
图像抠图介绍
通常而言,对于一张图像,需要求解出它的前景,背景及alpha matte,基于alpha通道则可以将前景与任意背景进行组合得到新的图像,因此alpha matte是一个与原图同大小的一个单通道图像,每个像素对应于原RGB图像相同位置像素的alpha值。
上式z为输入图像的像素位置,,和分别为像素z处的alpha估计,前景和背景。
为了降低求解难度,通过使用人工标记的三元图来提供更多约束,即将一副图像分成绝对前景(FG,对应于下图的白色)、绝对背景(BG,对应于下图的黑色)以及过渡区域(对应于下图的灰色),这样只需要求解过渡区域的像素对应的alpha值。即本质上是逐像素的前景区域的回归,认为FG的结构来源于两个方面:自适应的语义和细化边界,对应于上式中的和视图。

动机
- 现有的基于深度学习的抠图算法主要依靠高级语义特征(提供FG的种类等)和外观特征(纹理和边界细节)来改进alpha mattes的整体结构。
- 一方面,自然图像抠图是一个本质上的回归问题,不完全依赖于图像语义,这意味着深度网络提取的语义属性对图像结构的贡献是不相等的。另一方面,外观线索在保留复杂图像纹理的同时,也包含了FG之外的细节。然而,现有的抠图网络忽视了对这种层次特征的深层次挖掘和提炼。
- 所以,本文认为从cnn中提取的高级语义对alpha感知的贡献是不平等的,应该调和高级语义信息和低级外观线索,需要在组合前进行适当的过滤,以细化前景细节。
贡献
- 提出了一种端到端的分层注意力抠图网络(HAttMatting),该网络可以在不增加任何输入的情况下实现高质量的注意力抠图;
- 设计了一个分层注意机制,它可以聚合外观线索和高级金字塔特征,以产生细粒度的边界和自适应的语义;
- 采用了均方误差(MSE)、结构相似性(SSIM)和对抗损失等组成的混合损失来提高alpha感知,为文中的HAttMatting训练提供有效的指导。
以前的方法
- 大多方法为高级语义特征的提取设计复杂的网络,并融合来自输入图像或低层CNN特征的外观提示,然而它们的外观提示和高级语义都依赖于作为辅助和输入的三元图。
- 另一些方法则依靠分割来生成trimap,这在一定程度上降低了alpha mattes的精度。后期融合将分割网络的FG和BG权重图与初始CNN特征混合,以单个RGB图像作为输入,预测alpha mattes。然而,当语义分割遇到困难时,后期融合就会出现问题。
本文方法
思想
完整的对象FG应该由两部分组成:表示FG类别和配置文件的主体,位于过渡区域的纹理和边界细节;前者可以通过高级语义提出,而后者通常来自输入图像或低层次CNN特征,称为外观线索,两者结合可以得到alpha mattes。
本文认为高级语义特征和外观线索在结合前需要通过注意力机制等进行适当的处理。首先,自然图像抠图应该处理不同类型的FG对象,这意味着我们应该提取高级语义来处理FG信息,并适当地抑制它们,以降低它们对对象类的敏感性。其次,外观线索涉及到不必要的BG细节,需要在alpha mattes中去除。
基于以上分析,本文方法的核心思想是选择与抠图相适应的语义信息,并去除外观线索中多余的BG纹理,然后将它们聚合起来预测alpha mattes。
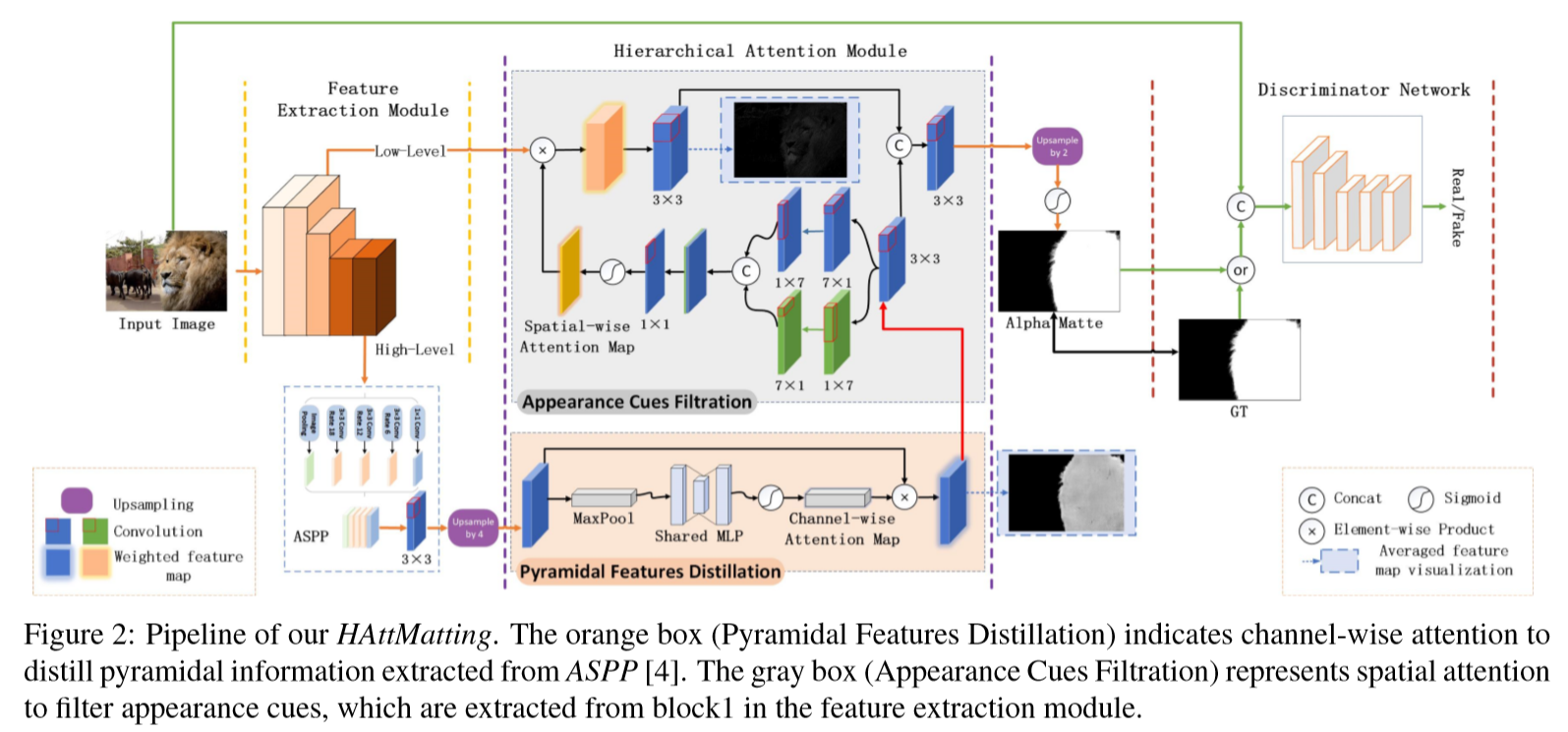
网络结构
输入的图像经过ResNeXt提取特征,将高层特征输入到ASPP模块,以获取多尺度语义特征,再基于通道注意力机制进行过滤,同时将低层特征作为外观线索,并基于空间注意力机制,同时去除FG外的图像纹理细节。此外,参照PatchGAN的鉴别器网络来提高alpha mattes的视觉质量。
Pyramidal features distillation
原因
ASSP提取的金字塔特征对FG结构回归的贡献不相等,因此对金字塔特征进行通道注意力,以提取自适应的语义属性。
步骤
对ASSP提得到的语义金字塔特征进行上采样,再利用pooling来泛化特征图,然后使用权值共享的MLP提取语义属性,最后使用一个sigmoid来计算通道方向上的注意力图,并将其与上采样的金字塔特征相乘来实现语义精馏。
优点
通道注意力机制可以选择适合于图像抠图的金字塔特征,并保留图像轮廓及类别属性等。
Appearance cues filtration
原因
图像抠图要求精确的FG边界,而高层的金字塔特征无法提供这样的纹理细节,因此需要用于生成alpha matte的外观线索,同时希望过滤BG内的外观线索。
步骤
低层特征作为外观线索输入该模块,同时利用过滤后的语义特征辅助进行空间注意力机制,过滤属于BG的外观线索,最后将过滤后的外观线索与过滤后的语义特征结合起来生成alpha matte。
优点
空间注意力机制可以过滤外观线索,这种分层注意力机制可以有效地关注低层的外观线索和高层的语义特征,它们的聚合可以产生细粒度的alpha mattes。
损失函数
本文结合均方误差(MSE)、结构相似度(SSIM)和对抗损失设计了一种混合损失来指导网络训练,分别负责像素级精度、结构一致性和视觉质量。
总的损失:
对抗损失:
像素损失:
结构化损失:
部分实验结果
Datasets:
Adobe Composition-1k:训练集由FG对象和相应的ground truth alpha mattes组成,将每个FG对象和MS COCO的BG对象合成得到输入图像,测试集则通过FG对象和PASCAL VOC2012的BG数据集合成
Distinctions-646:自行构建的数据集
Evaluation metrics:
绝对差之和(SAD),均方误差(MSE),梯度(Grad)和连通性(Conn),均越小越好

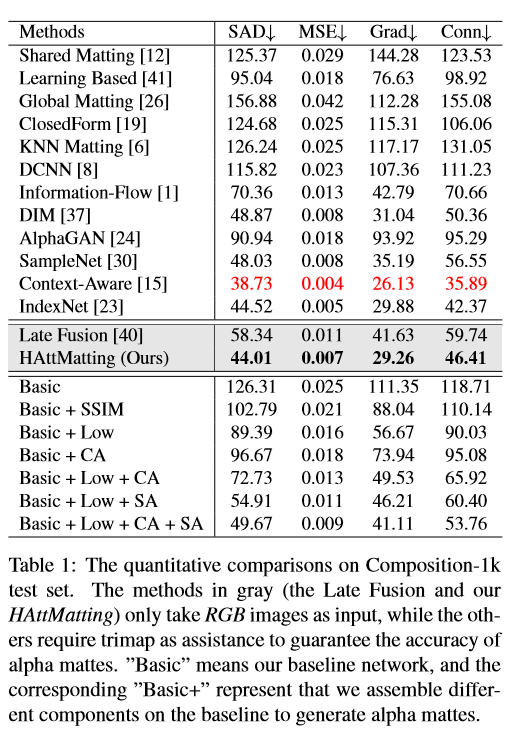
Late Fusion和HAttMatting只以RGB图像作为输入,其他方法需要trimap辅助来保证alpha mattes的准确性。CA表示通道注意力,SA表示空间注意力,Low表示低层特征,SSIM表示结构相似性损失。