
动机
- 对于人工智能来说,学会区分观测数据的不同属性(称为解纠缠)是一项关键任务;
- 作者分析类别和内容表征中包含的信息,表明当前的方法允许信息在表征之间泄漏,从而导致不完美的解纠缠。
贡献
- 提出了一种新的非对抗性方法LORD来实现对象的类和特定样本内容之间的解纠缠,通过共享潜在优化和非对称正则化改进以往方法的缺点;
- 实验证明本文的方法比相同监督条件下的对抗性方法和对抗性方法中取得了最好的解纠缠性能,同时可以基于聚类方法去应用在无监督的域转换的任务中去。
与以前方法比较的优势
- 利用潜在优化来学习每个类的单一表征,这个表征在所有样本之间共享,这种方法是优于平摊技术的;
- 在内容隐编码上引入非对称正则化来实现类不变性表征,这种方法优于对抗约束和KL散度;
- 潜在优化在训练时对于学习解纠缠表示是很有效的,但是对于获取不可见的测试图像的类和内容编码没有什么帮助,如果在测试时进行潜在优化容易导致过拟合而导致纠缠,所以引入第二阶段模型,利用第一阶段模型学到的类和内容编码,去训练一个前馈的类和内容编码器,这个编码器能很好的推广到看不见的图像且减少了新样本的推断时间。
- 实验证明本文提出的方法明显优于其他对抗和非对抗的方法。分离类和内容表征是假设类内变异显著低于类间变异,作者发现可以通过将类内的风格聚类到离散的类中来松弛这种假设,所以在无监督域映射上也有较好的结果。
类与内容的解纠缠
解纠缠任务的目的是为了学习一种表征,使得它包含所有从类别标签中得不到的信息,称为内容,比如人的头部姿态,面部表情等。
假设一组图像,对于每个图像,对应一个标签,假设类别的嵌入为,假设可以将图像解纠缠为两个隐空间的表征,因此解纠缠的目的是对每个图像找到一个类表征和一个内容表征。
类表征需要包含同一个类的所有图像共享的所有信息,比如类对应不同的面不身份,则类表征需要包含所有时不变的面部信息。内容表征应该包含所有图像在类间传输时未更改的信息,这个信息是独立于类信息的,例如面部,内容对应于时变的面部信息,如头部姿势和表情。
除了类和内容表征之外,图像可能还包含其他特定于图像的信息,这些信息不是由类标签表示的,也不期望在类之间传输。内容和风格之间的区别是语义上的,比如面部,风格可能包括噪音、照明条件或背景特征等。
所以可以定义一个生成器将解纠缠的表征转换为一张图片:
其中内容必须跟类别和风格独立,而风格可能依赖于类,即跟和的互信息必须为0:
一般情况下,可以假设类间的差异显著大于类内的差异。许多方法被用来学习这个场景下的解纠缠表示,下文包含图像的类和风格信息。
对抗的方法DrNet
确保内容和类/风格表征之间独立性的一种方法是使用判别器,这种技术不会显式学习类的表征,而是给风格编码施加了一个很强的约束:
使用相似度约束来确保类内中图像风格的相似度,而为了保证和的独立性,则训练一个判别器来判断两幅图像是否来自同一类,如果内容表征完全解纠缠,则内容编码中没有类信息可用且编码器的准确率等同于随机分类。
缺点:只有一个很弱的约束,它不能直接防止内容信息泄漏到风格表征中;对抗方法难以优化。
非对抗的方法ML-VAE
它也不学习类的表征,而是通过平摊推理风格表征,然而,为了限制内容信息从风格编码流动到生成器,它依赖于训练期间的同一类别的小批量样本,在输入生成器之前使用正态分布概率密度的乘积来累积风格编码,即近似观察到的一组同类样本的风格表征,并生成图像:
利用标准正态分布的KL散度来约束内容表征的分布,从而限制内容表征中的信息。
缺点:使用分组平摊编码推断,由于batchsize和多样性的限制,存在偏见且不利于优化;KL散度也并没有充分地约束中地信息,即在中找到了类信息。
本文的方法-表征解纠缠的潜在优化(LORD)
类监督的潜在优化
由假设:类间的变化显著大于类内的变化,这允许将图像建模为类编码和内容编码的组合:
共享的潜在优化-对类嵌入的潜在优化确保了在类表征中不出现任何内容信息
将相同类别下所有图像共享的类表征作为嵌入,本文没有使用平摊推理(即使用一个编码器学习从图像到类编码的映射),而是直接使用潜在优化对类嵌入进行优化。
优点:类编码在同类样本中共享(内容可能不同),所以不能在类编码中包含任何内容信息;且直接学习每个类的表征而不是用分组平均,所以每个batch可以随机采样,多样性更丰富。
同理,使用潜在优化直接对每个样本的内容嵌入进行优化来学习内容表示,而不是使用从图像到内容编码器的平摊方式。
非对称噪声正则化-为了确保类信息不会泄漏到内容表征中
本文使用一个附加的固定方差的高斯噪声和一个激活衰减惩罚来正则化内容编码。与变分自动编码器相比,本文的方法不学习方差,而是保持它固定。这防止了方差减小到一个小值的可能性,确保噪声均匀地应用在所有组件上,目标函数变为:
所有隐编码和生成器的参数采用随机梯度下降进行更新:
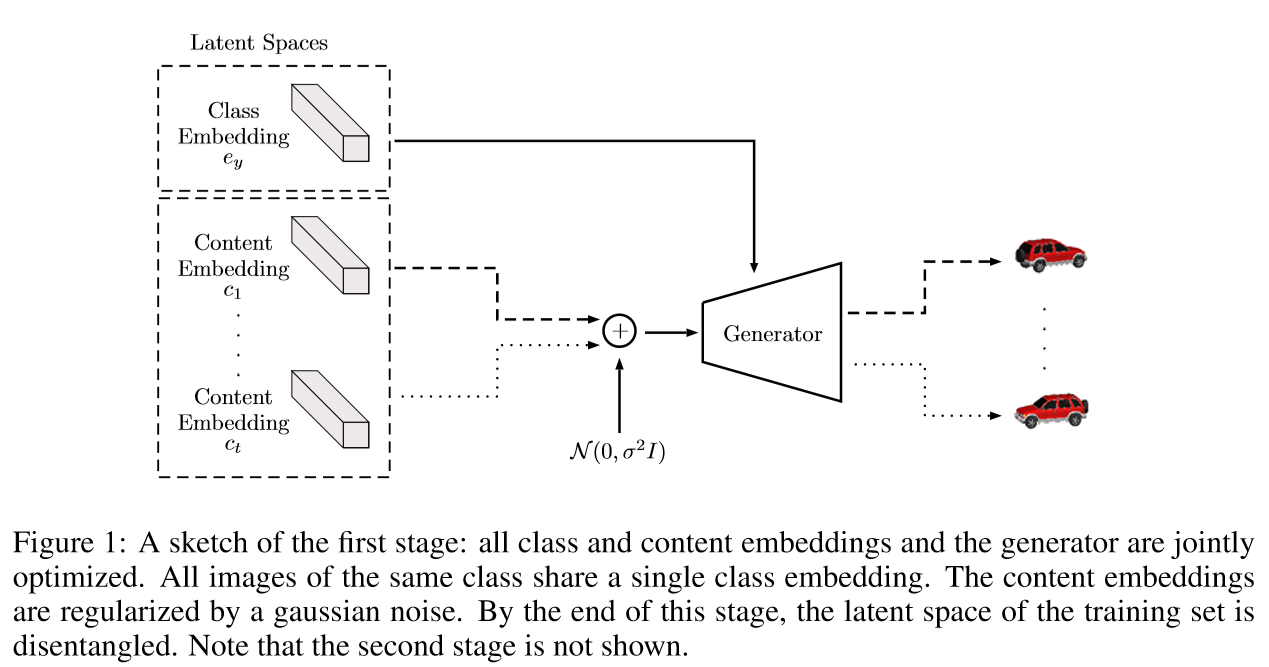
Amortization for one-shot inference
潜在优化在训练时对于学习解纠缠表示是很有效的,但在测试时观测到未知类的单个图像,如果进行潜在优化容易导致过拟合而导致纠缠,所以引入第二阶段去训练一个前馈的类和内容编码器,这个编码器能很好的推广到看不见的图像且减少了新样本的推断时间。则第二阶段的目标函数为,其中,是第一阶段学到的编码:
训练后,将一张图片的样式跟的内容融合可以表示为:
补充:由代码得到的框架图:

部分实验结果
数据集
Cars3D(类标签:汽车模型,内容标签:方位角和仰角);
SmallNorb(类标签:目标类别x照明x仰角,内容标签:方位角);
CelebA(类标签:身份,内容标签:其它无标签的面部属性,如头部姿势,表情);
KTH(类标签:身份,内容标签:其它无标签的面部属性,如骨架位置);
RaFD(类标签:面部标签,内容标签:其它无标签的面部属性);
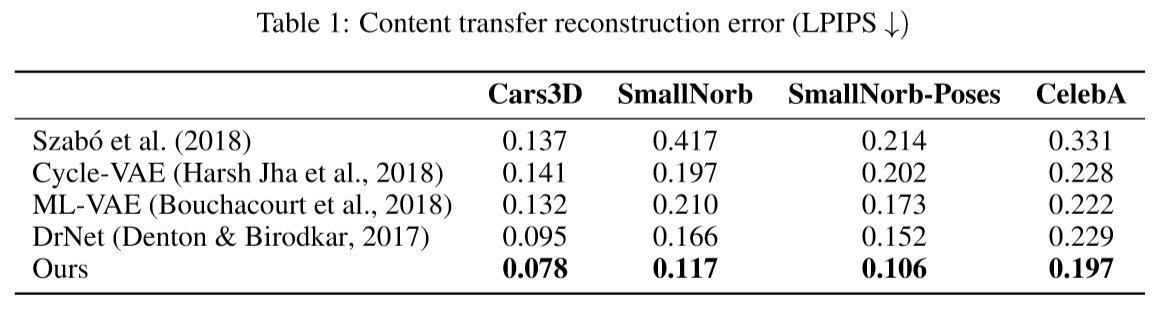
内容迁移实验
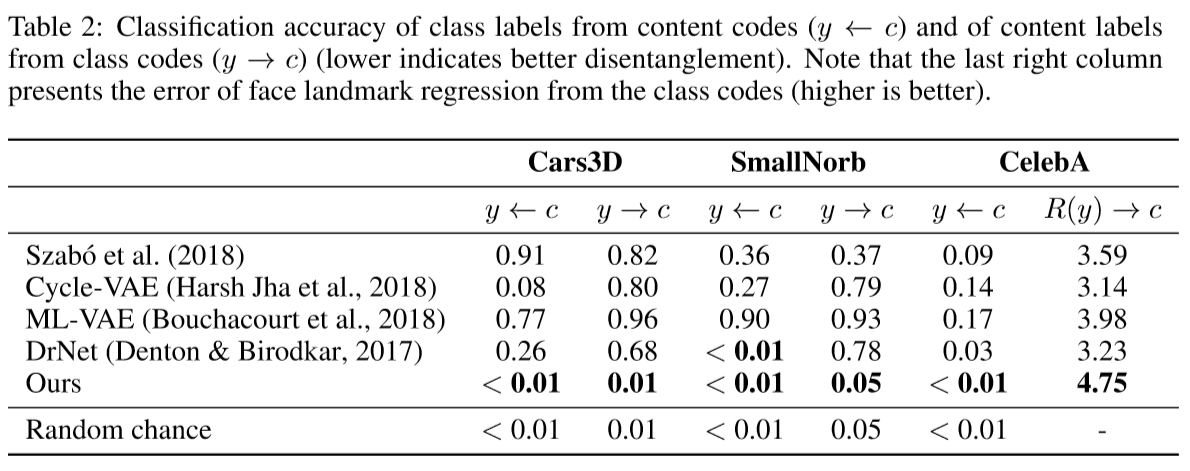
分类实验
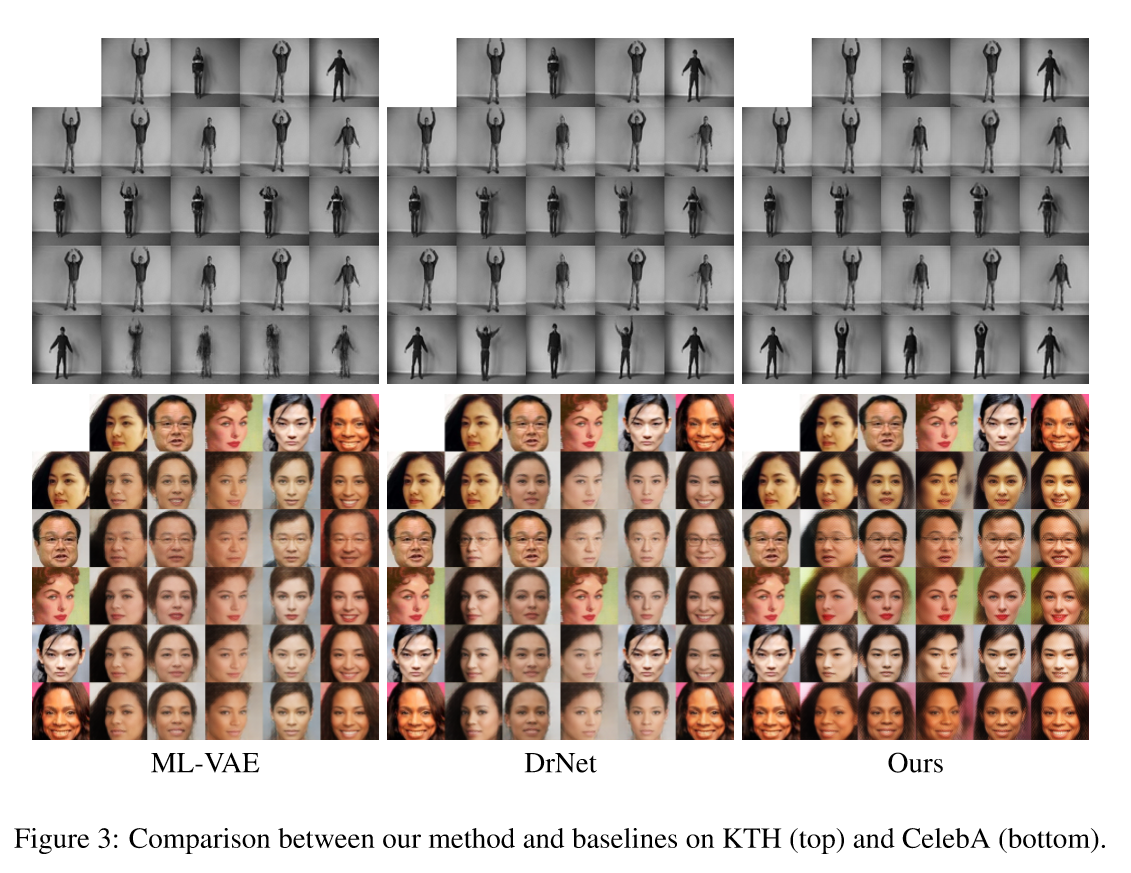
面部表情迁移实验
