动机
- 无监督学习在自然语言处理领域应用较广,如GPT、BERT等,而在计算机视觉领域应用较少,作者认为是两个领域处理的数据对应不同的信号空间,语言任务是离散的信号空间,词与词之间可以被认为是独立的词组,更方便去构成字典;而视觉任务的信号是连续、高维且无法被结构化的信号;
- 对比损失作为一种无监督学习的方法,可以认为是建立动态字典的过程,字典中的
key认为是从数据中进行采样然后被encoder表征,无监督学习是训练encoder做字典的搜寻:使被编码的query应该跟自己的key相匹配,而跟其它的应该不同; - 一般来说,希望建立一个足够大的且在训练过程中保持一致性的字典,因为更大的字典可以更好地对底层高维视觉空间进行采样,而字典中的
key应该被相同的或者相似的encoder表征以便于key与query的比较是一致的,但现有的方法使用对比损失不能兼顾这两者。
贡献
- 对于带对比损失的无监督学习方法,提出了动量对比(
MoCo)的无监督视觉表示学习方法; - 从对比学习作为字典查找的角度,构建了一个类似队列且具有滑动平均编码器的动态字典,以使得字典足够大且一致性较好;
MoCo学到的表示可以很好地应用到下游任务中,实验证明MoCo在很多视觉任务中能够大幅缩小无监督和有监督表征学习的差距。
本文的方法
对比损失
考虑一些已编码的query q和一系列编码样本(即key),假设q与匹配,则对比损失的目的是尽量使得q与之间的距离减少而使得与其它key之间的距离增大,本文使用点积计算相似度来作为对比损失函数,称为InfoNCE:
其中,是温度超参数,对比学习作为一种无监督方法的目标函数,目的是训练一个encoder网络表征query和key。一般来说,,相应的,都是一个编码器网络,二者可以参数相同,也可以部分共享参数,甚至完全不同。
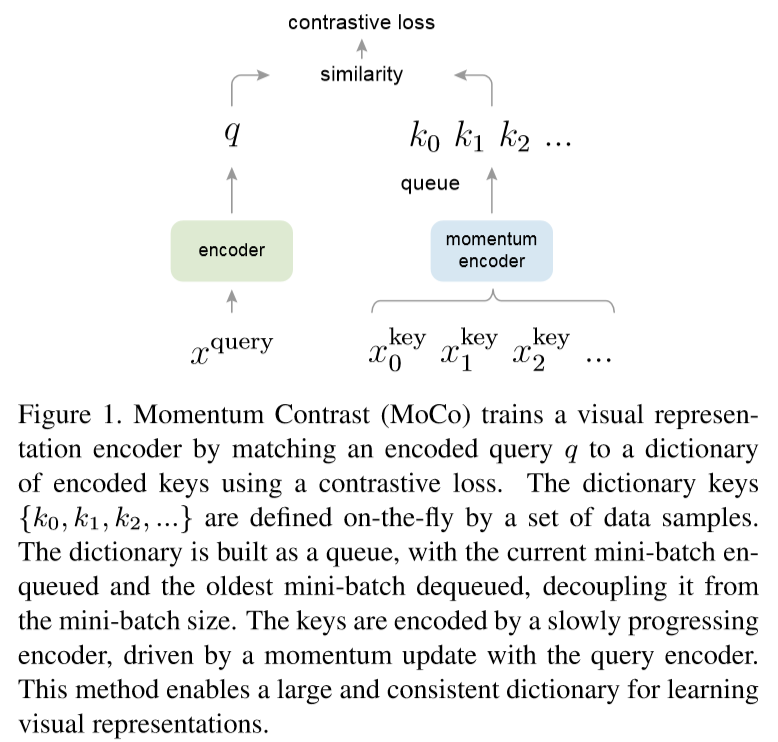
动量对比
对比学习可以认为是一种在高维连续输入上构建动态字典的方法,本文假设好的特征可以通过包含大量负样本集的大型字典学习到,并且在动态变化的过程中,字典中key的编码尽可能保持一致。
将字典作为一个数据样本队列
当前批次的编码特征进入队列,而最古老的编码特征出队列,既允许使用前面batch已经编码的key,也将字典的大小与batch的大小独立开来,作为一个超参数可以设置更大的字典。
动量更新
使用队列可以使得字典更大,但会导致反向传播时使用所有样本进行更新变得困难,一个解决方案是忽略梯度而复制作为,但这样效果很差,可能是由于快速改变encoder会减少key表征的一致性,所以提出动量更新的方法去更缓慢地更新:
是动量系数,其中是通过反向传播更新的,当m取较大的值时效果更好,说明缓慢更新的key encoder是使用队列的一个核心。
跟以往方法的对比
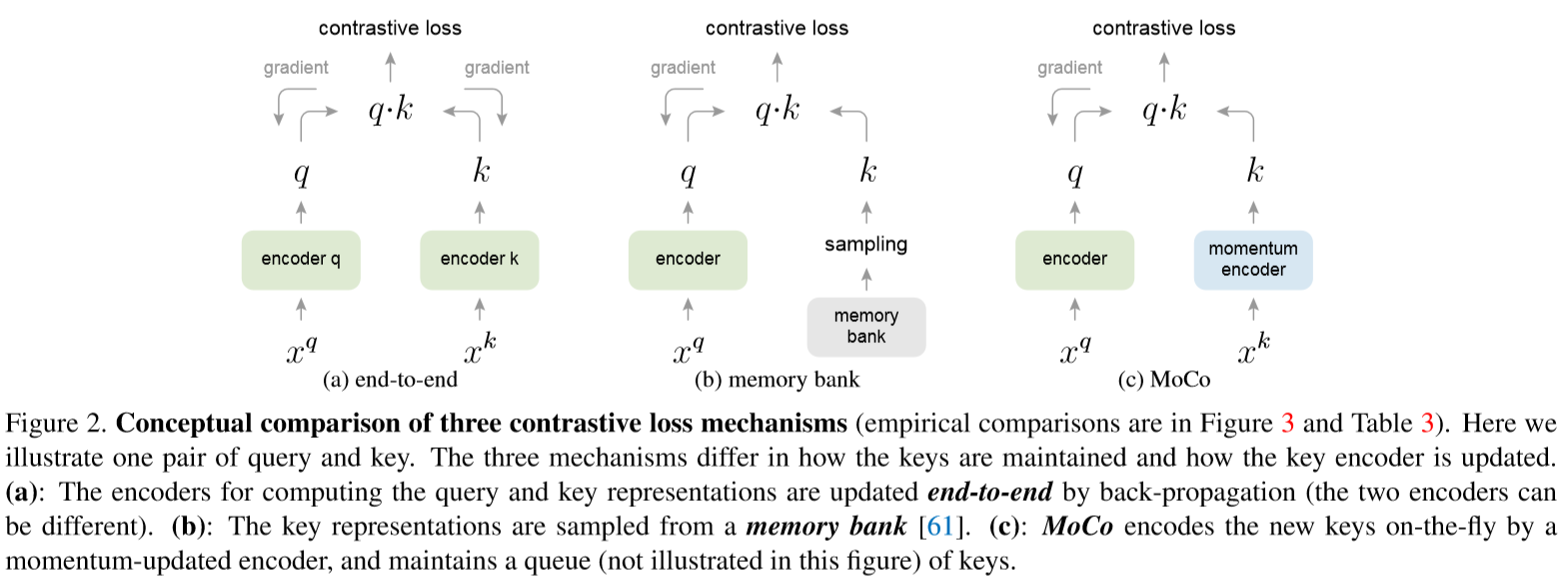
端到端反向传播
使用当前batch的样本作为字典,因此key的编码一致性能得到保证,但字典的大小跟batch的大小有关,受到显存大小限制。
memory bank 记忆库
由数据集中所有样本的表征组成,但每个batch是从记忆库中随机采样的,且没有反向传播的过程,它支持的字典更大,但在最后一次看到记忆库中的样本时,样本的表征是被更新的,所以样本的
key基本上是不同的编码器生成的,所以一致性较差。MoCo
即使用队列的形式来保证字典的大小,且使用基于滑动平均的动量编码器来保证一致性。
Pretext Task
本文的重点不在这部分,直接认为如果query和key来自同一图像,则将它们视为正对,否则视为负样本对。即对同一幅图像在随机数据增强下取两个随机视图,形成正对,query和key分别由编码器和进行编码。
本文方法的伪码

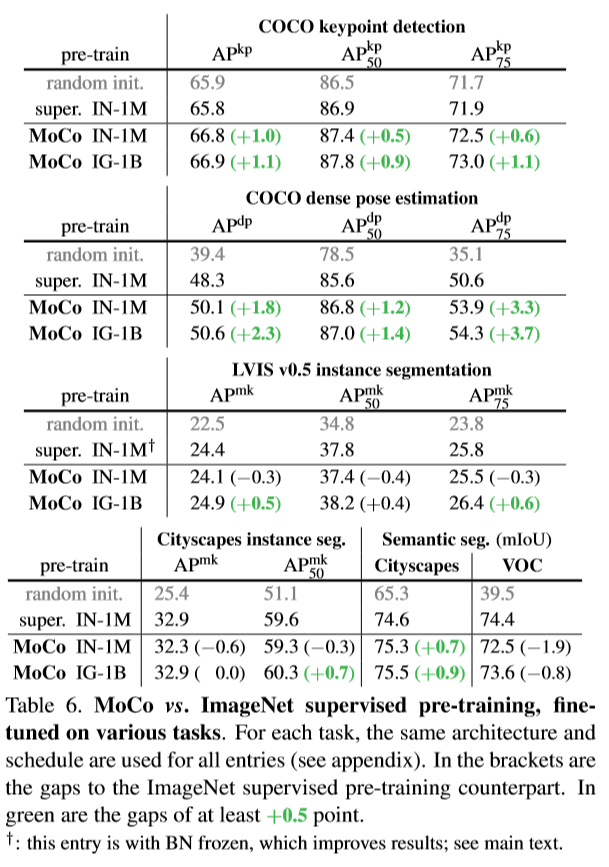
部分实验结果
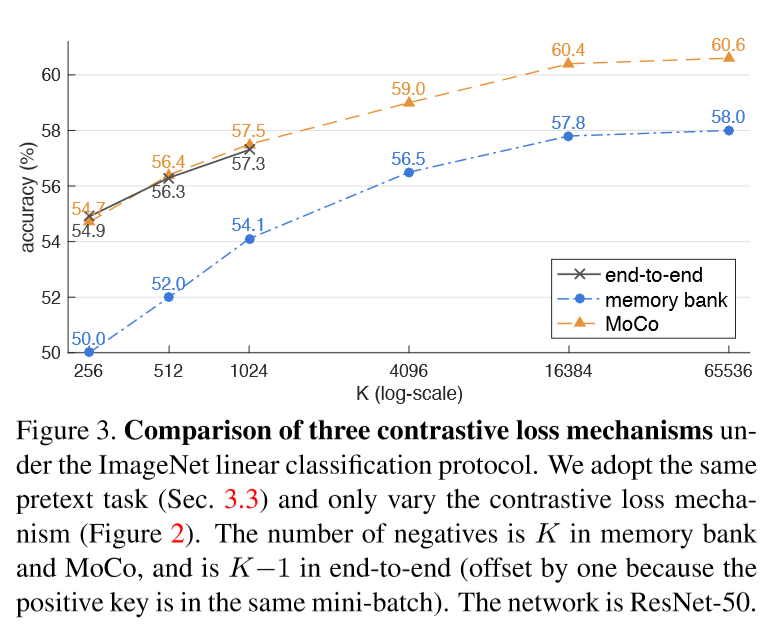
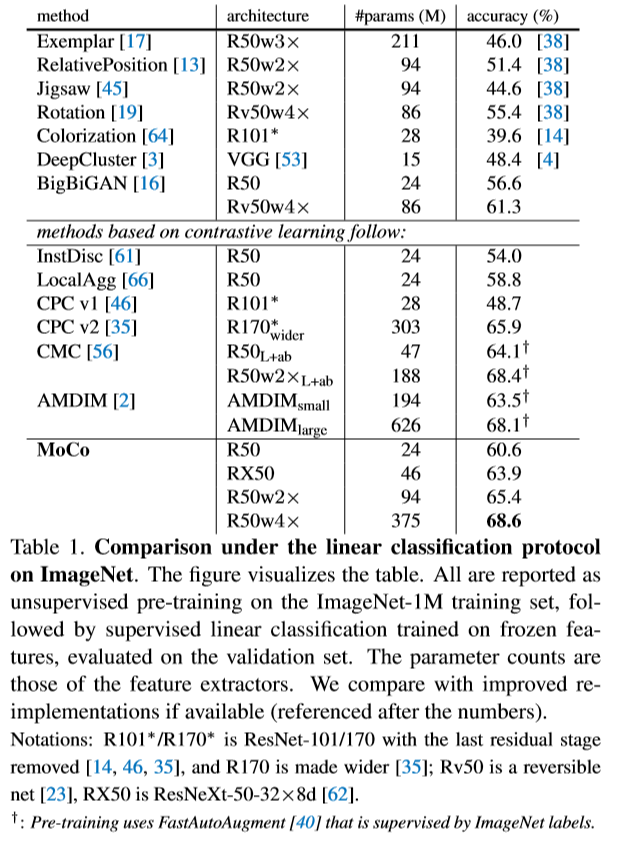
线性分类结果
即将训练好的Moco编码得到的特征作为有监督的标签去训练一个分类网络
特征迁移
用训练好的模型与其他在ImageNet训练好的模型做分割与检测实验,数据集是PASCAL VOC和COCO