
动机
基于类别标签的弱监督语义分割通常使用CAM作为基础方法,CAM通常只覆盖物品最具识别性的部分,并且当图像经过仿射变换做数据增强时,生成的CAM并不一致,如下图所示。
原因是强监督与弱监督的语义分割之间存在较大的监督差异,对于强监督语义分割,在数据增强阶段,像素级标签和输入图像经过相同的仿射变换,因而隐式的包含了这种等变性约束,而由类别标签生成的CAM时,类别标签没有变化,因而会影响CAM的训练过程,导致CAM无法很好的贴合目标边界;

贡献
- 本文提出一种自监督的等变注意力机制(SEAM),将等变正则化和像素相关模块(PCM)结合,来弥补监督信号之间的差异;
- Siamese网络结构的设计与等变交叉正则化(ECR)损失有效地耦合PCM和自我监督,产生的CAM有较少的过激活和欠激活区域;
- 实验表明,在仅使用图像级标签的情况下就能达到最先进的性能。
本文方法
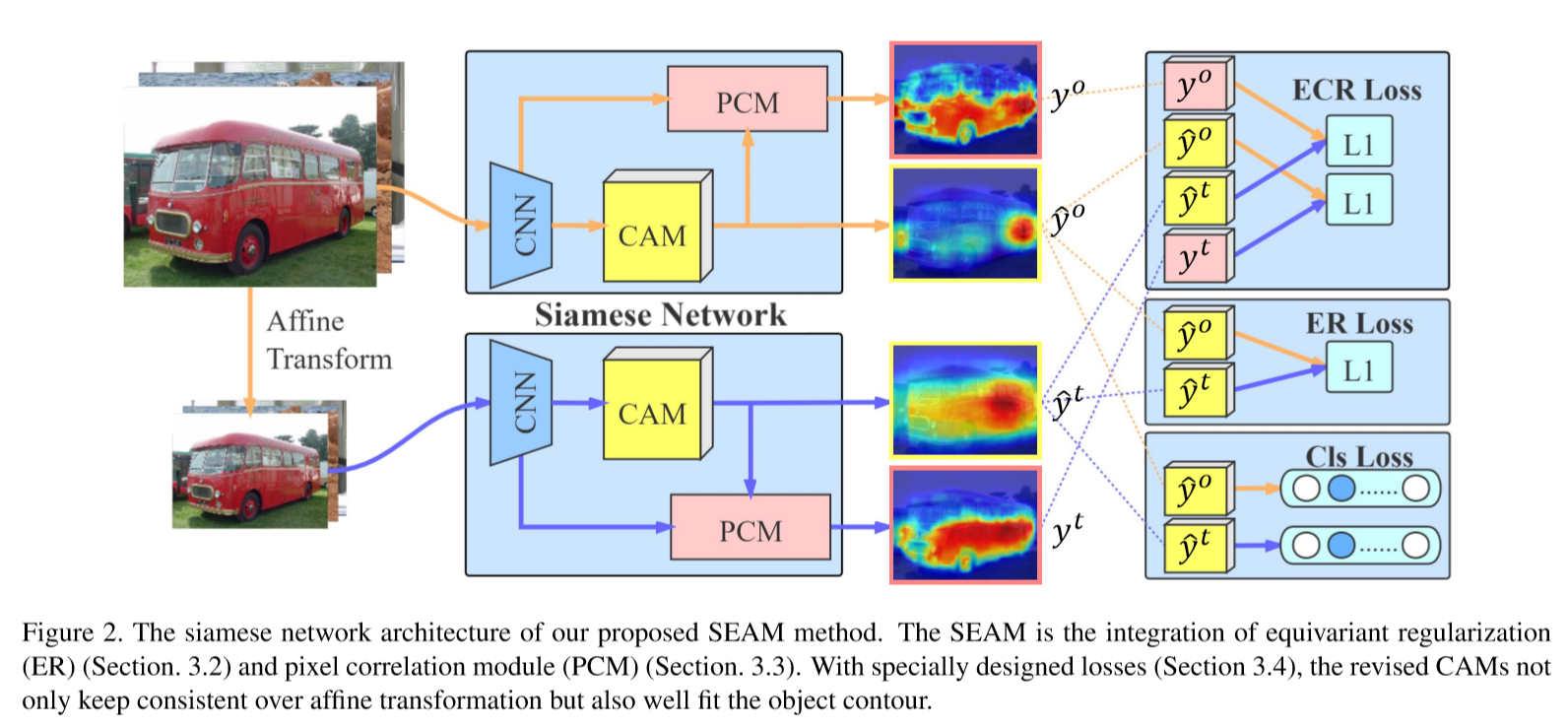
Equivariant Regularization
在全监督语义分割的数据增强期,对像素级标签采用与输入图像相同的仿射变换。它为网络引入了隐式等变约束。但是,考虑到WSSS只能访问图像级分类标签,这里没有隐含的约束。因此,本文提出以下等变正则化方法:
F表示这个网络,而A表示空间仿射变换,为了将正则化整合到原始分割网络中,本文将网络扩展为一个权值共享的孪生网络,其中一个分支将该变换应用于网络输出,另一个分支在网络前馈前,对图像进行相同的变换,正则化两个分支的输出激活图,以保证CAM的一致性。
Pixel Correlation Module
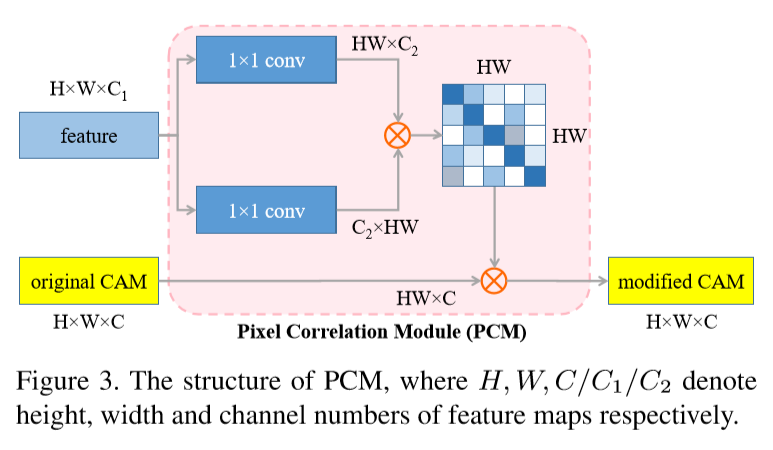
同时文中引入第二种约束进行自监督,通过PCM利用像素间的相似度去重建原始的类激活图。通过整合每个像素的底层特征来进一步利用上下文信息来细化原始CAM,本文使用归一化特征空间的内积来计算当前像素i和其他像素j之间的相似关系。
其中表示原始CAM,y表示修改后的CAM,中间部分利用余弦距离去评估像素间的特征相似度,最后输出的CAM是具有归一化相似性的原CAM的加权和。相比non-local网络,PCM去掉了残差连接等,目的在于使得那些仿射变换后的图像在弱监督训练时,仍然能够保证与原始图像拥有相同的信息。
损失函数
分类损失:对于原始图像的CAM和仿射变换后的图像的CAM经过一个全局平均池化层生成向量z,在网络训练中采用多标签soft margin损失,分类损失是为C - 1个前景对象类别
The equivariant regularization(ER) loss:
这里A(·)是一个仿射变换,它已经被应用到siamese网络的变换分支的输入图像上。
The equivariant cross regularization (ECR) loss:此外,为了进一步提高网络的等变学习能力,将浅层原始CAMs和特征输入PCM进行细化。直观的想法是在修正的CAM和之间引入等变正则化,但作者发现PCM的输出映射很快陷入局部最小值,图像中的所有像素都被预测为同一类,所以使用了一种等变交叉正则化损失。
部分实验结果
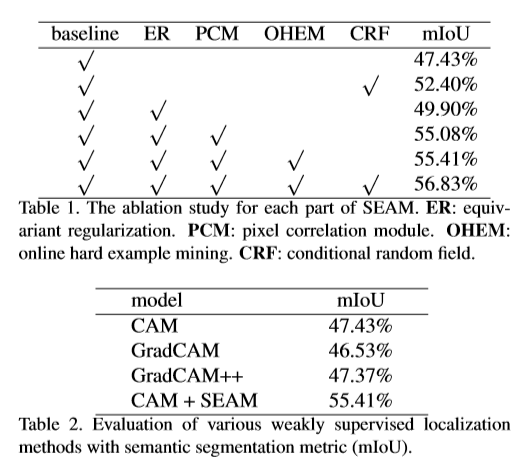
消融实验以及基于语义分割度量的各种弱监督定位方法的评价

可以看出本文提出的方法在图像覆盖上有一个更好的效果
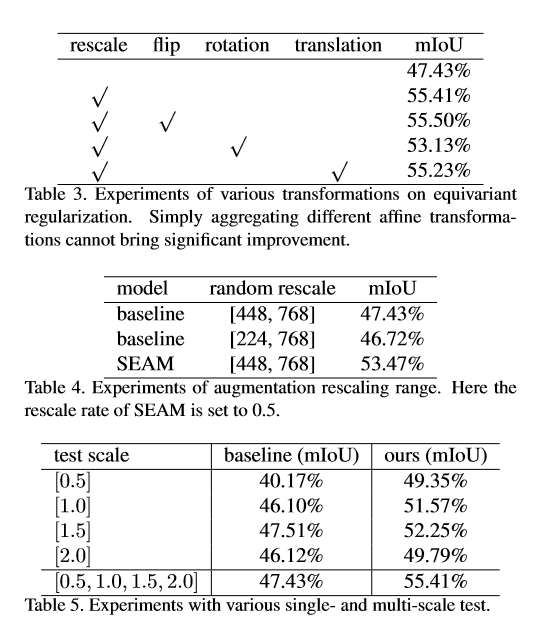
做数据增强时不同方法的网络保持等变一致性的能力
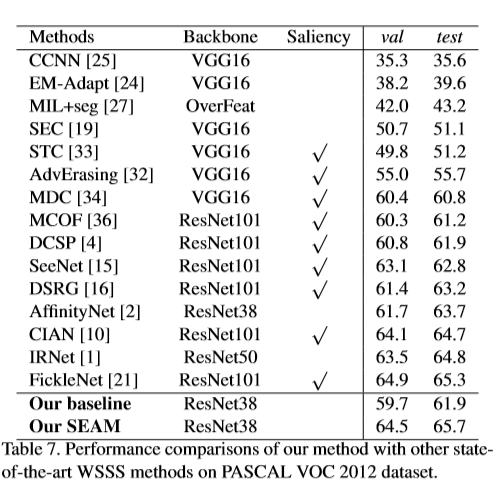
在PASCAL VOC 2012数据集上跟其它弱监督学习方法的比较
参考文献
自监督等变注意力机制