动机
当图像的变化因子被解纠缠,它的表征可以被用来开发各种计算机视觉任务,在图像级别可以实现属性的转移,在特征层可以用来做图像检索或者分类;
之前的解纠缠方法,如autoencoder,GAN相关的一些方法,通常使用手动注释,来自训练数据的标签信息或者外部模型的指导;
- 对于无监督的方法,如
InfoGAN不包含编码阶段,不能将输入图像恢复为解纠缠的表征,更不能进行属性交换与融合;对于beta-VAE,DIP-VAE则建立在VAE的基础上,通过KL散度约束变化因子前后分布之间的相似性,同时特征块是一维的。
贡献
- 提出一种完全无监督的方法(不使用任何注释或数据域的知识)来学习由变化的解纠缠因子组成的图像表征,它将特征向量分割成多个块,每个块代表一个变化因子,使得用户可以指定特征块去混合和分离图像属性;
- 提出了一种新的不变性损失函数来鼓励对图像属性和特征块分别进行不变性编码和译码;提出了一种新的分类约束函数,确保每个特征块的表示的是被表示图像一致的且可识别的变化因子;
- 在
MNIST、Sprites和CelebA数据集上证明了本文方法的有效性。
本文的方法
本文方法的基本假设是图像可以由一组变化因子来表示,每一个变化因子对应一个语义上有意义的图像属性。此外,每个变异因子都可以使用其自身的特征向量进行编码,称之为特征块。也就是说,图像被简单地表示为有一定顺序的特征块的串联。
网络结构
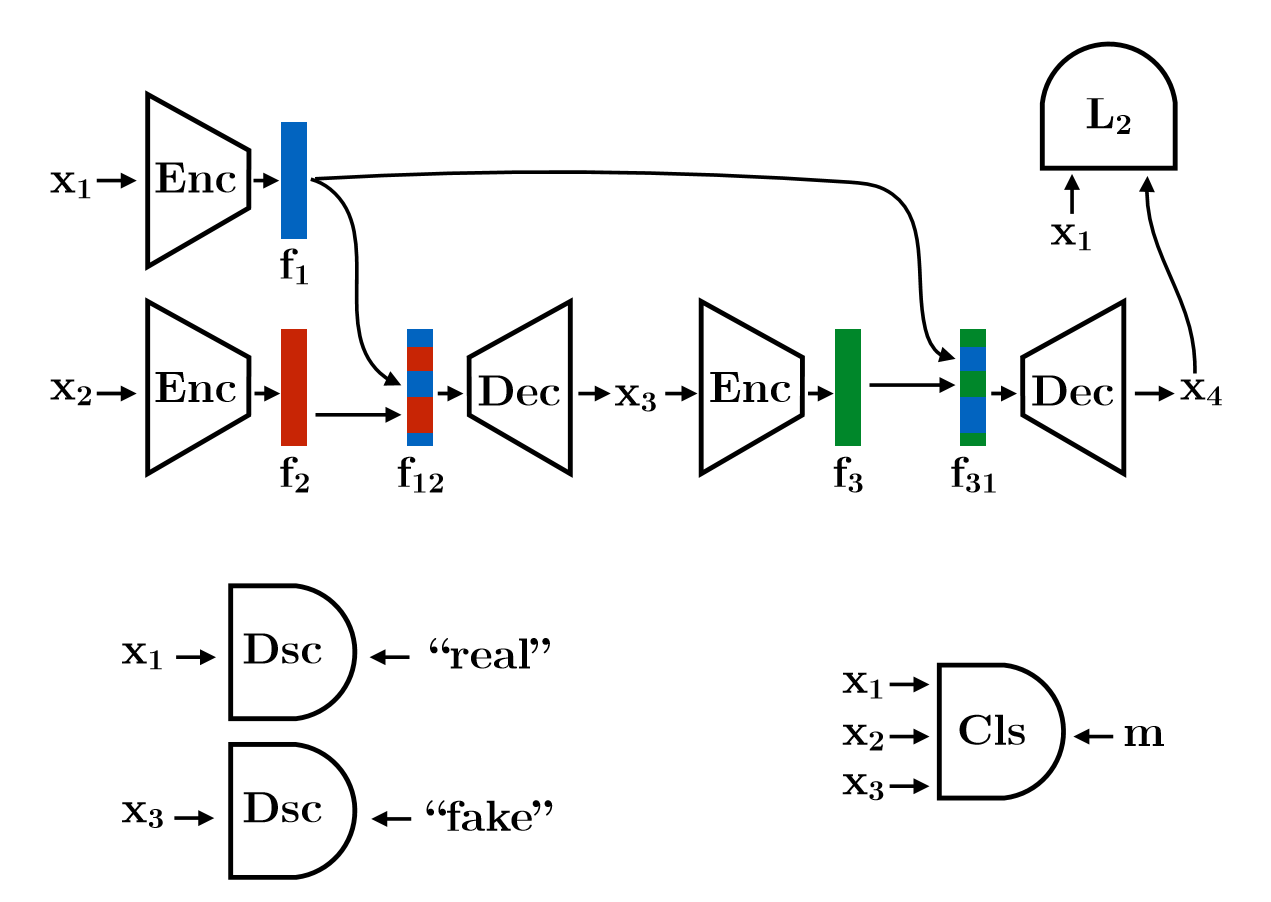
模型主要包含三部分:两个混合自编码器序列和一个判别器增强不变性,一个分类器避免shortcut问题。
Mixing/Unmixing Autoencoders
文章利用两个混合的自动编码器序列来加强不变性,确保将每个属性编码成一个特征块,不因其他属性的变化而改变,并以类似的不变性方式将每个块解码成其属性。它的工作流程如下:
- 独立的采样两个样本和,并分别编码和;
- 混合:定义一个
mask为,其中从采样,,如果则从否则从选择第个特征块,由此得到新的特征,其中;
- 译码得到新的图片;
- 再次编码得到;
- 解混合:通过给定的
mask为来替换中来自的特征块,并和对应的来自的部分得到;
- 译码得到最后的图像。
该部分的损失函数为对所有可能的mask设置进行求和(在训练期间,是随机采样掩码m)计算最小化和的距离:
这里的关键思想是混合特征向量的译码和编码应该保留的特征块,即来自的特征块应该被解码成对应的属性,并将混合了和属性的中间图像重新编码成时,应该返回同相同的特征块。
Discriminator
为了保证所生成的图像是根据输入数据分布的有效图像,由此增加了一个对抗性项:
在理想情况下,当GAN损失函数达到全局最优时,伪图像的分布应该与真实图像的分布一致,但是在不变性和对抗损失的基础下,可能存在将所有图像属性编码成一个特征块,并保持其余的不变,而此时不变性损失和对抗性损失都是完美优化状态。将此问题称为shortcut问题,使用额外的分类损失来解决。
Classifier
分类器的输入为输入图像,和生成图像,分类器判断每个块的生成图像是使用第一个输入图像的特征,还是第二个输入图像的特征生成的:
该分类器由n个二类分类器组成,每个二分类器对应一个特征块,决定生成图像是使用第一幅图像对应的特征块还是使用第二幅图像对应的特征块生成的。只有在每个特征块中编码有意义的属性,分类器的损失才能最小化,因此不会出现shortcut问题,因为存在的话则不可能决定使用哪些特征块来生成图像。
所以,总的损失函数为:
实现方法
使用类似于DCGAN的网络结构作为编码器、解码器和鉴别器,分类器,使用了在每个卷积层后进行批处理规范化的不带dropout的AlexNet。在MNIST和Sprites数据集上,,对于CelebA则;本文将特征向量(即encoder的最后一层)分为8个具有相同大小的特征块,每个特征块代表一个属性,具体特征块的大小为:MNIST为8,Sprites和CelebA为64,观察到减小CelebA的特征块的大小会导致生成质量下降。
部分实验结果
MNIST的实验结果

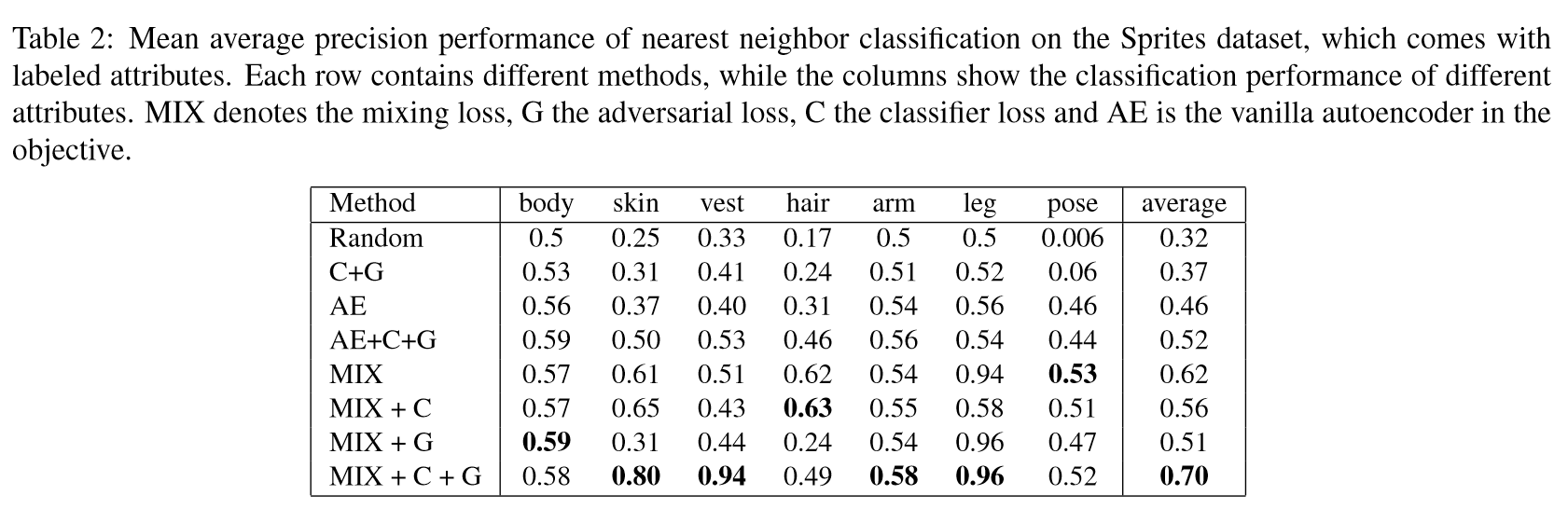
Sprites的实验结果

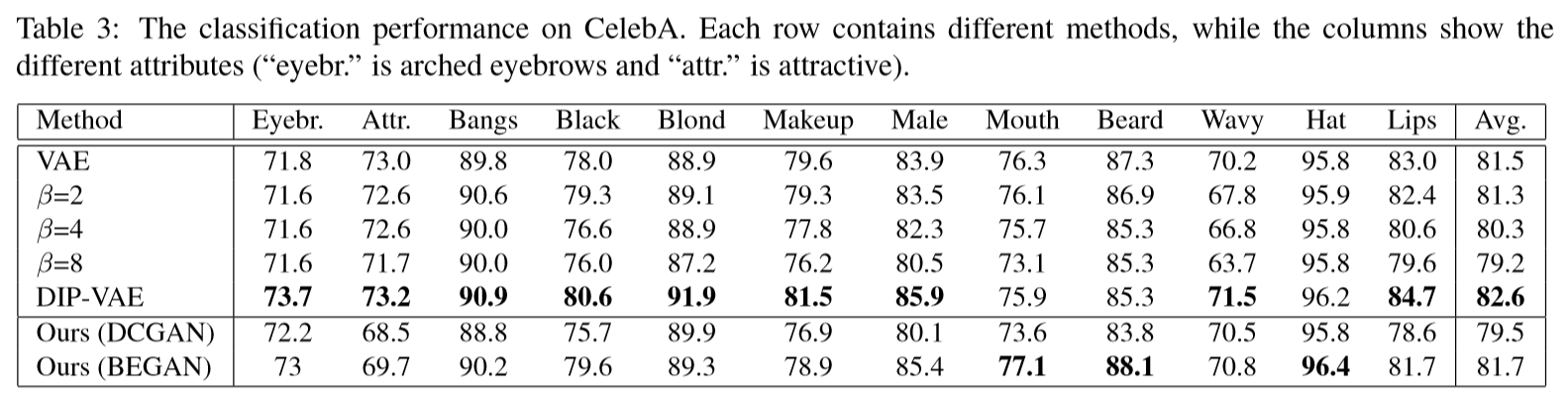
CelebA的实验结果

对于每个子图,从最上面的行提取一个特征块,从最左边的列提取其余的特征块,不同的子图显示了不同特征块的作用,标题显示与该特征块关联的属性。