2020-10-14 update
beta-VAE metric,factor-VAE metric,MIG,SAP Score,DCI2020-12-22 update
Modularity,Locatello论文方法设置
本文是基于Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations的论文和NeurIPS2019 Disentanglement Challenge对连续的解纠缠方法的度量方法,主要对相应的评测方法的原理进行简单讲解,文章分别提到了beta-VAE metric、factor-VAE metric、MIG、SAP Score、DCI、Modularity和IRS。
beta-VAE metric
原文:beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework
方法

将某个变化因子固定而其余的因子随机变化,由此生成对的数据和,再得到对应的表征和(定义为的均值),计算每对和之间差的绝对值,再将这些统计量的平均值作为线性分类器的输入,固定因子为对应的输出,理想状态下如果表征被完全解耦,则在输入的维度上对应的固定的变化因子的维度为0,分类器就会学会将零值的维度索引映射到固定变化因子的索引上。
缺点
- 对线性分类器优化的超参数敏感;
- 使用线性分类器不那么直观,即会得到每个因子对应维数的线性组合而不是单一维数的表示;
- 即使个变化因子中只有个变化因子被解纠缠,依然为的准确率(见
factor_vae)。
Factor-VAE metric
原文:Disentangling by Factorising
方法
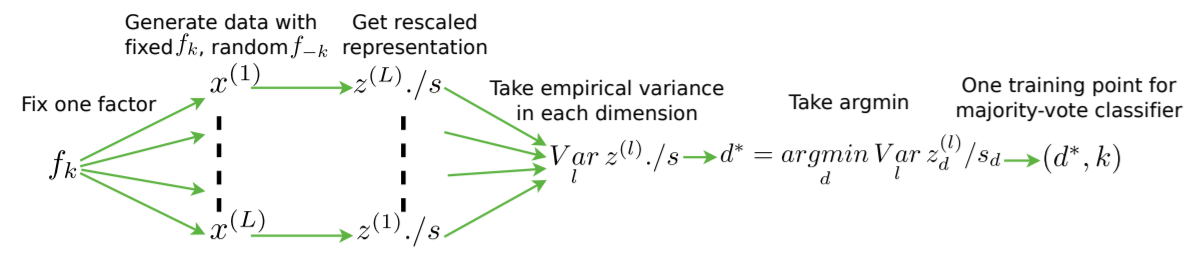
选择某个变化因子,生成该因子固定而其余的因子随机变化的数据,由此得到L个数据,再得到对应的表征,并通过足够大的数据集对的各个维度使用经验标准差进行归一化处理,然后对这些标准化表示在每个维度计算方差,方差最小的那个维度的索引则对应于固定的因子,即分类器的输入和输出。所以理想情况下,如果完全解纠缠,则固定的变化因子对应的维度上的经验方差应该为0,由于输入和输出均位于离散空间,这里分类的方法是使用投票法,无超参数,但依然是有监督的方法。
MIG(Mutual Information Gap)
原文:Isolating Sources of Disentanglement in Variational Autoencoders
方法
假设真实因子和生成过程已知且可被(如经验分布)量化,且对于所有的,是已知的且可以采样的;那么对于任意的,文章认为隐变量和真实因子之间的互信息可以用联合分布表示,则互信息为:
其中是隐变量的熵,是满足的样本集合,期望是通过显式地采样来实现的。
可以看出,更高的互信息表示包含中的更多的信息,即如果和存在确定的互逆关系,则互信息应该最大,对于离散的,有,其中是的熵。虽然可以通过直接计算平均的最大来作为度量方法,即,但这样可能会出现一种情况,即一个因子,可能与多个有很高的互信息,通过计算具有最高的互信息的前两个隐变量之间的差异来强制轴对齐,故使用下式:
其中,是已知的因子的数目,MIG的值为[0,1]的区间,作者认为这种方法的优点就是轴对齐的且无偏的,就是一个潜变量只和一个真实的相关。上式能够防止两种重要的情况:第一种情况与因子的旋转有关,当一组潜在变量不是轴对齐的时候,每个变量可以包含关于两个或更多因子的信息,这个差值会惩罚未对齐的变量;第二种情况与表示的紧密度有关,即如果一个潜在变量可靠地模拟了一个真实的变化因子,那么其他潜在变量也不必关联这个因子了。
SAP(Separated Attribute Predictability) score
原文:Variational Inference of Disentangled Latent Concepts from Unlabeled Observations
方法
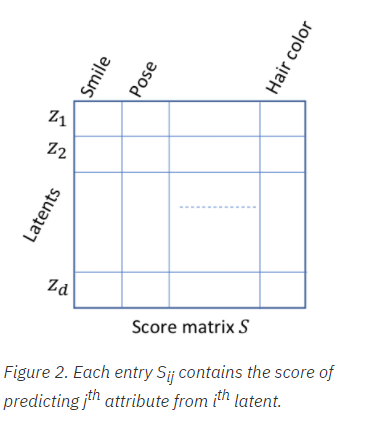
首先创建一个的分数矩阵,其中个潜在因子和个生成因子,第项是仅使用第个潜在因子预测的第个因子的线性回归或者分类得分。对于回归,将其作为通过拟合一条最小化线性回归误差的直线(斜率和截距)得到的分数,值域范围为[0,1],得分为1,则表明第个潜在因子的线性函数解释了第个生成因子的所有变化;对于分类,对平衡分类误差最小的测试示例在第个推断潜在因子上直接拟合一个或多个阈值(实数),并取为第个生成因子的平衡分类精度。对于某些维度有接近0,则取为0。
对于对应一个生成因子的得分矩阵的一列,取前两项的差值(对应前两项最具有预测性的潜在因子的维度)的平均值作为最终的分数,仅仅考虑每个生成因子的最高潜在因子是不够的,因为它不排除该生成因子被其它潜在因子捕获的可能性,高的分数表明每个生成因子主要只被一个潜在因子捕获,但并不排除一个潜在因子捕获多个生成因子,并且多个潜在因子可能与同一个生成因子密切相关,对于这样的模型,使用单个潜在因子遍历生成示例不现实,而得分可以根据相关性对潜在因子维度进行分组,由此得到分组级别的得分矩阵作为第二步的输入,并由此得到最终的分数。
DCI(Disentanglement Completeness and Informativeness)
原文:A Framework for the Quantitative Evaluation of Disentangled Representations
方法
为了实现评测方法,文章使用了以下步骤:
- 通过具有生成因子的数据集训练模型;
- 为数据集的每个样本检索();
- 训练一个回归模型,对于给定的去预测();
- 量化与理想映射的偏差和预测误差。
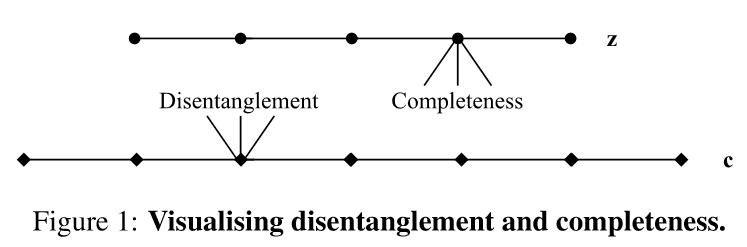
文章考虑了表征的三个属性,即解纠缠性、完整性和信息量。
解纠缠性:用来表示一个表征对变化因子的解纠缠程度,每个变量(或维度)最多捕获一个生成因子。
编码向量的解纠缠分数定义为:
其中表示熵,表示预测为的重要性概率,如果对于预测一个单生成因子很重要,则分数为1,如果对所有生成因子一样重要,则分数为0。
为了计算中dead或者无关的单元,使用相对编码向量重要性来构建一个表示总体解纠缠性的加权平均,如果编码向量跟预测的无关,则趋近于0。
完整性:用来表示单个编码变量捕获每个潜在因子的程度。
捕获生成因子的完整性分数定义为:
其中表示分布的熵,如果一个单编码向量给预测做贡献,则分数为1,如果所有的编码向量都对的预测做贡献,则分数为0。
信息量:用来表示所捕获的变化因子的表征的信息量。
关于生成因子的编码的信息量定义为数据集的平均预测错误,其中是一个合适的误差函数,且,信息量的度量依赖于的能力,也依赖于将表征为的信息的模型的能力,因此信息量度量与解纠缠度量有一定重叠,重叠大小取决于的能力。
Modularity
原文:Learning Deep Disentangled Embeddings with the F-Statistic Loss
对于Modularity,首先计算每个编码维度和每个因子之间的互信息,如果编码维度理想的Modularity,则它与单个因子的互信息很高,与所有其它因子的互信息为0。于是使用与这种理想情况的偏差来计算Modularity的得分,给定单个编码维度和因子,用表示编码和因子的互信息,其中,创建一个与具有相同大小的模板向量,它表示代码维度在理想化情况下的最佳匹配情况:
其中,,所观察到的与模板的偏差为:
其中是因子的个数,偏差0表示实现了完美的Modularity,1则表示该维度与各因子具有相等的互信息。由此使用表示编码维度的modularity score,在上的平均值作为所有编码的modularity score。这个值并没有告知每个因子在编码中是否都得到了很好的表示,为了确定编码的覆盖范围,需要explicitness度量。
假设因子为离散值,可为每个因子的每个取值计算一个explicitness score,在explicitness表示中,应该可以使用简单的分类器从编码中恢复因子的值。文章用一个one-versus-rest的logistic回归作为分类器,将整个编码作为输入,记录该分类器的AUC,使用在因子index和因子的值的index上的平均值作为编码的explicitness score。
IRS(Interventional Robustness Score)
原文:Robustly Disentangled Causal Mechanisms: Validating Deep Representations for Interventional Robustness
Locatello论文的相关评测方法实验设置
原文:Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
BetaVAE metric
Higgins et al.固定一个随机因子的变化,采样两个mini-batch的观测样本,最后测量线性分类器的准确率来衡量解纠缠性能,该线性分类器基于两个mini-batch的表征之间的绝对差的坐标和,预测固定的因子的index。实验时设置batchsize为,两个batch的一个随机因子固定在一个随机采样值,其它变化因子随机。计算这些样本点的平均表征并计算两个batch数据之间的绝对差值,再将这个值平均,形成一个训练(或测试)点的特征,默认使用个样本训练logistic regression,个样本测试。
FactorVAE metric
Kim & Mnih改用多数投票分类器,该分类器基于具有最小方差的表征的index来预测固定的真值因子的index。实验时首先采样个随机样本估计每个潜在维度的方差,并排除方差小于的崩塌维度;其次设置batchsize为,每个batch的一个随机因子被固定为相同的随机值,来生成多数投票分类器的选票;最后计算其潜在表征的每个维度的方差,并除以在无干预情况下计算的数据的方差。多数投票分类器的训练点由归一化方差最小的维度的index组成,训练时采用个样本,测试时采用。
Mutual Information Gap
Chen et al.表明BetaVAE metric和FactorVAE metric依赖于一些超参数,不通用且不是无偏的。通过计算每个真实因子和每个计算表征的维度之间的互信息,对于每个真实因子,考虑中与具有最高和次高的互信息的两个维度。MIG定义为各因子(数量为表征的维数)的最高和次高互信息的平均归一化差值。原始的方法使用采样表征,本文为了跟其它方法保持一致,则使用平均表征。实验将得到的个样本的表征离散化到个bins,由此计算离散的互信息,该指标分数计算如下:
其中,是一个变化因子,是潜在表征的一个维度,。
Modularity
Ridgeway & Mozer表明应该考虑两个不同的属性:Modularity和Explicitness。对于Modularity,的每个维度最多只取决于一个变化因子;对于Explicitness,变化因子的值应该很容易从中预测出来。原文提出用变化因子和的维度的最高互信息和次高互信息的平均归一化平方差来衡量Modularity,使用一个one-versus-rest的logistic回归分类器的ROC-AUC来测量Explicitness。对于modularity score,实验采样个数据点,从中获得潜在表征,再将这些点离散到20个bin中,并计算表征和变化因子值之间的互信息,得到。对于每个表征的维度,计算得到向量:
其中,,modularity score为在表征维度上的平均值:
其中是因子的个数。
DCI Disentanglement
Eastwood & Williams考虑表征的三种属性,即Disentanglement,Completeness和Informativeness。首先计算了学到的表征的每个维度对预测变化因子的重要性,每维的重要性可以用Lasso或者Random Forest分类器计算。Disentanglement是学习表征的一个维度对于预测一个因子有用的概率的熵的平均值,该因子的值是每个维度的相对重要性;Completeness是一个变化因子被一个维度的学习表征捕获的概率的熵的差值的平均值;Informativeness则是预测变化因子的预测误差。实验分别采样个训练样本和个测试样本,对于每个因子,使用gradient boosted trees的Scikit-learn的默认设置。从该模型中提取特征维度的重要性权值,取绝对值构成重要性矩阵,其行对应于因子,列对应于表征。为了计算disentanglement score,首先从这个矩阵的每一列的熵中减去(将列归一化作为一个分布对待),由此得到一个长度等于潜在空间维数的向量,然后再计算每个维度的相对重要性:,最后disentanglement score为。
SAP score
Kumar et al.提出计算线性回归的分数,该线性回归从学习的表征的每个维度预测因子值。对于离散因子,则训练一个分类器。Separated Attribute Predictability score是各因子预测误差最大的两个潜在维度的平均差值。实验采样个数据点训练,使用个样本测试,然后计算一个包含测试加预测误差的分数矩阵,该分数矩阵用于的Linear SVM,其从单个潜在维度去预测因子的值。SAP score则计算最具预测性的两个潜在维度之间的差值的平均值。