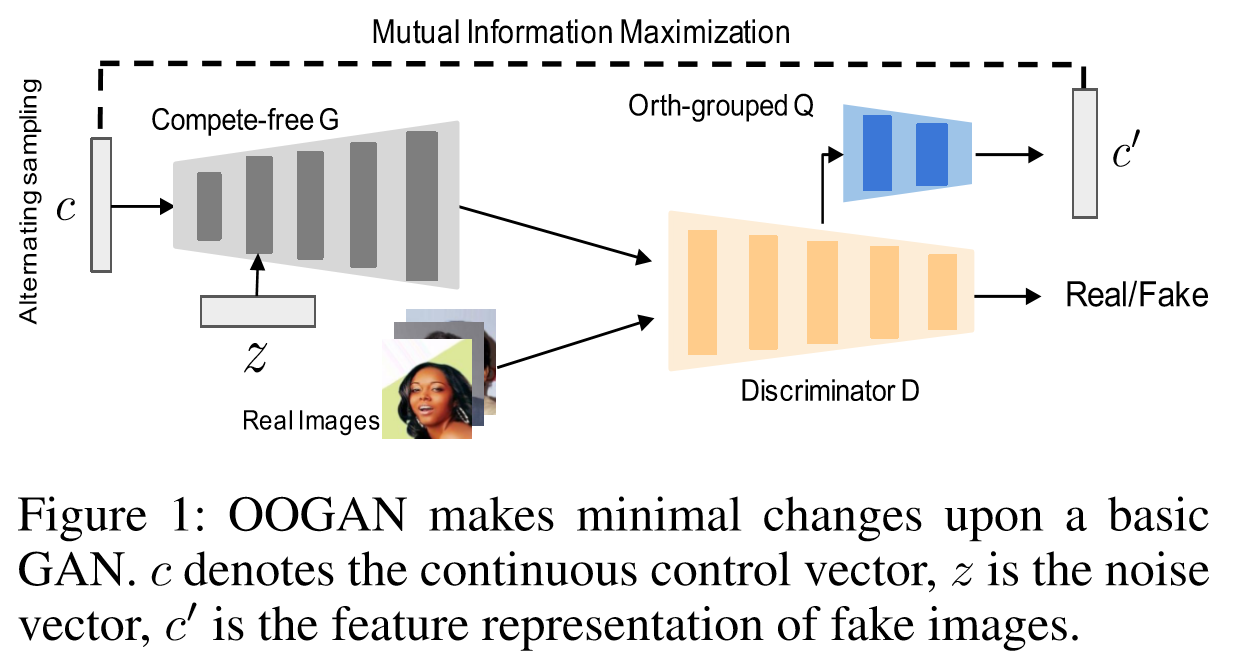
文章对解纠缠问题的定义:对于连续控制向量,希望能够对于的每个维度分别控制一个生成数据的特征,同时希望特征提取器能够对于给定的提取出与一样的特征表示。框架图如下:
交替连续和one-hot取样
通过最小化TC的方法通常有两个限制,首先由于难以计算,必须调用额外的网络或者目标函数来近似TC,这将导致额外的超参数调优,更复杂的训练机制和高额的计算开销,其次为了优化TC,会牺牲一部分数据生成的质量。而GAN通过对潜在向量直接采样,可以人为地采样具有多维间独立性地潜在向量,然后使用这些向量训练网络。
文章提出的交替连续离散采样过程:从均匀采样的连续变量和one-hot向量之间交替采样,one-hot向量意味着生成的图像应该只显示一个特征,并且理想情况下的预测应该也是one-hot向量,在和上,任何其它特征的存在都应该受到惩罚,而连续变量则为了保证GAN网络的潜在空间的连续性。
在训练过程中,将视为一个连续向量,而交替的one-hot向量采样可以看作是和的正则化器,当从均匀分布采样时,需要保证和之间的相关性保持不变,而采样one-hot变量时,可以解释为得到模型的极端样本(即位于均匀分布边界上的样本),突出了边界因素的语义,在这个过程中,训练生成具有指定特征且不保留任何其他特征的图像,而训练只在一个维度上捕获突出的特征,不将特征表示扩展到多个维度。
即交替的one-hot采样和均匀采样的结果是一个更理想的优先分布,它提供了比单一均匀分布更典型的边缘样本。这种交替过程将分类采样(即单热采样)注入连续的中,使得在获得对生成过程的连续控制的同时,更加关注那些典型的例子,从而达到更好的解纠缠,所以本文的损失函数为:
自由竞争的生成器
InfoGAN和许多条件GAN变体利用了一个辅助向量c,该向量在被输入G之前与噪声z连接,期望c携带可控的信息,但的维度通常比大很多,即在生成过程中影响小很多,而对于无监督的解纠缠学习时,在生成过程中接受的很大一部分影响是不希望的,文章称其为竞争和冲突问题。
并且在学习的解纠缠的同时,也可能导致纠缠,例如在某个特征上解纠缠,但的多个维度具有相同的特征,则纠缠的的信号的功率将超过解纠缠的,这会阻碍已学习到的特性,导致它偏离到一些更容易实现但不太明显的特征。竞争与冲突问题示例如下:

为了避免这种问题,文章提出了一种新的生成器输入架构:即使维度较低,但使得控制基本的内容生成而对生成过程只产生有限的影响,输入模块为下图右边:
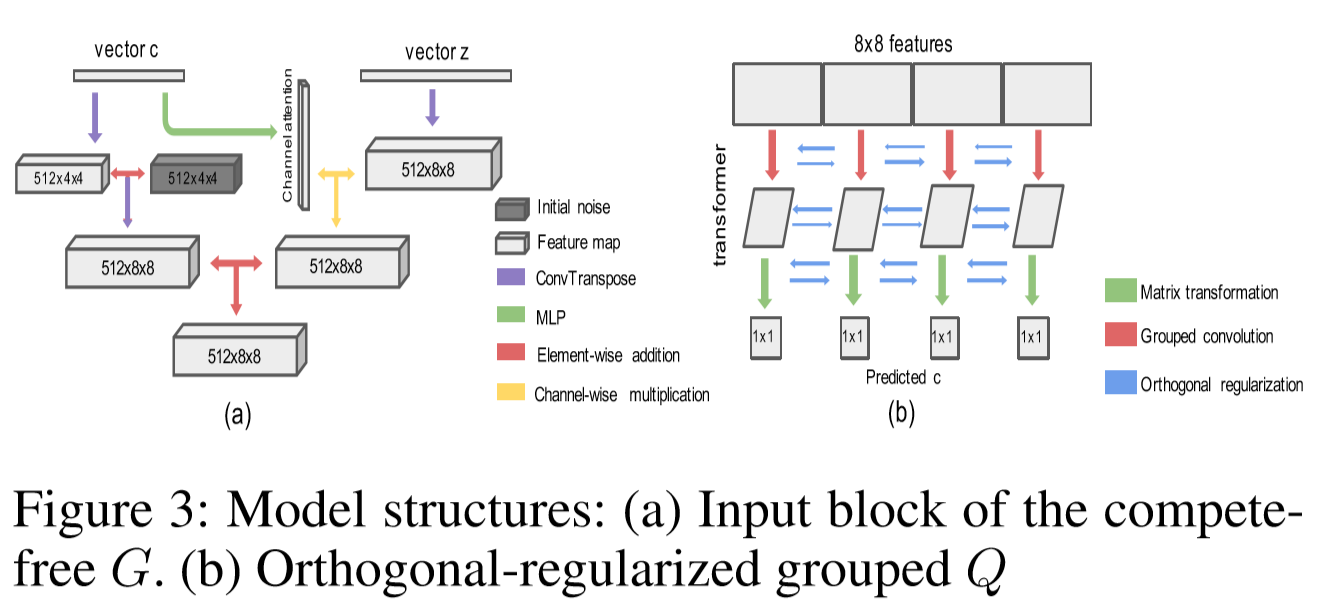
首先将低维的控制向量投影到一个多通道的特征图,并将这个特征图加入到一个学习的同维常数张量中,常数张量的权重在训练前被随机初始化,并在所有生成中使用,这些权重是通过反向传播训练更新的。学到的常数张量可以认为是对数据集添加的偏置,用来表示特征没有捕捉到,理想情况下,当给定的为0时,这个常数应该让生成器生成最“中性”的,直观上可以将这个常数认为是在目标分布中心的一个锚点,所有的潜在因子都可以向不同方向扩展,它鼓励模型专注于学习和生成图像之间的关联。如果没有这个“常数”,模型仍然可以正常工作,但是收敛速度会变慢。同时为了更高质量的生成,传统的噪声仍被输入生成器,但为了防止竞争和冲突问题,对的特征图使用生成的注意力掩码,即希望只有经过批准的的部分才能加入生成过程,并且只映射到大小的特征。
文章的生成器设计类似于StyleGAN,即输入均不是使用输入向量,而是使用固定的多维特征图。StyleGAN认为这样能够更好地分离数据属性,并沿着潜在因子进行更线性的插值,但StyleGAN在固定权重仅用于图像生成过程,而文章则作为一种支持性偏置,将被改变。
正交正则化和分组特征提取器
为了学习解纠缠表示,文章提出了一种新的使用分组卷积的,它对每个卷积核的权重施加正交正则化,因为希望是一个完全解纠缠的特征提取器,而普通的卷积则会在每个特征预测时考虑前一层的所有特征图,其次分组卷积可以将决策集中在更小的区间特征上,而不会被无关特征影响。
为了确保每一组关注不同的特征,文章在卷积层的权重上施加了额外的损失函数,以加强不同核之间的正交性,即在每次前向传播时,计算并最小化每个卷积核之间的余弦相似度。通过特征分组提取和正交正则化,在结构上更容易捕获各个维度的多样化特征。
感知多样性指标
如果生成模型能够解纠缠,则空间向量的每个维度应该产生不同的特征变化的生成图像,假设的一个合适的范围为,和数据,其中是均匀采样向量,是随机选择的索引,通过设置得到,得到,考虑到和是控制不同的因子,则期望和是不同的,因此使用预训练的模型提取和的特征,并将它们的距离作为解纠缠的分数,当距离越高,表示维度和越独立。
不足之处:
感知多样性度量通常不应该用于比较不同结构的模型,也不能单独捕获模型的解纠缠能力。首先,的距离不是一个绝对的度量,例如VAE模型A产生模糊的图像,这可能导致该度量的较低值,与GAN模型B相比,后者的图像是清晰和高对比度的,但这并不一定意味着A解纠缠比B差。
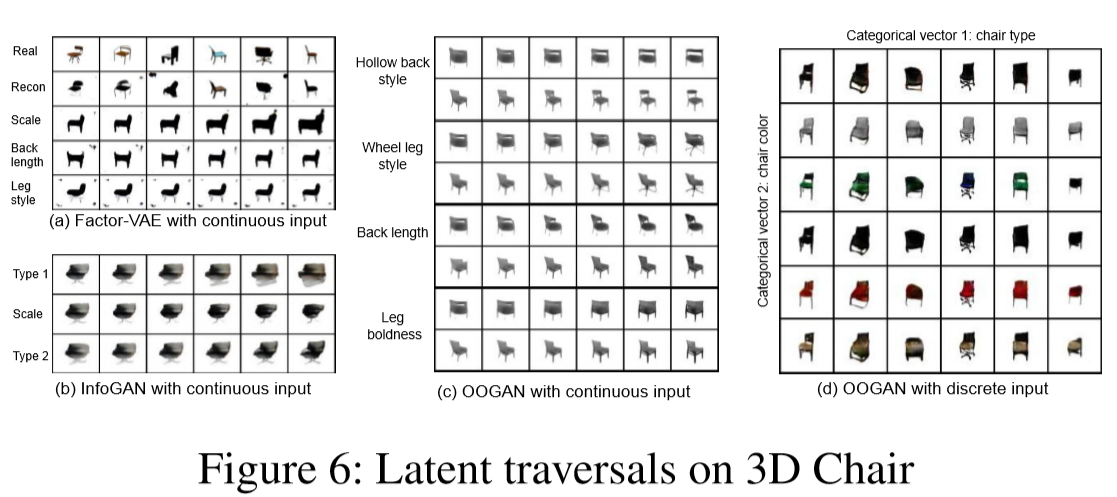
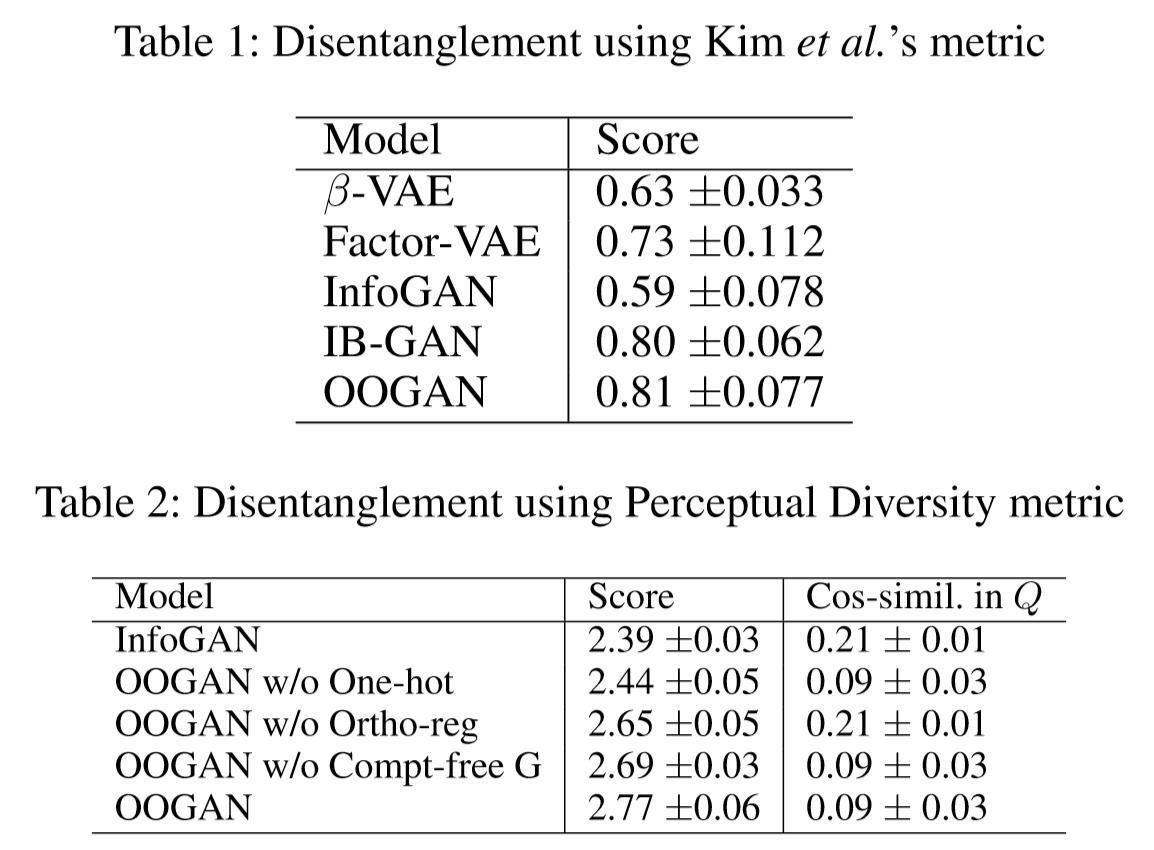
部分实验结果